Spice Cloud v1.11: Spice Cayenne Reaches Beta, Apache DataFusion v51, DynamoDB Streams Improvements, & More
Releases
Spice Cloud Platform

Wyatt Wenzel
DevRel & Ops Leader at Spice AIJanuary 30, 2026
We're excited to announce Spice v1.11 is now available in Spice Cloud - a major release with over 43 new features, improvements, and fixes.
Spice v1.11 brings Spice Cayenne to Beta with 3x lower memory usage than DuckDB, significant performance upgrades across the entire compute stack: DataFusion v51, Apache Arrow v57.2, improved DynamoDB Streams, and an optimized caching acceleration mode.
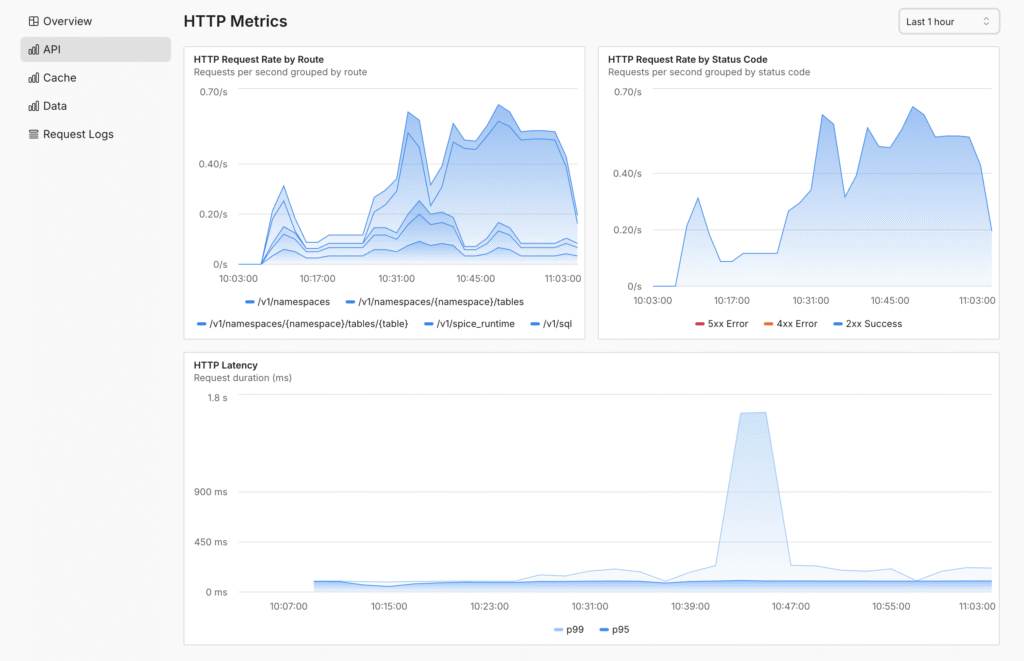
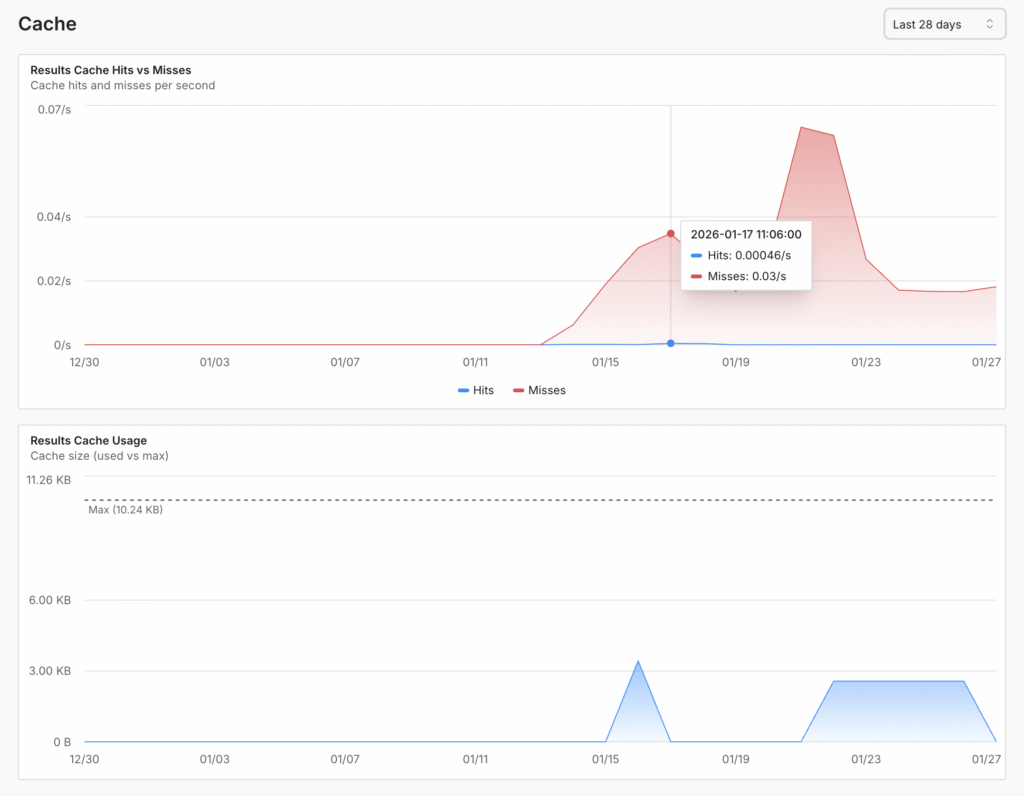
And, Spice Cloud monitoring has new real-time metrics and dashboards!
Monitor your Spice Cloud apps in production
New real-time dashboards give you complete visibility into API performance, data egress, and cache efficiency - so you can optimize costs and catch issues before they impact users.
New to Spice Cloud? Sign up and get $25 in free AI credits. Query databases, data lakes, and data warehouses, add instant RAG and AI analysis with zero-ETL. (US customers only).
Spice Cloud customers will automatically upgrade to v1.10 on deployment, while Spice.ai Enterprise customers can consume the Enterprise v1.9.0 image from the Spice AWS Marketplace listing.
Join the v1.11 Release Community Call

Connect with the Spice team and community for live demos of what's new in v1.11. Ask questions, share feedback, and get a preview of what's next.
Major v1.11 Features
Spice Cayenne Beta
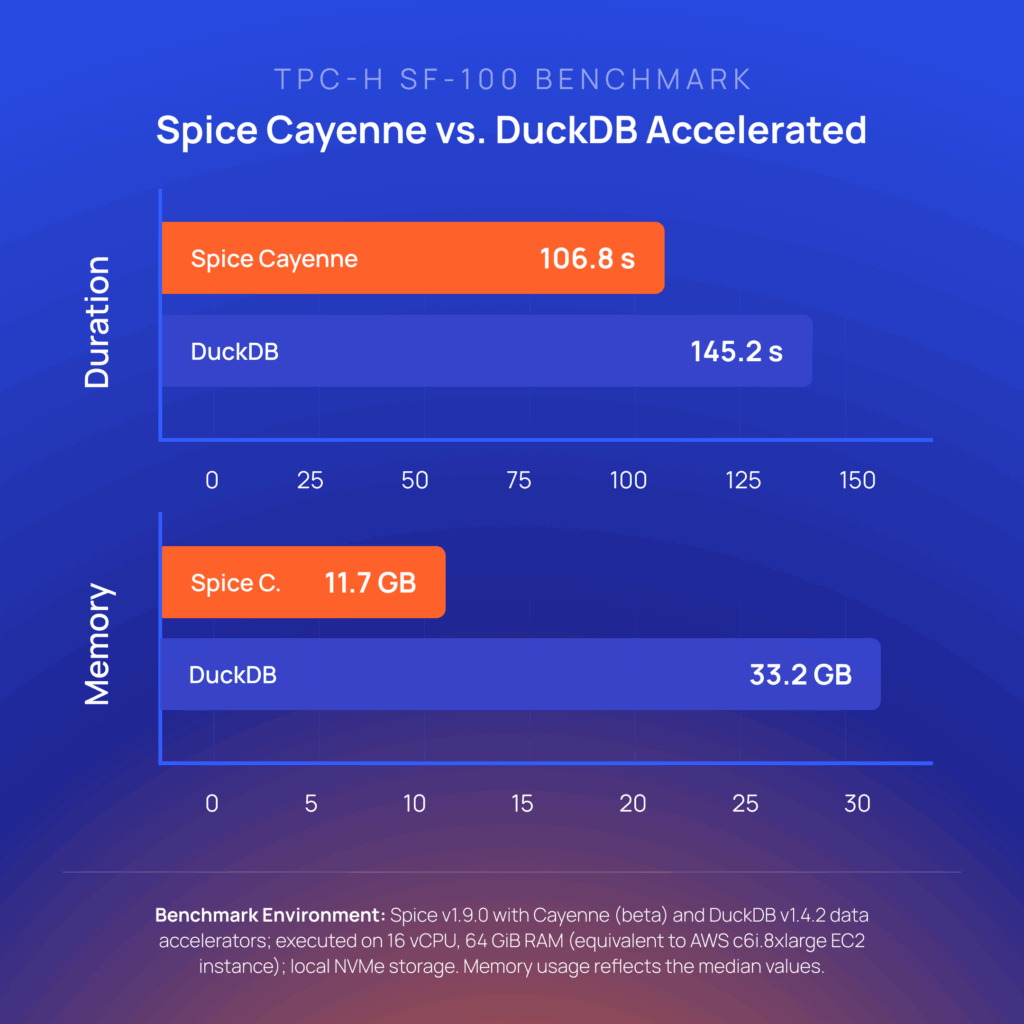
Spice Cayenne, the premier Spice data accelerator built on the Vortex columnar format, has been promoted to Beta. Cayenne delivers 1.4x faster queries than DuckDB with 3x lower memory usage on TPC-H SF100 benchmarks.
New Cayenne features in v1.11 include:
- Acceleration Snapshots: Point-in-time recovery for fast bootstrap and rollback capabilities
- Key-based Deletion Vectors: More efficient data management and faster delete operations
- S3 Express One Zone: Store Cayenne files in S3 Express One Zone for single-digit millisecond latency
- Primary Key On-Conflict Handling: New `
on_conflict` config for Cayenne tables with primary keys supports upsert or duplicate-ignore behavior
Apache DataFusion v51 Upgrade
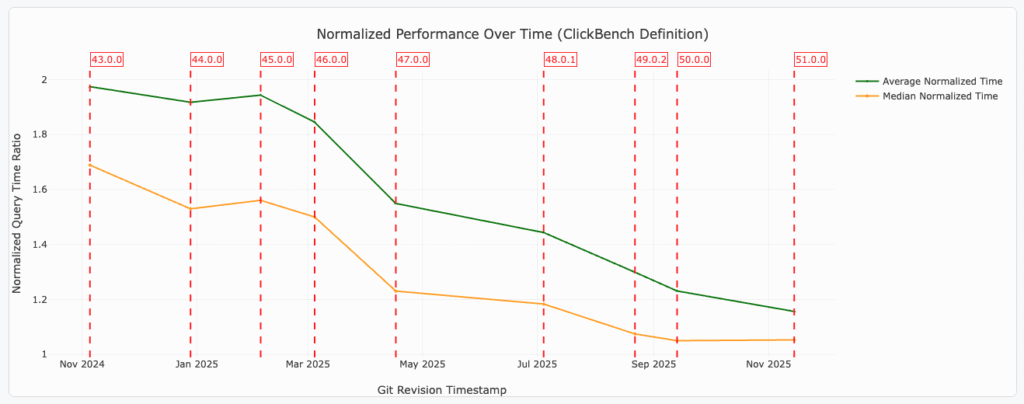
DataFusion v51 brings significant performance improvements and new SQL functionality:
Performance:
- Faster CASE expression evaluation with short-circuit optimization
- Better defaults for remote Parquet reads (avoids 2 I/O requests per file)
- 4x faster Parquet metadata parsing
New SQL features:
- Support for
|>syntax for inline transforms `DESCRIBE <query>`returns schema of any query without executing it- Named function arguments
`param => value`syntax for scalar, aggregate, and window functions - Decimal32/Decimal64 type support
Apache Arrow 57.2 Upgrade
Arrow 57.2 delivers major performance improvements:
- 4x faster Parquet metadata parsing with rewritten thrift metadata parser
- Parquet Variant Support (Experimental): Read/write support for semi-structured data
- Parquet Geometry Support: Read/write for
`GEOMETRY`and`GEOGRAPHY`types - New `arrow-avro` Crate: Efficient conversion between Apache Avro and Arrow with projection pushdown
DynamoDB Connector & DynamoDB Streams Improvements

DynamoDB Streams are now more reliable and flexible with JSON nesting support and improved batch deletion handling.
Caching Acceleration Mode Improvements

Major performance optimizations and reliability fixes for caching acceleration mode deliver sub-millisecond cached queries with faster response times on cache misses.
Performance:
- Non-blocking cache writes: Cache misses no longer block query responses; data writes asynchronously
- Batch cache writes: Multiple entries written in batches for better throughput
Reliability:
- Stale-While-Revalidate (SWR) behavior: Refreshes only the entries that were accessed instead of refreshing all stale rows
- Deduplicated refresh requests: Prevents redundant source queries
- Fixed cache hit detection: Queries now correctly detect cached data
Additional Features
Prepared Statements: Spice now supports prepared statements, enabling parameterized queries that improve performance and security by preventing SQL injection attacks with full SDK support across the Go, Rust, .NET, Java, JavaScript, and Python clients.
iceberg-rust v0.8.0: v0.8.0 brings support for Iceberg V3 table metadata format, INSERT INTO for partitioned tables, and more.
Acceleration Snapshots Improvements: Additions in v1.11 include flexible triggers based on time intervals or batch counts, automatic compaction to reduce storage overhead, and better creation policies that only create snapshot when data changes.
- NFS: Query data on Unix/Linux NFS exports
- ScyllaDB: Query the high-performance NoSQL database via CQL.
Google LLM Support: Spice now supports Google embedding and chat models via the Google AI provider
URL Tables: Query data directly via URL in SQL from S3, Azure Blob Storage, and HTTP/HTTPS.
Hash Indexing for Arrow Acceleration (experimental): Arrow-based accelerations now support opt-in hash indexing for faster point lookups on equality predicates.
From the Blog: How we Use Apache DataFusion at Spice AI

A technical deep-dive on how Spice uses and extends Apache DataFusion with custom table providers, optimizer rules, and UDFs to power federated SQL, search, and AI inference.
From the Blog: Real-Time Control Plane Acceleration with DynamoDB Streams

Learn how to stream DynamoDB data to thousands of nodes with sub-second latency using a two-tier architecture with DynamoDB Streams and Spice acceleration.
New Recipe in the Spice Cookbook: ScyllaDB Connector

Learn how to connect Spice to ScyllaDB for sub-second federated queries.
As always, we'd love your feedback! Join us on Slack to connect directly with the team and other Spice users.
To try v1.11 on your own workloads, start with SQL federation and acceleration and the data lake accelerator, or get a demo.
Explore more Spice resources
Tutorials, docs, and blog posts to help you go deeper with Spice.
A Developer’s Guide to Understanding Spice.ai
This guide helps developers build a mental model of why, how, and where to use Spice.

Real-Time Control Plane Acceleration with DynamoDB Streams
How to sync DynamoDB data to thousands of nodes with sub-second latency using a two-tier architecture with DynamoDB Streams and Spice acceleration.

How we use Apache DataFusion at Spice AI
Why we chose to build on DataFusion and how we extended it with custom TableProviders, optimizer rules, and UDFs for federated SQL

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer