Operationalizing Amazon S3 for AI: From Data Lake to AI-Ready Platform in Minutes
Search
Spice AI Team
Editorial Team at Spice AIFebruary 3, 2026
TL;DR
Amazon S3 has evolved into one of the most flexible and powerful systems of record, but leveraging it for real-time AI workloads requires significant distributed systems work to stitch together applications, databases, vector stores, and caches.
Spice handles ingestion, federation, acceleration, caching, and query execution, so teams can build AI applications and agents directly on S3 without that distributed systems complexity.
This post walks through a real-world example of using Spice to transform Amazon S3 from a passive object store into a low-latency, AI-ready execution layer.
From storage to system of record
Amazon S3 is durable, predictable, and cost-effective at massive scale. Its API has become the storage standard, making it one of the most portable foundations in the modern data stack.
But S3 wasn't designed for serving low-latency, operational workloads. To serve application queries, teams generally copy data into databases, search engines, and caches.
However, recently, AWS has extended S3 with primitives that can make it the backbone of AI workloads:
- S3 Tables bring managed Apache Iceberg tables directly into S3. Structured, tabular data that traditionally lived in databases or data warehouses can be queried with the simplicity of the S3 storage layer.
- S3 Vectors is purpose-built vector storage designed for embeddings at petabyte scale that can power search and RAG, grounding foundation models with proprietary data, enabling semantic search that understands meaning rather than just matching keywords.
These foundational capabilities can change what's possible when you're building AI applications. They are, however, still only storage primitives that don't solve all of the distributed systems complexity you end up facing at scale: ingestion, federation, caching, sharding, partitioning, query optimization, re-ranking, observability, and more. Infrastructure complexity compounds quickly.
Even a nominally straight-forward Q&A application needs to ingest structured data (questions, answers, metadata) and unstructured data (long-form text), vectorize the data to produce embeddings (for semantic search) and keyword indexes (for exact matches), and provide high-quality context for LLM inference (for analysis and generation). To serve these workloads, you're still required to build and operate application-layer distributed systems code to deliver the system at scale.
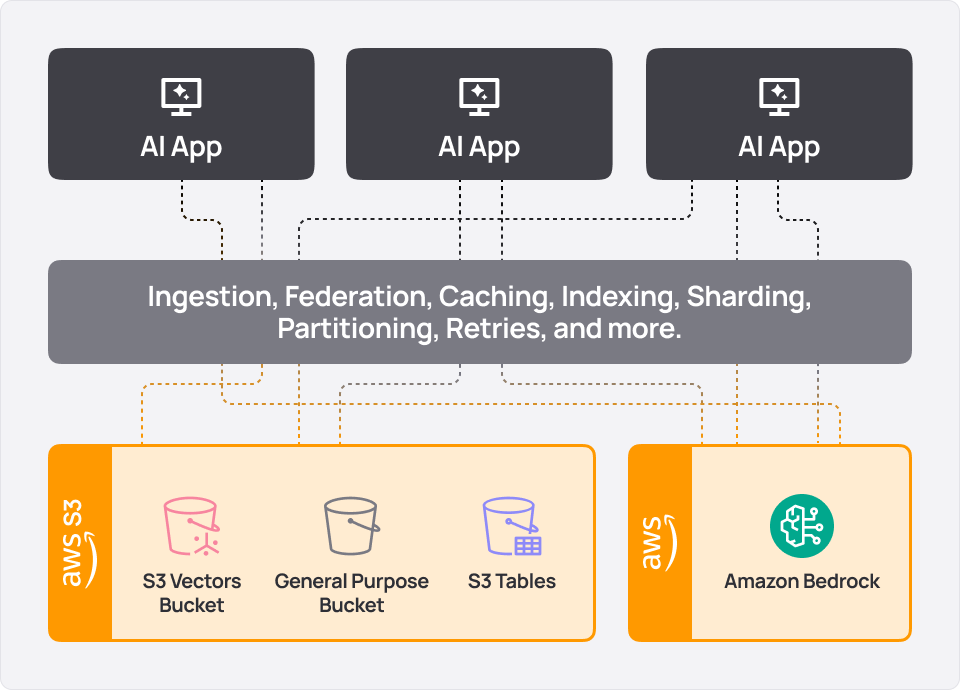
The missing piece is a runtime that turns S3 into an operational, AI-ready system that handles query execution, data lake acceleration, and coordination across structured data, vectors, and real-time sources.
Spice AI: The operational layer for S3
Spice integrates your applications and your data infrastructure - S3, databases, data warehouses, unstructured stores - and handles the distributed systems complexity for you. By unifying SQL query federation and acceleration, search and retrieval, and LLM inference into a single, deploy-anywhere runtime, Spice makes it possible to serve data and AI-powered experiences directly from S3 - securely, at low latency, and without sacrificing the simplicity and economics of object storage. Spice is built in Rust with modern open-source technologies including Apache DataFusion, Apache Arrow, Apache Iceberg, and Vortex.
Here are four specific challenges Spice addresses for these AI-driven workloads:
Federate data where it lives
Spice executes SQL queries across databases, data lakes, and APIs with zero ETL. For example, you can write a single query that joins live data in S3 Tables and Aurora or combines historical logs in S3 with real-time operational data from DynamoDB.
Spice has native data connectors across 35+ data sources: Everything from S3, PostgreSQL, MySQL, Snowflake, Databricks, DynamoDB, and more.
Accelerate data for latency-sensitive AI apps
Spice implements tiered caching and acceleration using embedded databases including DuckDB, SQLite, and Vortex-based Spice Cayenne. Frequently accessed data is materialized locally for millisecond queries.
This is critical for AI workloads: applications and agents making hundreds of queries per second can't wait for S3 round trips on every request.
Hybrid search across structured and unstructured data
Search is a foundational primitive for AI applications - RAG and agents rely on it to build high-quality, relevant context. But in traditional architectures, search lives in separate systems (Elasticsearch, Pinecone, etc.) with their own APIs, integrations, and copies of data.
Spice takes an opinionated stance: search should use the same SQL interface as query, with indexes built off the same copy of data.
Spice combines BM25 full-text search with vector similarity search and native re-ranking, enabling developers to execute hybrid search (vector and full-text search) from a single SQL query. Spice does the work to build partitioned data indexes, manage metadata for filtering, and parallelizes cross-index scatter-gather queries.
Serve AI models
When you want to pipe query and search results into an LLM for analysis, classification, or generation, Spice provides built-in SQL functions for inference to models hosted on Bedrock, OpenAI, or self-hosted local models with full GPU-acceleration. Unlike alternative solutions, you don't need to wire external API calls, orchestration code, or copy data between systems.
You get S3's scale and cost efficiency without the distributed systems complexity in your application layer.
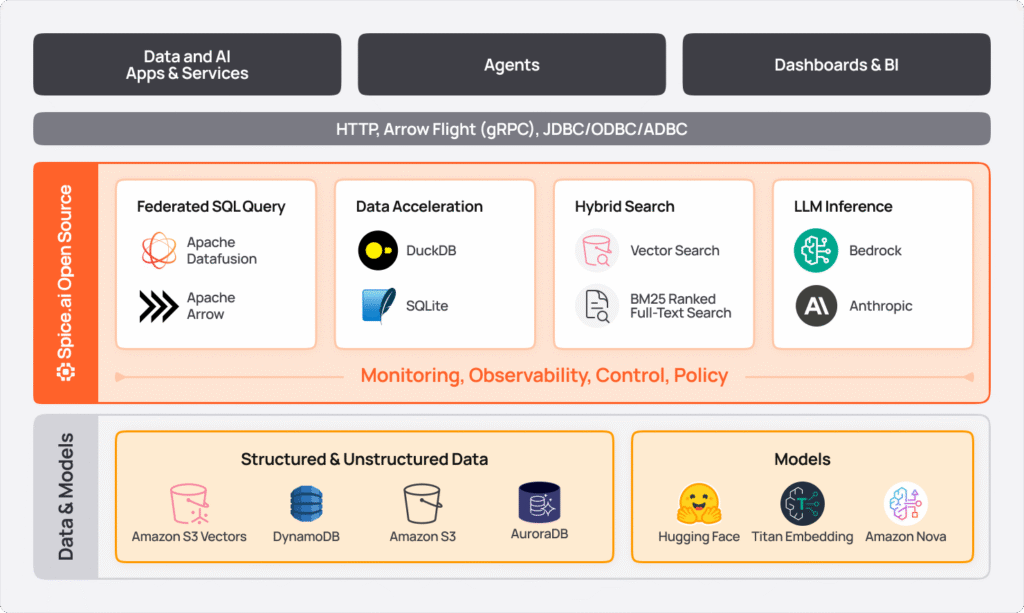
Building an AI-driven search application with Spice and S3
Let's take this out of the abstract and into a real-world scenario. We're going to progressively improve the search experience for Apache Answer, the open-source Stack Overflow-style Q&A application.
By the end of this walk-though, we'll have:
- Real-time ingestion from Kafka streaming into S3 Tables (structured data) and S3 Vectors (embeddings) so that queries and searches are real-time and accurate
- Federated queries that join S3 data with live data in Aurora and DynamoDB with zero ETL
- Hybrid search combining BM25 keyword matching with semantic vector search, re-ranked with Reciprocal Rank Fusion (RRF)
- Sub-50ms query latency with built-in caching using DuckDB and the Spice Cayenne acceleration engine.
- AI analysis where search results are piped directly into LLMs via SQL for classification, summarization, and generation
The entire implementation is less than 100 lines of declarative YAML configuration - eliminating custom application code, orchestration, and the need to copy data.
This architecture is inspired by Spice AI's Founder and CEO, Luke Kim's Talk at re:Invent 2025. You can watch the full end-to-end demo in under 10 minutes here:
The baseline
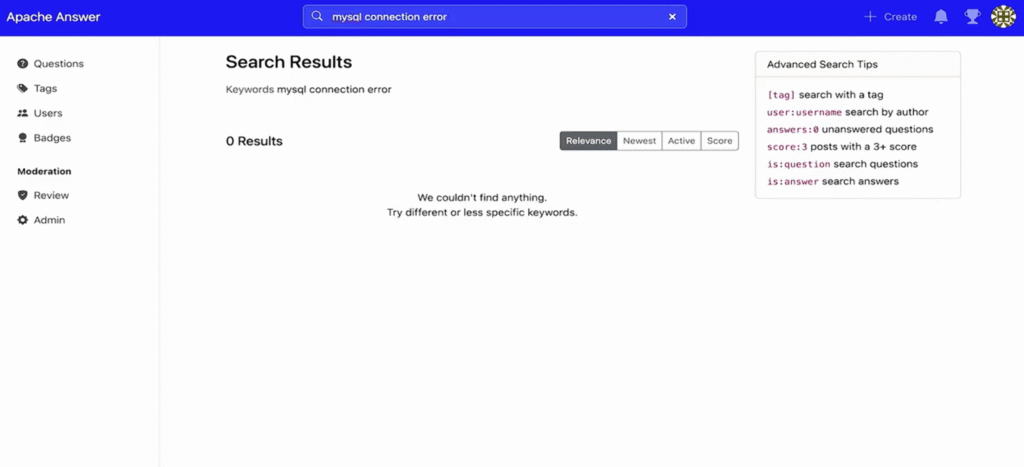
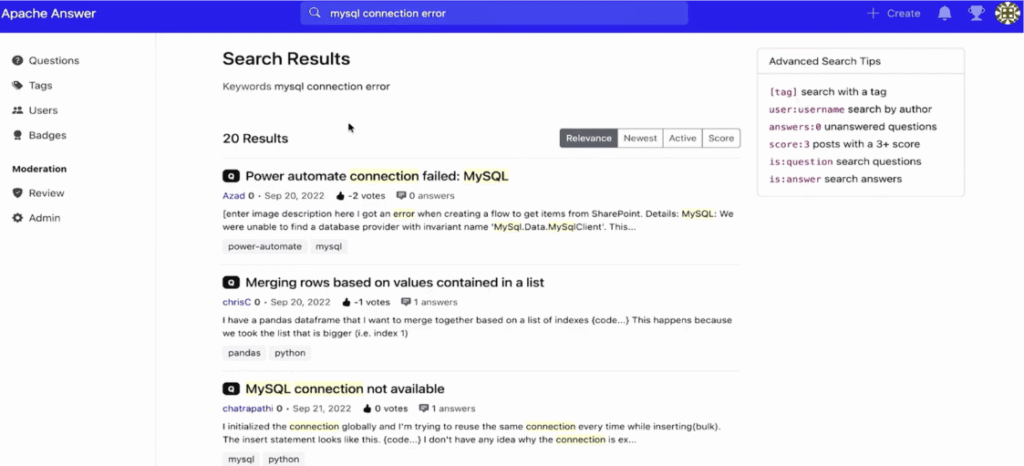
Let's start with the Apache Answer default and often the baseline for applications - good, old-fashioned string matching in PostgreSQL. When you search in Apache Answer for something like "MySQL connection error", you're waiting several seconds for 20,000 results - most of which are completely irrelevant. Sometimes the query just times out and returns nothing at all. This is a common outcome when your search is just matching keywords in a database with no understanding of semantic meaning or ability to distinguish between a question about MySQL connection errors, and a random post that happens to mention those words in passing.
Let's see how we can improve this.
The architecture
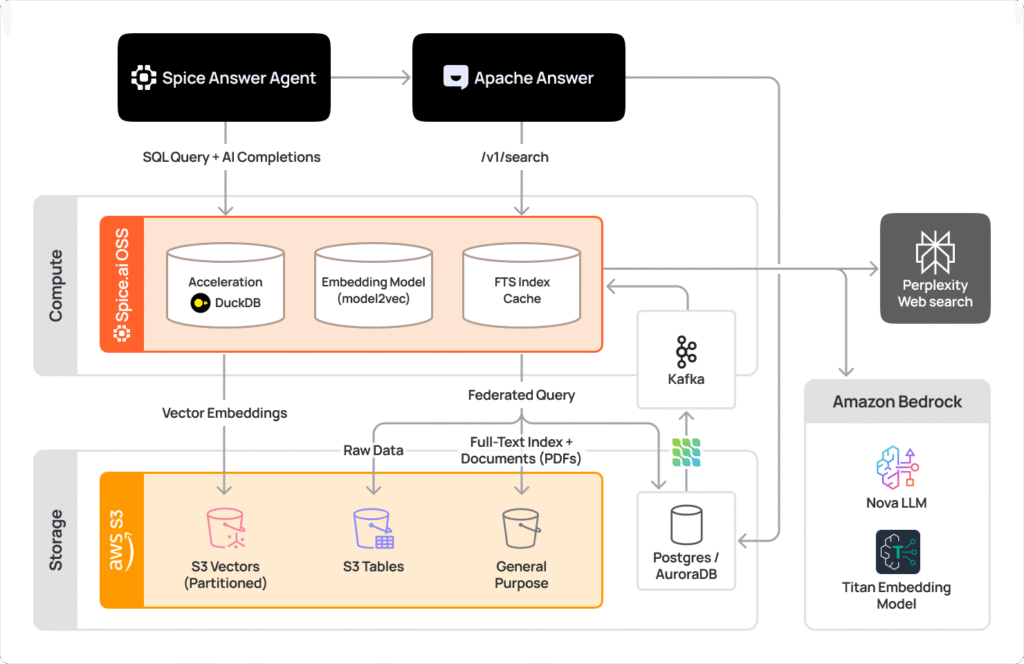
First, to enable real-time indexing, questions and answers are streamed via Debezium CDC through Kafka. Spice ingests that stream and simultaneously indexes the content for BM25 full-text search, generates vector embeddings using Amazon Titan, and materialized data locally in DuckDB.
Structured data (e.g. question IDs, timestamps, tags) is then written to S3 Tables where it's queryable as Iceberg tables. Embeddings are stored in S3 Vectors, automatically partitioned by date into separate indexes with filterable metadata. When a user searches, Apache Answer queries Spice with SQL, so no new API integration is required. Spice serves queries from the local acceleration, scatter-gather queries S3 Vectors across multiple partitioned indexes, combines full-text and vector results, and returns a re-ranked result set.
Step 1: Configure Spice
Here's the configuration for everything just described in a single YAML file (what we call a Spicepod).
Historic questions are stored in an S3 bucket with DuckDB acceleration, and new records are incrementally added as they arrive:
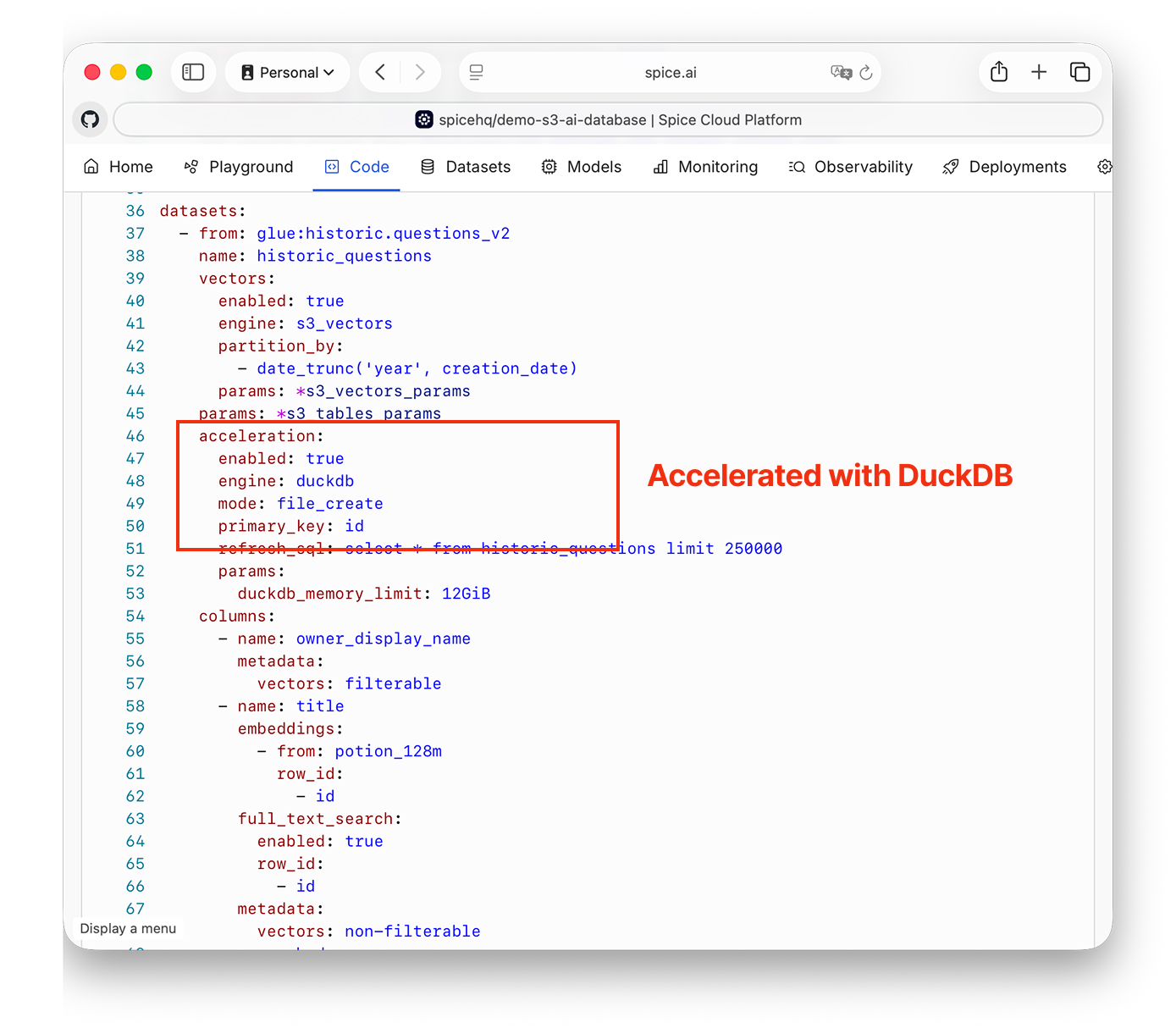
Spice's AWS Glue catalog connector sets up S3 Tables for the structured data:
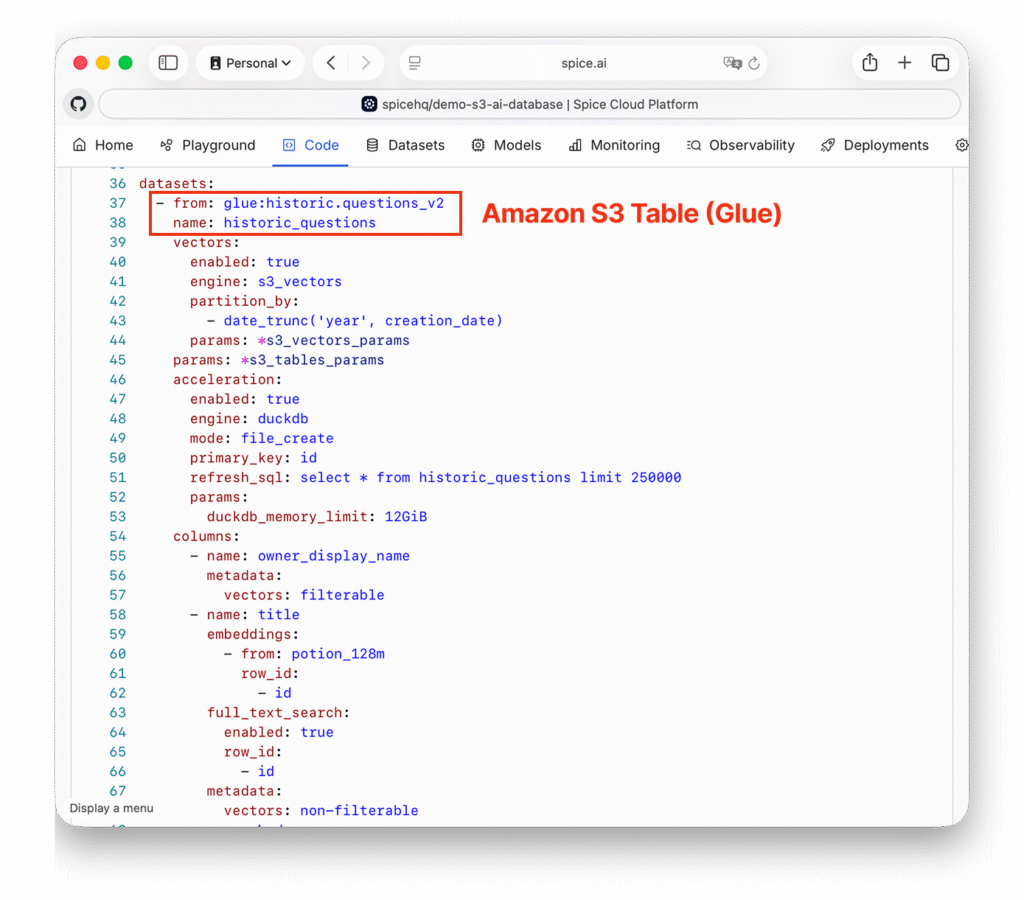
S3 Vectors is used as the vector search engine with the answer text vectorized with the Bedrock hosted Amazon Titan model. The partition_by setting ensures data is striped across multiple indexes, and ingestion and time-based queries are incredibly fast. Metadata fields get pushed down into S3 Vectors, so users can filter by tags or date ranges without scanning every vector:
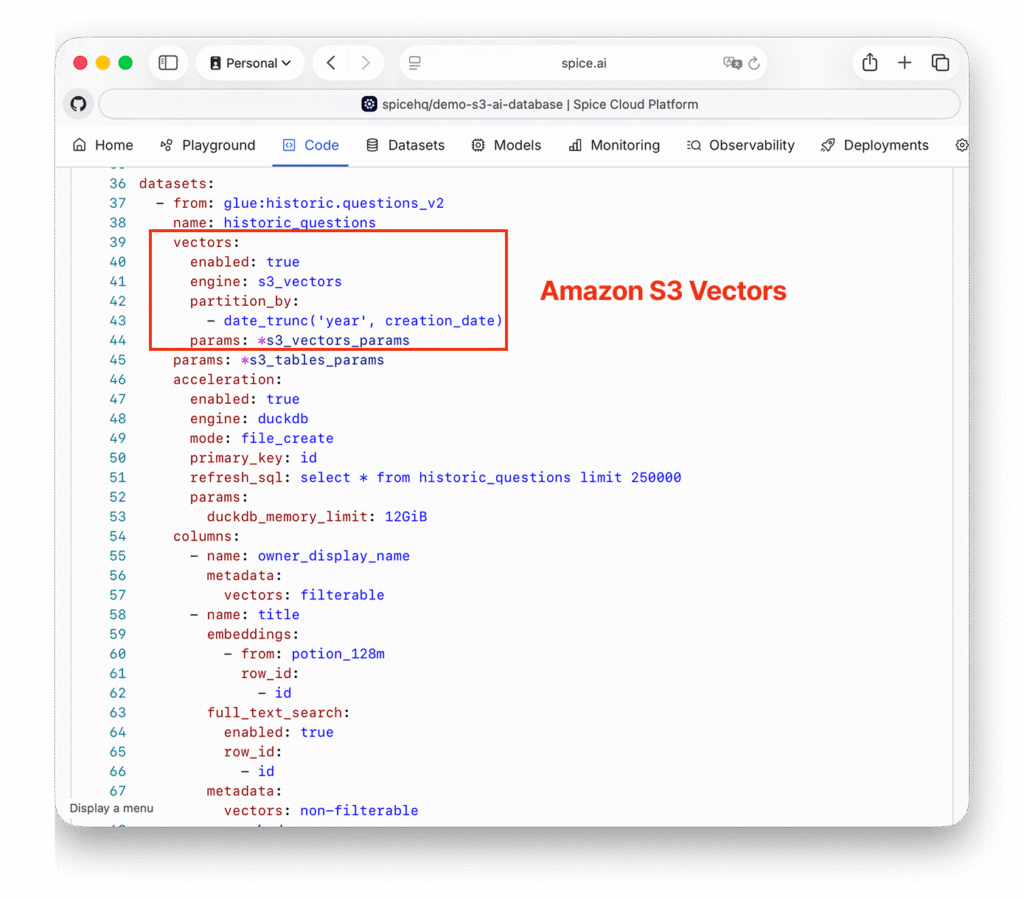
The BM25 search index configuration is even simpler; you just specify which columns to index for full-text search:
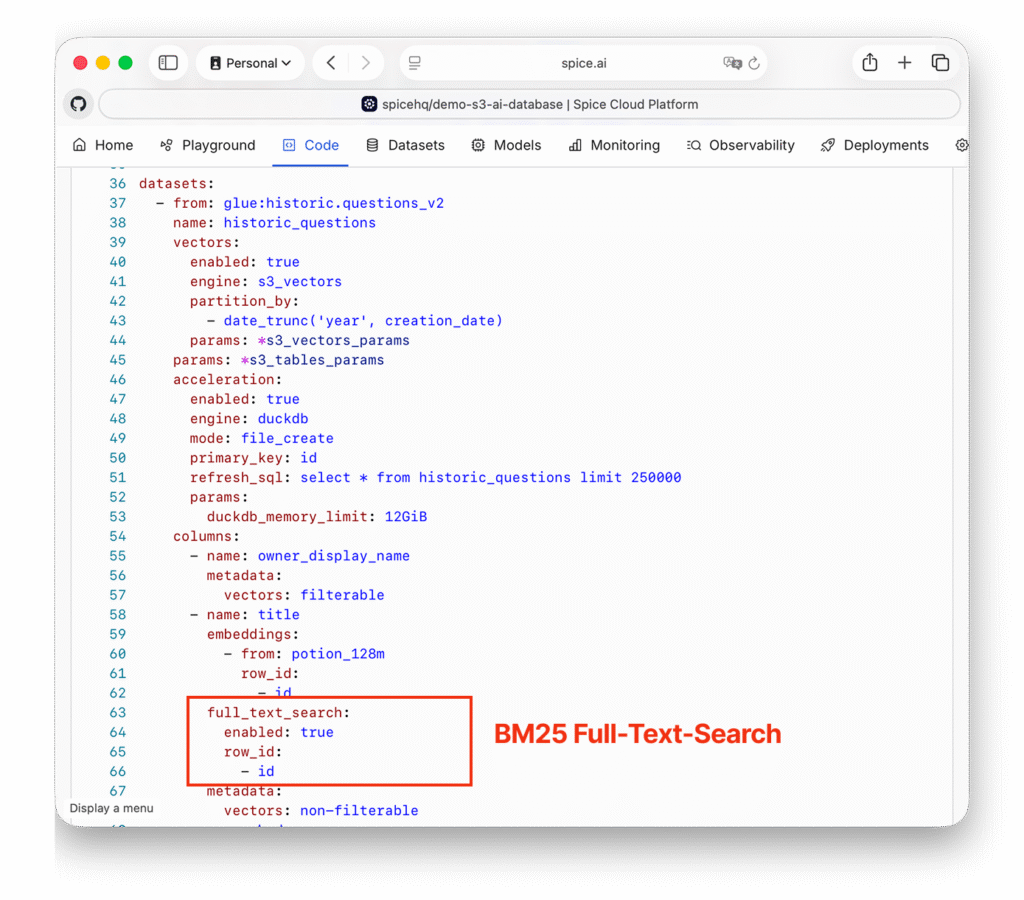
And finally, we're configuring Bedrock models so query and search results can be analyzed directly from SQL queries:
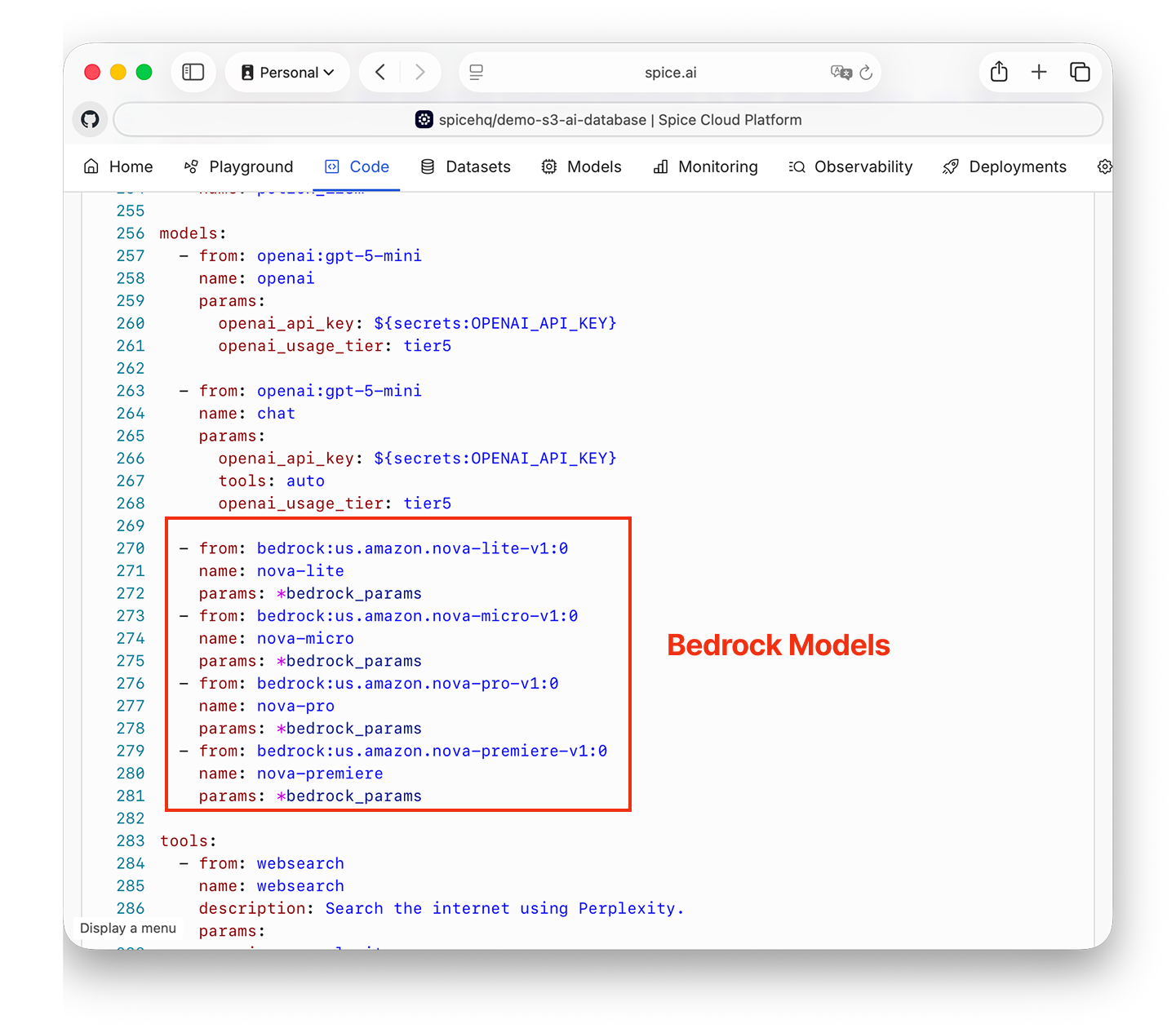
Spice handles the complete end-to-end, from streaming ingestion from Kafka, partitioning data into the right indexes, generating embeddings, managing caches, and accessing everything through SQL.
Step 2: Real-time data ingestion
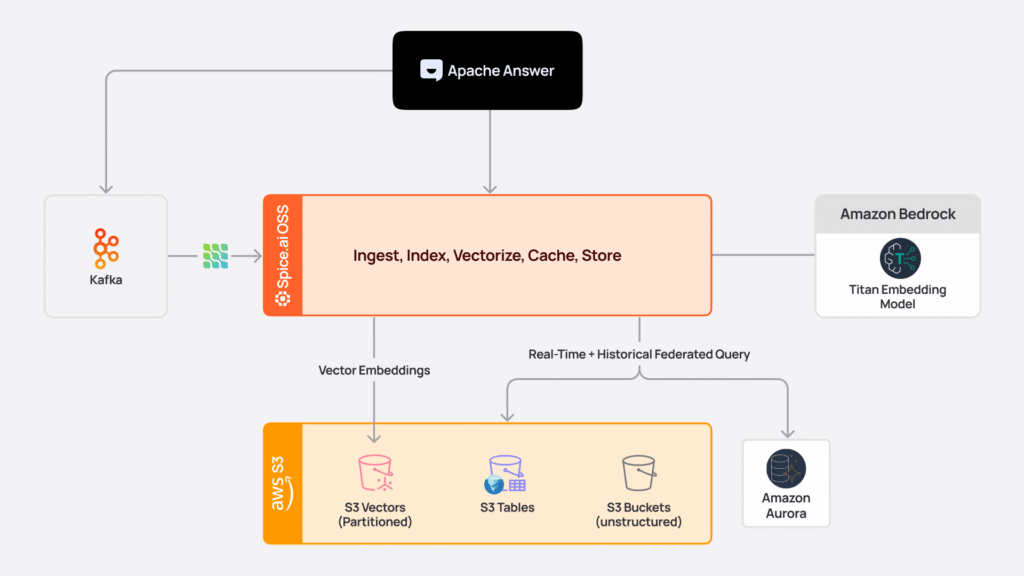
Now that the configuration is in place, we're ready to run Spice. Questions and answers begin streaming into the application through Kafka, which Spice processes in real-time. For each incoming record, it's generating embeddings using Titan, indexing the content for BM25 search, partitioning and sharding the records based on timestamp, and pushing filterable metadata like tags and creation date into S3 Vectors.
While data is streaming in, you can query it live in the Spice Cloud Playground, where the record count ticks up in real-time as data flows through the system.
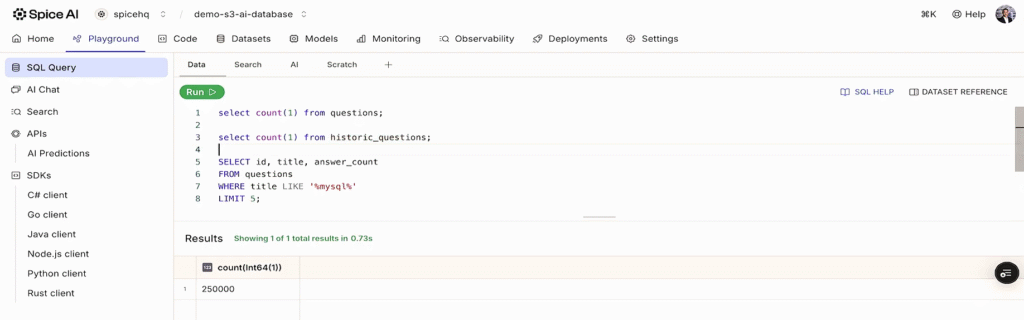
That LIKE query returned in under 100 milliseconds, searching across a quarter million records already ingested and arriving in real-time. This is the power of the tiered caching; frequently accessed queries hit the DuckDB acceleration locally instead of making round trips to S3.
Step 3: Federate across multiple data sources
Spice doesn't just work with S3 but can federate queries across any data source in your stack. That means you can write a single SQL query that joins S3 data with data in Aurora and combines historical logs with real-time metrics from DynamoDB.
Spice pushes down queries from both sources, executes the join, and returnes unified results.
Step 4: Full-text search with BM25
Now, let's improve search results with full-text search for keyword matching and identifying specific terms. Spice provides a text_search function that hits the BM25 index we configured earlier directly (avoiding a full table scan), so if someone is searching for a specific error code or technical term, it will also be included and ranked in the results based on relevance:
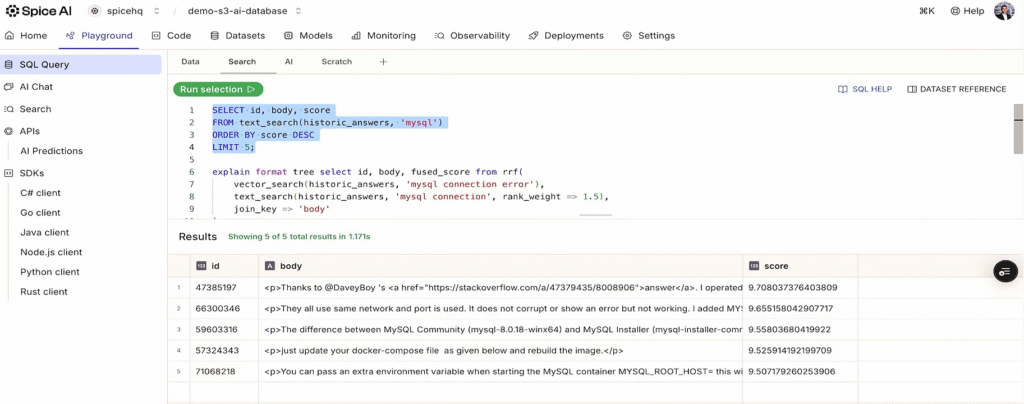
Step 4: Semantic search with S3 Vectors
We'll now add semantic understanding with vector search. The syntax looks almost identical:
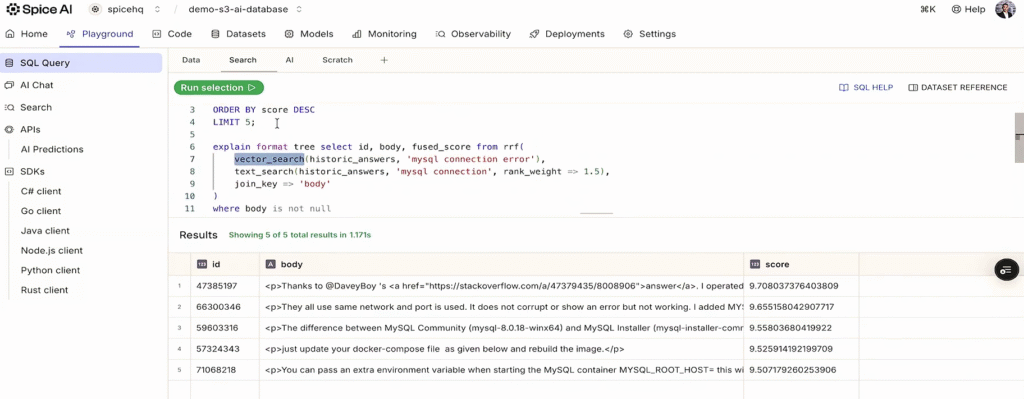
Behind that simple vector_search SQL function is a lot of power. Spice automatically vectorizes the query text using the same Titan model we configured earlier. Then it searches across multiple daily indexes in S3 Vectors and combines the results. We're partitioning by date, so there might be dozens of indexes involved. It applies metadata filters to narrow down the search space, scatter-gather executes the similarity searches in parallel, merges the results, and returns the top-k most similar answers.
You can see exactly what's happening, by running an EXPLAIN query:
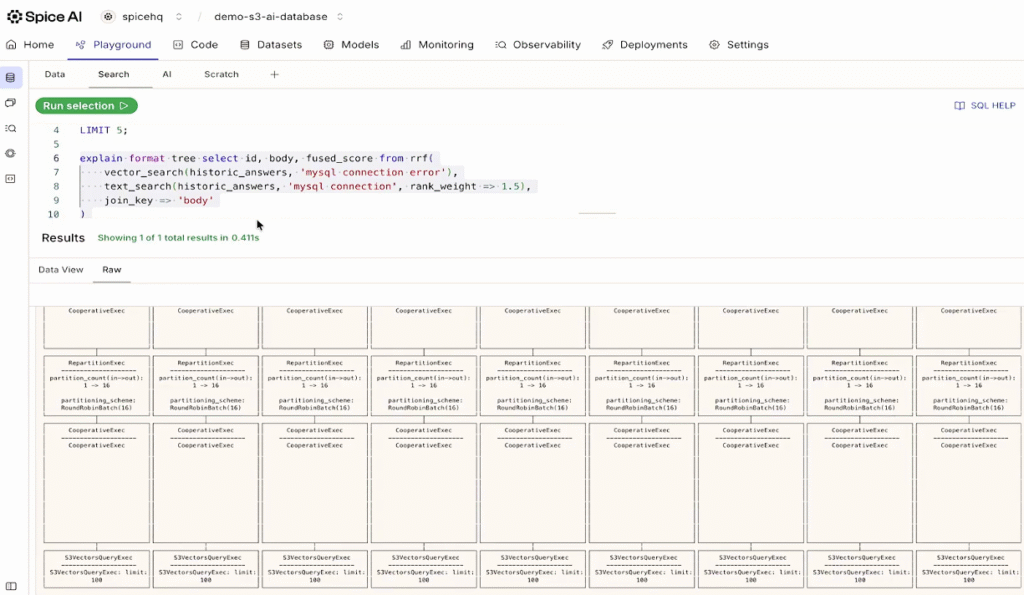
The query plan shows multiple parallel queries to S3 Vectors. Each box in the visualization represents a separate index being searched. Spice automatically shards the query across all relevant daily indexes, executes them in parallel, merges and ranks the results, and returns a unified result set.
This is the kind of thing you'd normally need to build yourself - writing code to manage index metadata, parallel scatter-gather searches, handle failures and retries, merge results with proper ranking. With Spice, you get it out of the box.
Step 5: Hybrid search (BM25 + vector)
Full-text search and vector search combined provide higher relevance search results. Full-text-search excels at catching exact technical terms and keywords. If someone searches for "error code 1045" you want that exact match. Vector search understands semantic similarity; someone searching for "database connection problems" should find answers about "DB connectivity issues".
Hybrid search combines both modalities. Here's how to do that with Spice:
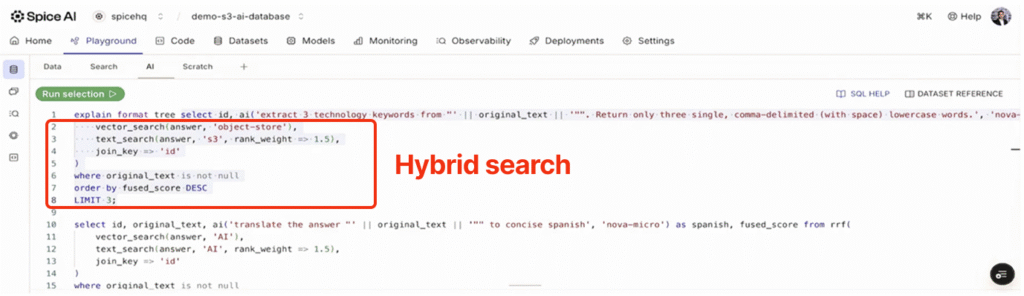
This query runs both searches in parallel, ranks each result set, then uses Reciprocal Rank Fusion (RRF) to combine them into a single ranking (for a more in-depth explainer on RRF, visit the docs).
Step 6: Feed results into AI for analysis
Now that we've got high-quality search results, we can pipe them directly into an LLM for deeper analysis. Spice provides an ai() function that makes this trivial:
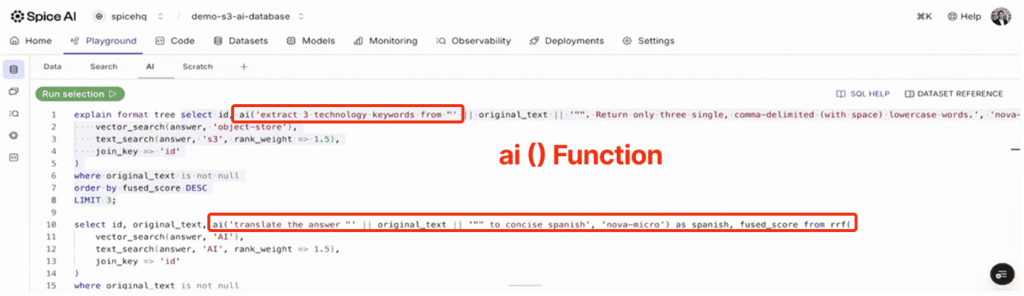
This query pipes the top 10 search results to Amazon Nova to extract the main technology keywords. The results come back right in the SQL result set:

From this simple example, you can extrapolate some pretty interesting use cases that can be enabled with this pattern:
- Run sentiment analysis on customer feedback at scale. For example, search for complaints about a specific product feature and analyze the emotional tone.
- Identify security threats in logs by searching for suspicious patterns and using an LLM to assess severity.
- Detect fraud by finding similar transaction patterns and asking an AI to explain why they're anomalous, automatically tagging and categorizing content by extracting themes and topics.
This is powerful - we went from raw data to AI-generated insights in just three SQL queries. And without an API integration to maintain, ETL'ing data, or custom orchestration code.
The results: Before and after
Let's step back and look at what we actually accomplished. We started with a Q&A application that had fundamentally broken PostgreSQL search: slow 2-3 second queries, 20,000 irrelevant results, no semantic understanding, and no ability to handle streaming data.
After implementing Spice with S3 Tables and S3 Vectors, we returned 20 highly relevant results. The results are dramatically better. Instead of 20,000 irrelevant results, we get 20 highly relevant answers that combine the precision of keyword matching with the semantic understanding of vector search:
This solution incorporated:
- 250,000+ records streaming in real-time while maintaining query performance.
- Queries federated across multiple data sources joining user data and other context.
- Semantic vector search alongside keyword matching for better accuracy.
- Search results piped directly into AI models for analysis.
The difference in user experience is night and day, yet we built this entire system with minimal YAML configuration and SQL queries. Instead of spending weeks building distributed systems and infrastructure, you're defining your configuration and immediately querying data, running searches, and integrating AI into your application, turning your data lake into an AI-ready platform.
Next steps
If you want to try this yourself, star the GitHub repo and explore the Spice.ai recipes. There are recipes for common patterns like hybrid search, S3 Vectors integration, and RAG workflows.
The Spice documentation has a quickstart guide that walks through setting up your first Spice deployment and running queries. Learn more about how to get started with Spice and S3 Vectors in the launch blog, or the 'Architecting high-performance AI-driven data applications with Spice and AWS' tutorial hosted on the AWS Storage Blog.
If you're building AI applications with S3 and want to talk through your specific use case, join us on the Spice Community Slack. We'd love to hear what you're working on.
Frequently Asked Questions
What does it mean to operationalize Amazon S3 for AI?
Operationalizing S3 for AI means adding a runtime layer that turns object storage into a queryable, low-latency data platform for AI applications. S3 stores data durably and cheaply, but it lacks the query execution, acceleration, and vector search capabilities that AI workloads require. Spice bridges this gap by federating queries across S3 Tables, S3 Vectors, and structured data sources in a single SQL interface.
Can S3 be used as a vector database for AI applications?
Yes, with Amazon S3 Vectors, S3 can store and retrieve vector embeddings at scale. Spice integrates S3 Vectors as a native data source, enabling hybrid search that combines vector similarity with full-text and keyword search in a single SQL query -- without a separate vector database.
How does Spice accelerate queries on S3 data?
Spice materializes frequently accessed S3 datasets into local accelerator engines like Arrow, DuckDB, or Cayenne. This reduces query latency from seconds (raw S3 reads) to sub-millisecond responses, while the source data remains in S3. Refresh policies keep accelerated data current without manual ETL.
What is the difference between S3 Tables and traditional S3 storage for analytics?
S3 Tables provides managed Apache Iceberg table support directly in S3, adding ACID transactions, schema evolution, and partition pruning to object storage. Traditional S3 stores flat files (Parquet, CSV) without table-level semantics. S3 Tables eliminates the need for a separate catalog service and simplifies data lake acceleration workflows.
Explore more Spice resources
Tutorials, docs, and blog posts to help you go deeper with Spice.
Real-Time Hybrid Search Using RRF: A Hands-On Guide with Spice
Surfacing relevant answers to searches across datasets has historically meant navigating significant tradeoffs. Keyword (or lexical) search is fast, cheap, and commoditized, but limited by the constraints of exact matching. Vector (or semantic) search captures nuance and intent, but can be slower, harder to debug, and expensive to run at scale. Combining both usually entails standing up multiple engines […]
Getting started with Amazon S3 Vectors and Spice
This post explores how S3 Vectors integrates into Spice's unified data, search, and AI-inference engine-managing embedding generation, index lifecycle, metadata filtering, and hybrid search entirely through SQL. We'll cover how Spice combines vector similarity, full-text BM25, and SQL queries in a single runtime, eliminating the need for separate vector databases.

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer