Introducing Spice Cayenne: The Next-Generation Data Accelerator Built on Vortex for Performance and Scale
Spice AI

Luke Kim
Founder and CEO of Spice AIDecember 17, 2025
TLDR
Spice Cayenne is the next-generation Spice.ai data accelerator built for high-scale and low latency data lake acceleration workloads. It combines the Vortex columnar format with an embedded metadata engine to deliver faster queries and significantly lower memory usage than existing Spice data accelerators, including DuckDB and SQLite. Watch the demo for an overview of Spice Cayenne and Vortex.
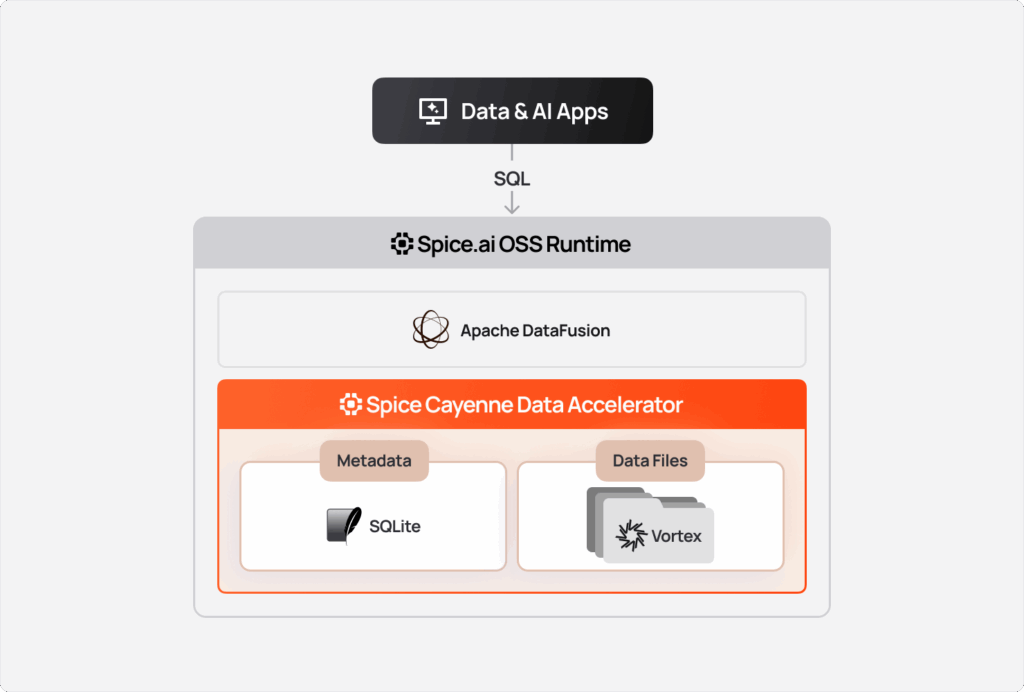
Introduction
Spice.ai is a modern, open-source SQL query engine that enables development teams to federate, accelerate, search, and integrate AI across distributed data sources. It's designed for enterprises building data-intensive applications and AI agents across disparate, tiered data infrastructure. Data acceleration of disparate and disaggregated data sources is foundational across many vertical use cases the Spice platform enables.
Spice leans into the industry shift to object storage as the primary source of truth for applications. These object store workloads are often multi-terabyte datasets using open data lake formats like Parquet, Iceberg, or Delta that must serve data and search queries for customer-facing applications with sub-second performance. Spice data acceleration, which transparently materializes working sets of data in embedded databases like DuckDB and SQLite, is the core technology that makes these applications built on object storage functional. Embedded data accelerators are fast and simple for datasets up to 1TB, however for multi-terabyte workloads, a new class of accelerator is required.
So we built Spice Cayenne, the next-generation data accelerator for high volume and latency-sensitive applications.
Spice Cayenne combines Vortex, the next-generation columnar file format from the Linux Foundation, with a simple, embedded metadata layer. This separation of concerns ensures that both the storage and metadata layers are fully optimized for what each does best. Cayenne delivers better performance and lower memory consumption than the existing DuckDB, Arrow, SQLite, and PostgreSQL data accelerators.
This post explains why we built Spice Cayenne, how it works, when it makes sense to use instead of existing acceleration options, and how to get started.
How data acceleration works in Spice
Spice accelerates datasets by materializing them in local compute engines; which can be ApacheDataFusion + Apache Arrow, SQLite, or DuckDB, in-memory or on-disk. This provides applications with high-performance, low-latency queries and dynamic compute flexibility beyond static materialization. It also reduces network I/O, avoids repeated round-trips to downstream data sources, and as a result, accommodates applications that need to access disparate data, join that data, and make it really fast. By bringing frequently accessed working sets of data closer to the application, Spice delivers sub-second, often single-digit millisecond queries without requiring additional clusters, ingestion pipelines, or ETL.
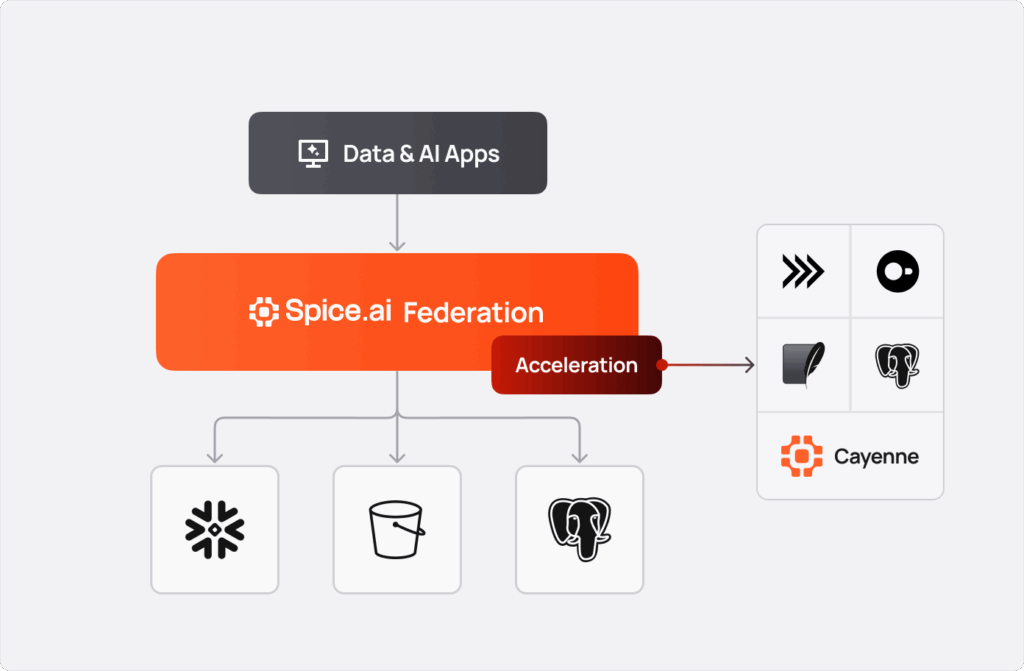
To support the wide range of enterprise workloads run on Spice, the platform includes multiple acceleration engines suited to different data shapes, query patterns, and performance needs. The Spice ethos is to offer optionality: development teams can choose the engine that best fits their requirements. These are currently the following acceleration engines:
- PostgreSQL: PostgreSQL is great for row-oriented workloads, but is not optimized for high-volume columnar analytics.
- Arrow (in-memory): Arrow is ideal for workloads that need very fast in-memory access and low-latency scans. The tradeoff is that data isn't persisted to disk and more sophisticated operations like indexes aren't supported.
- DuckDB: DuckDB offers excellent all-around performance for medium-sized datasets and analytical queries. Single file limits and memory usage, however, can become a constraint as data volume grows beyond a terabyte.
- SQLite: SQLite is a lightweight option that excels for smaller tables and row-based lookups. SQLite's single-writer model, file single limits, and limited parallelism make it less ideal for larger or analytical workflows.
Why we built Spice Cayenne
Enterprise workloads on multi-terabyte datasets stored in object storage share a common set of pressure points; the volume of data continues to increase, more applications and services are querying the same accelerated tables at once, and teams need consistently fast performance without having to manage extra infrastructure.
Existing accelerators perform well at smaller scale but run into challenges at different inflection points:
- Single-file architectures create bottlenecks for concurrency and updates.
- Memory usage of embedded databases like DuckDB can be prohibitive.
- Database and search index creation and storage can be prohibitive.
These constraints inspired us to develop the next-generation accelerator for petabyte-scale, that keeps metadata operations lightweight, and maintains low-latency, high-performance queries even as dataset sizes and concurrency increase. It also was critically important the underlying technologies aligned with the Spice philosophy of open-source with strong community support and governance.
Spice Cayenne addresses these requirements by separating metadata and data storage into two complementary layers: the Vortex columnar format and an embedded metadata engine.
Spice Cayenne architecture
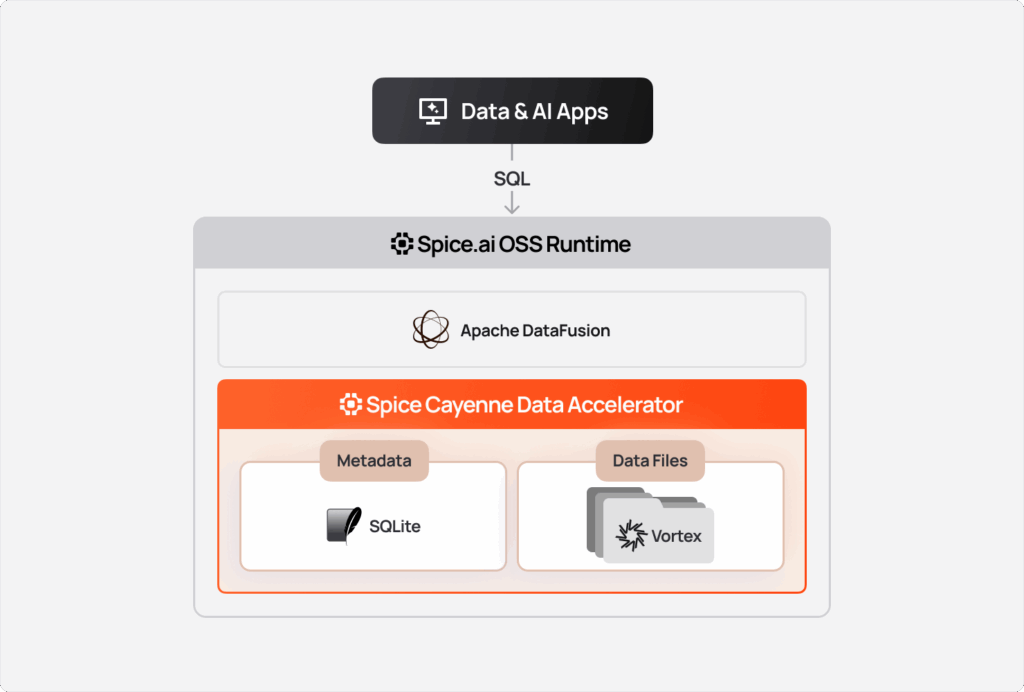
Cayenne is built with two core concepts:
1. Data: Vortex Columnar Format
Data is stored in Vortex, the next-generation open-source, Apache-licensed format under the Linux Foundation.
Compared with Apache Parquet, Vortex provides:
- 100x faster random access
- 10-20x faster full scans
- 5x faster writes
- Zero-copy compatibility with Apache Arrow
- Pluggable compression, encoding, and layout strategies
Source: Vortex Github
Vortex has a clean separation of logical schema and physical layout, which Cayenne leverages to support efficient segment-level access, minimize memory pressure, and extend functionality without breaking compatibility. It draws on years of academic and systems research including innovations from projects like YouTube's Procella, FSST, FastLanes, ALP/G-ALP, and MonetDB/X100 to push the boundaries of what's possible in open-source analytics.
Extensible and community-driven, Vortex is already integrated with tools like Apache Arrow, DataFusion, and DuckDB, and is designed to support Apache Iceberg in future releases. It's also the foundation of commercial offerings from SpiralDB and PolarSignals. Since version 0.36.0, Vortex guarantees backward compatibility of the file format.
2. Metadata Layer
Cayenne stores metadata in an embedded database. SQLite is supported today, but aligned with the Spice philosophy of optionality, the design is extensible for pluggable metadata backends in the future. Cayenne's metadata layer was intentionally designed as simple as possible, optimizing for maximum ACID performance.
The metadata layer includes:
- Schemas
- Snapshots
- File tracking
- Statistics
- Refreshes
All metadata access is done through standard SQL transactions. This provides:
- A single, local source of truth
- Fast metadata reads
- Consistent ACID semantics
- No external catalog servers
- No scattered metadata files
A single SQL query retrieves all metadata needed for query planning. This eliminates round-trip calls to object storage, supports file-pruning, and reduces sensitivity to storage throttling.
Together, the metadata engine and Vortex format enable Cayenne to scale beyond the limits of single-file engines while keeping acceleration operationally simple.
Benchmarks
So, how does Spice Cayenne stack up to the other accelerators?
We benchmarked Cayenne against DuckDB v1.4.2 using industry standard benchmarks (TPC-H SF100 and ClickBench), comparing both query performance and memory efficiency. All tests ran on a 16 vCPU / 64 GiB RAM instance (AWS c6i.8xlarge equivalent) with local NVMe storage. Cayenne was tested with Spice v1.9.0.
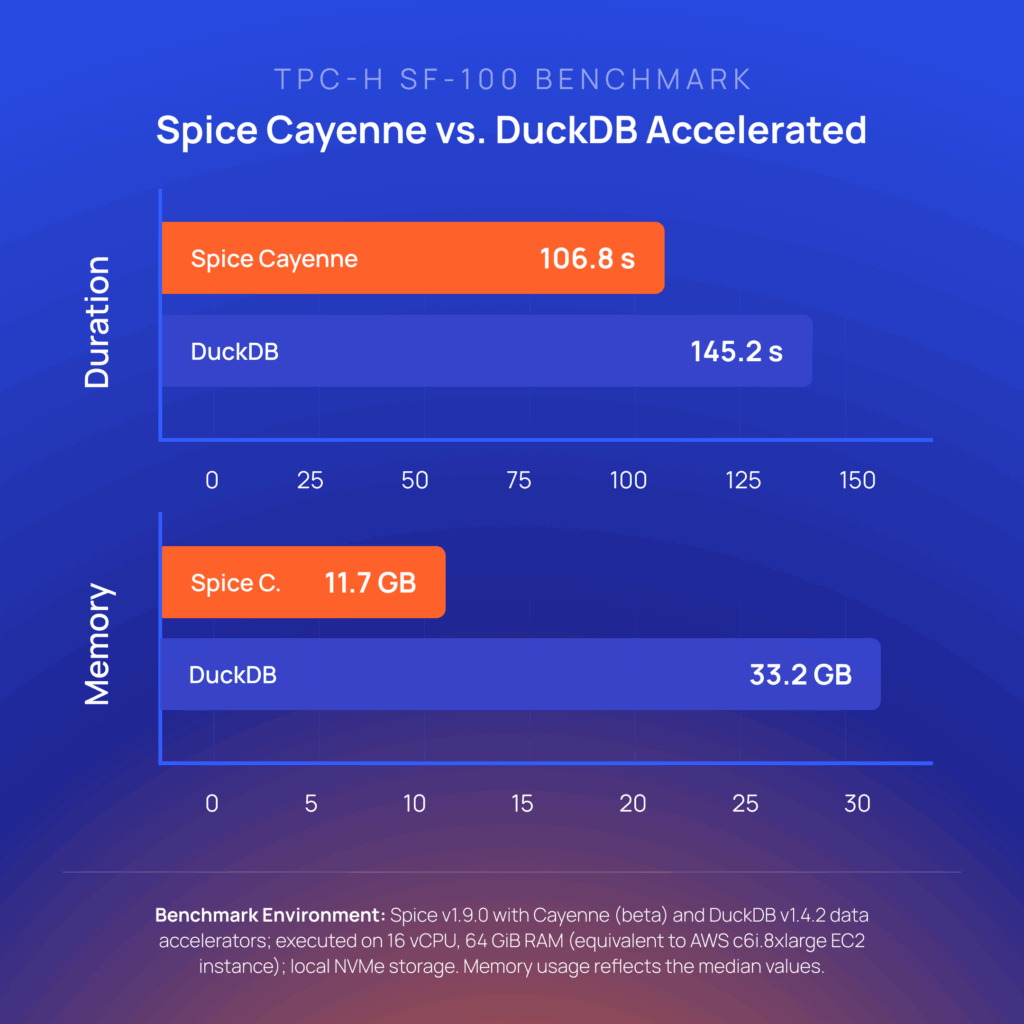
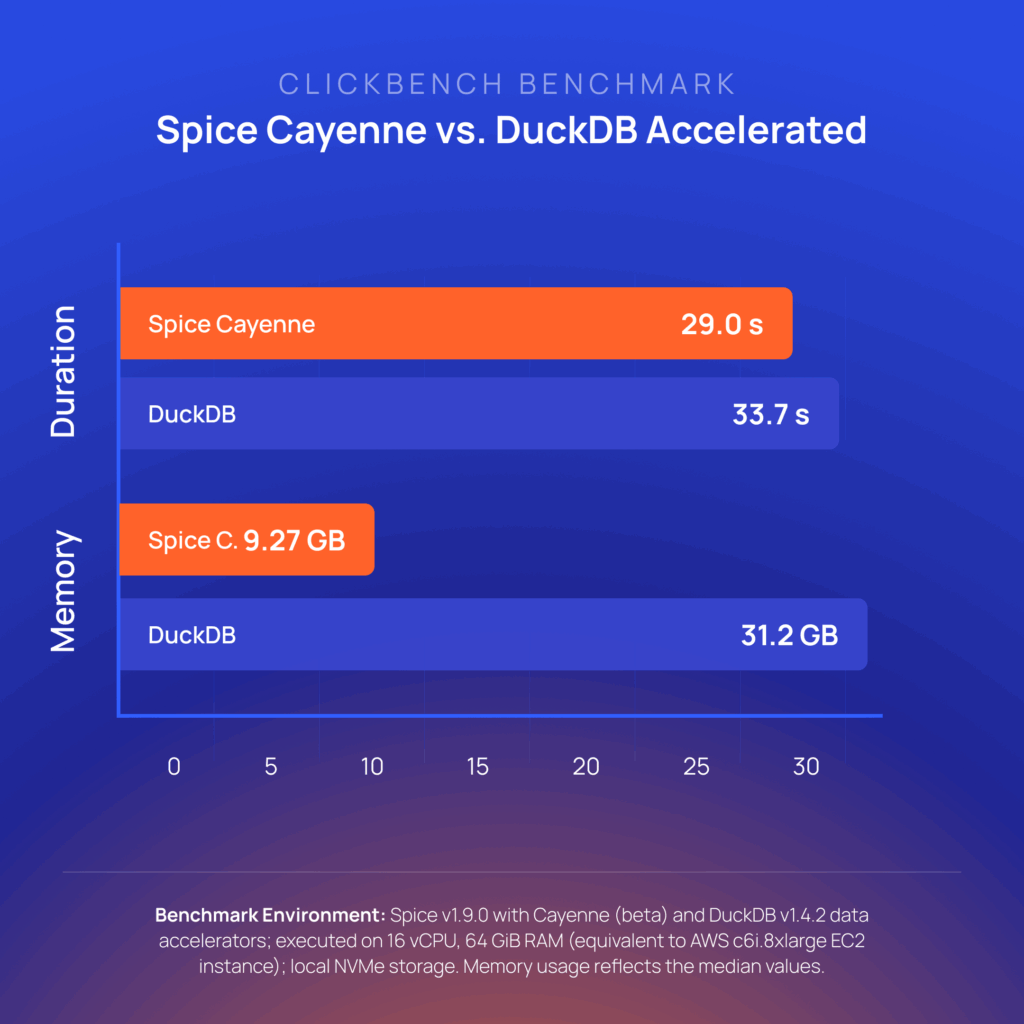
Spice Cayenne achieves faster query times and drastically lower memory usage by pairing a purpose-built execution engine with the Vortex columnar format. Unlike DuckDB, Cayenne avoids monolithic file dependencies and high memory spikes, making it ideal for production-grade acceleration at scale.
Getting started with Spice Cayenne
Use Cayenne by specifying engine: cayenne in the Spicepod.yml (dataset configuration).
Following are a few example configurations.
Basic:
datasets:
- from: spice.ai:path.to.my_dataset
name: my_dataset
acceleration:
engine: cayenne
mode: fileFull configuration:
version: v1
kind: Spicepod
name: cayenne-example
datasets:
- from: s3://my-bucket/data/
name: analytics_data
params:
file_format: parquet
acceleration:
engine: cayenne
enabled: true
refresh_mode: full
refresh_check_interval: 1hMemory
Memory usage depends on dataset size, query patterns, and caching configuration. Vortex's design reduces memory overhead by using selective segment reads and zero-copy access.
Storage
Disk space is required for:
- Vortex columnar data
- Temporary files during query execution
- Metadata tables
Provision storage according to dataset size and refresh patterns.
Roadmap
Spice Cayenne is in beta and still evolving. We encourage users to test Cayenne in development environments before deploying to production.
Upcoming improvements include:
- Index support
- Improved snapshot bootstrapping
- Additional metadata backends
- Advanced compression and encoding strategies
- Expanded data type coverage
The goal for Spice Cayenne stable is for Cayenne to be the fastest, most efficient accelerator across the full range of analytical and operational data and AI workloads at terabyte & petabyte-scale.
Conclusion
Spice Cayenne represents a step function improvement in Spice data acceleration, designed to serve multi-terabyte, high concurrency, and low-latency workflows with predictable operations. By pairing an embedded metadata engine with Vortex's high-performance format, Cayenne offers a scalable alternative to single-file accelerators while keeping configuration simple.
Spice Cayenne is available in beta in Spice Cloud and Spice Open Source. We welcome feedback on the road to its stable release.
Frequently Asked Questions
What is Spice Cayenne?
Spice Cayenne is a data accelerator engine built for multi-terabyte, low-latency data lake acceleration workloads. It combines the Vortex columnar format with an embedded SQLite-backed metadata engine to deliver faster queries and lower memory usage than DuckDB or Arrow-based alternatives.
How does Cayenne compare to DuckDB for data acceleration?
On TPC-H SF100 benchmarks, Cayenne delivers 1.4x faster query execution and uses 3x less memory than DuckDB file mode. On ClickBench, Cayenne is 14% faster with 3.4x less memory. These gains come from the Vortex format's zero-copy Arrow compatibility and fine-grained pruning capabilities, which avoid the monolithic file dependencies that drive DuckDB's memory spikes.
What is the Vortex columnar format?
Vortex is an open-source columnar file format under the Linux Foundation, designed as a modern alternative to Apache Parquet. It provides 100x faster random access, 10-20x faster scans, and 5x faster writes compared to Parquet. Vortex is zero-copy compatible with Apache Arrow, meaning data can be queried directly without conversion overhead.
When should I use Cayenne instead of DuckDB or Arrow acceleration in Spice?
Use Cayenne for large-scale data lake workloads (hundreds of gigabytes to multi-terabyte datasets) where memory efficiency and consistent query performance matter. DuckDB and Arrow remain good choices for smaller datasets or when DuckDB-specific SQL extensions are needed. Cayenne is the recommended default accelerator for production SQL federation and acceleration deployments.
See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer