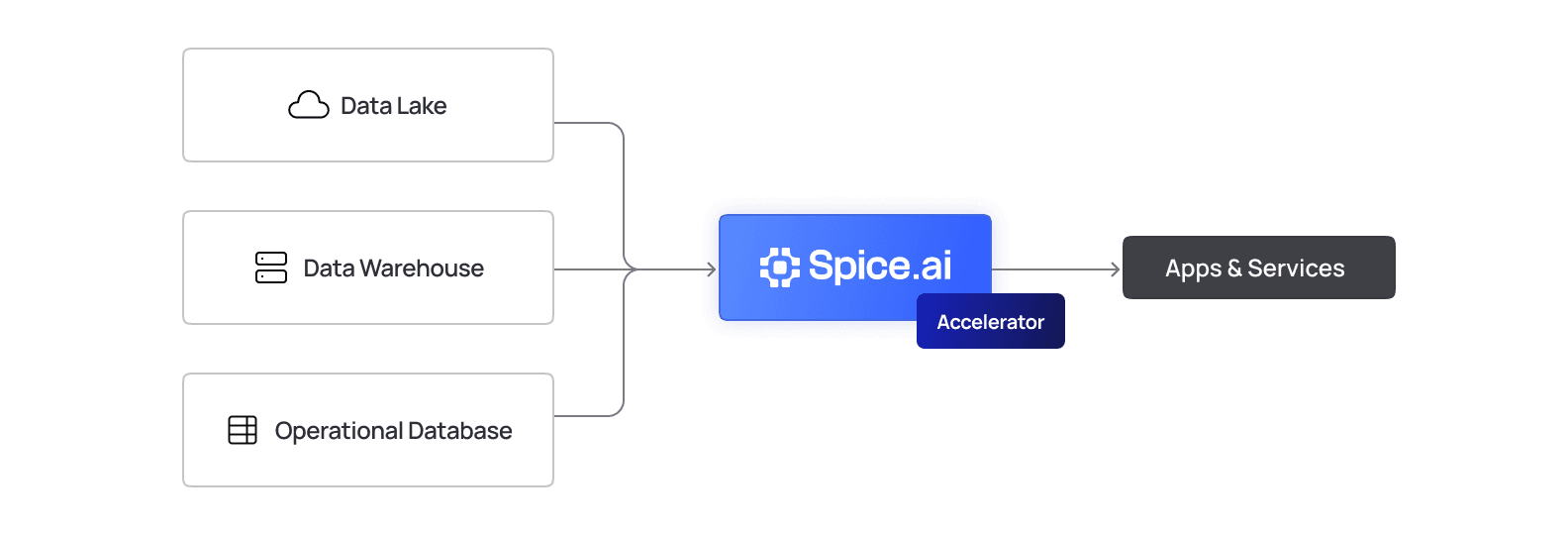
Serve real-time data and AI from object storage
Retain the scalability of object storage and the governance of open table formats. Add Spice to federate, accelerate, and power operational and AI workloads with millisecond query performance.
Do more with your data
0x
up to 100x faster queries
0%
up to 80% cost savings on data lakehouse spend
0x
increase in data reliability for critical workloads
Lakehouses weren't built for operational workloads
Traditional data lakehouses handle analytics well but lag for modern apps and AI agents that need sub-second responses and federated access. The result is slow queries, complex pipelines, and high costs when serving real-time operational data.

Turn your lakehouse into an operational data layer
Make your data lakehouse fast, federated, and AI-ready-serving live workloads at millisecond latency.
Federate across sources
Query databases, APIs, and object storage using standard SQL. Combine transactional and analytical data in a single query with zero ETL.
Explore SQL federation and acceleration
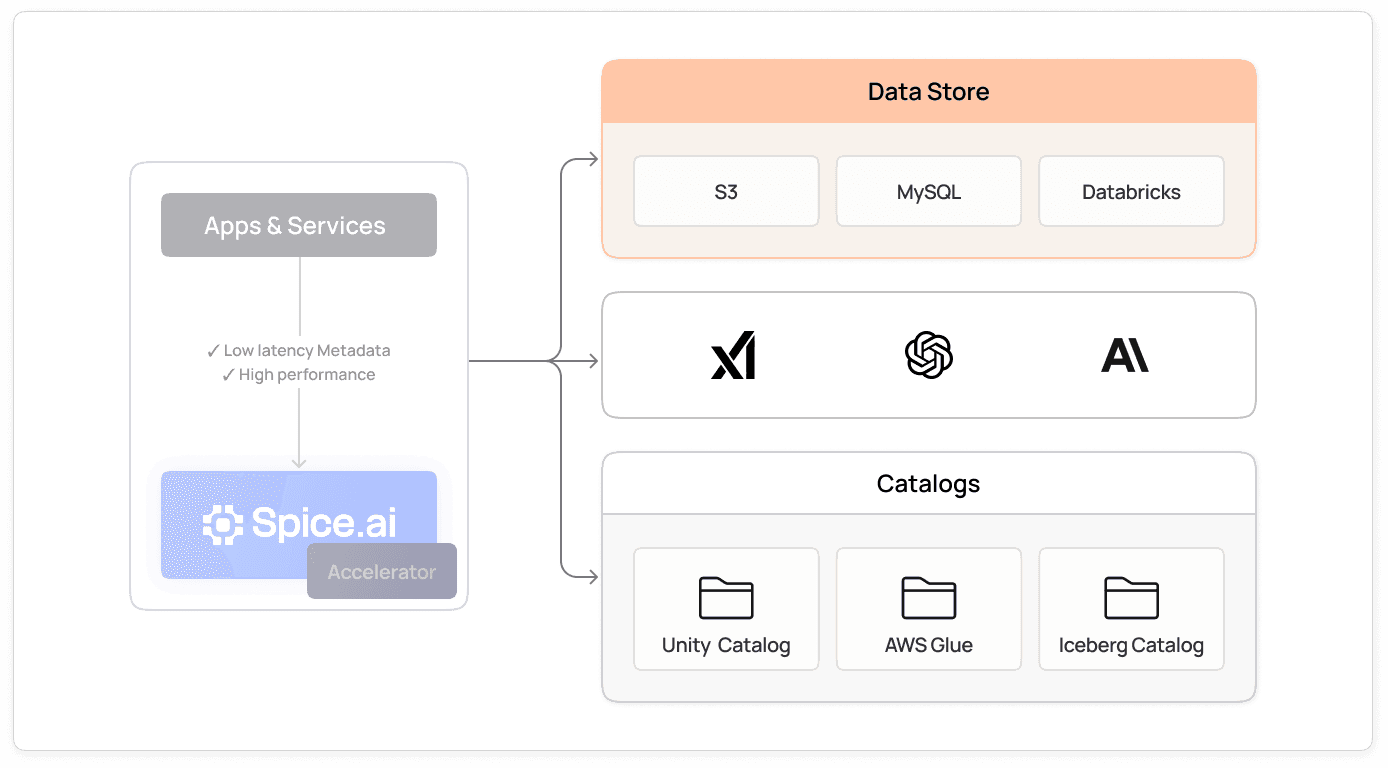
Accelerate object storage performance
Use data accelerators like Spice Cayenne, DuckDB, or SQLite to materialize and cache hot datasets locally. Reduce query latency from seconds to milliseconds while maintaining the scale and economics of object storage.
Explore Spice Cayenne Data Accelerator
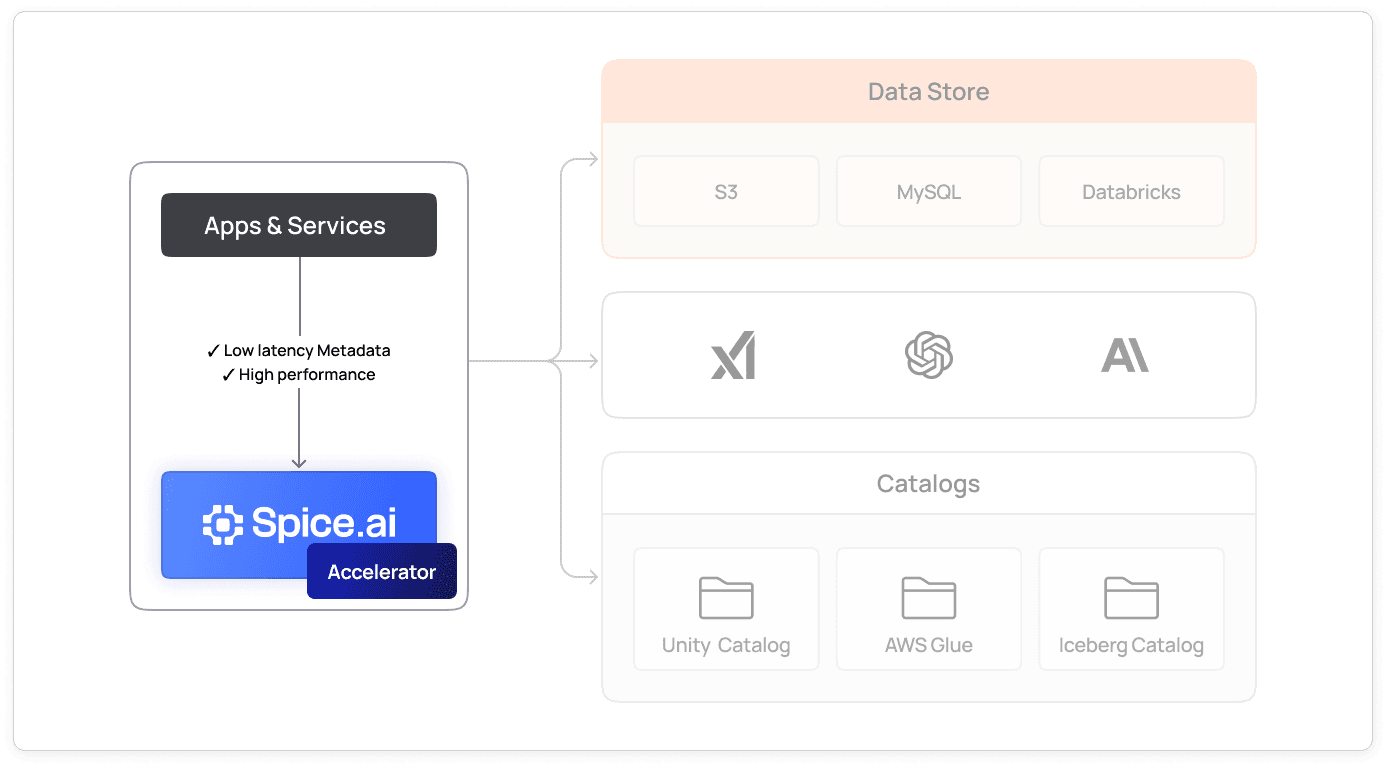
Serve operational and AI workloads
SQL federation, acceleration, and AI inference in one runtime means you can support disparate workloads directly from your data lakehouse, all in real time.
Explore LLM inference in Spice
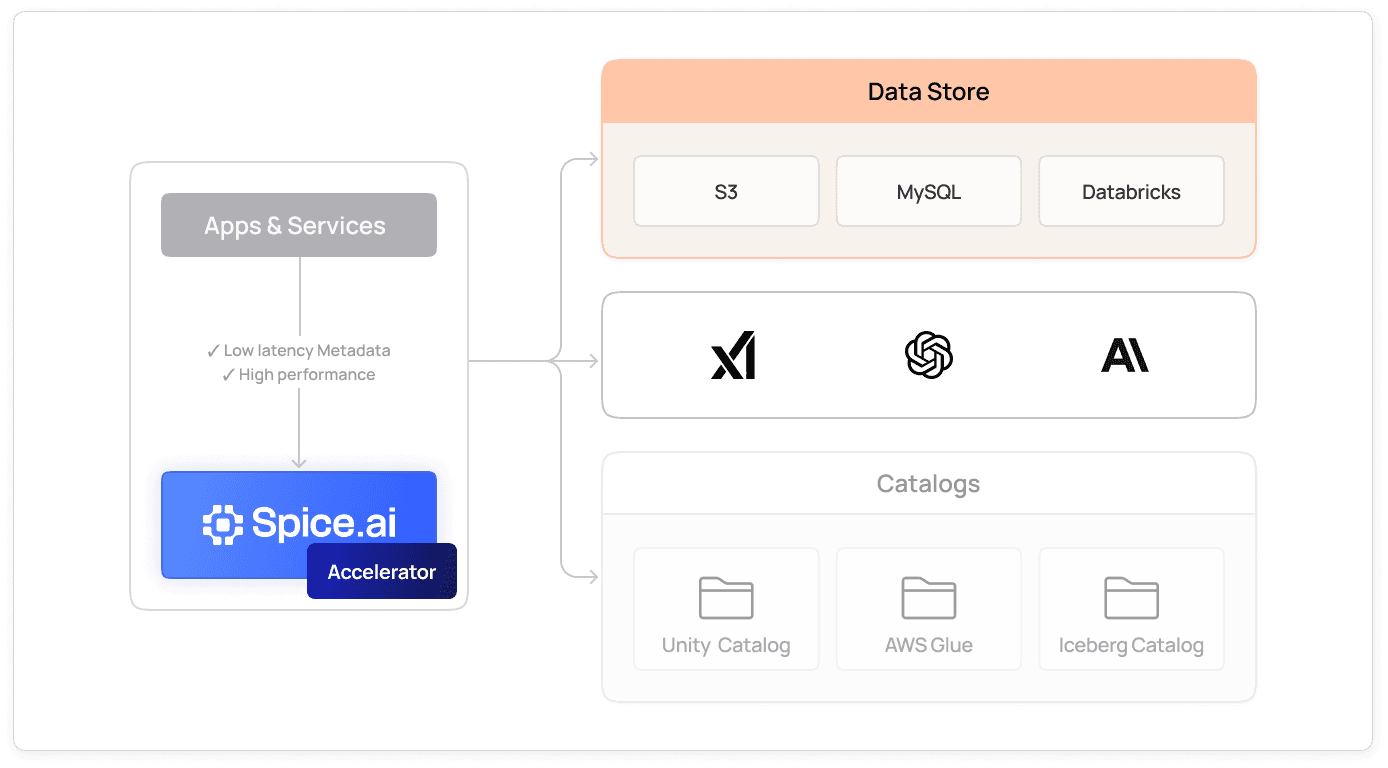
Native open table format support
Connect to Apache Iceberg, Delta Lake, or Parquet for schema management, ACID transactions, and optimized query planning.
Read about Apache Iceberg at Spice AI
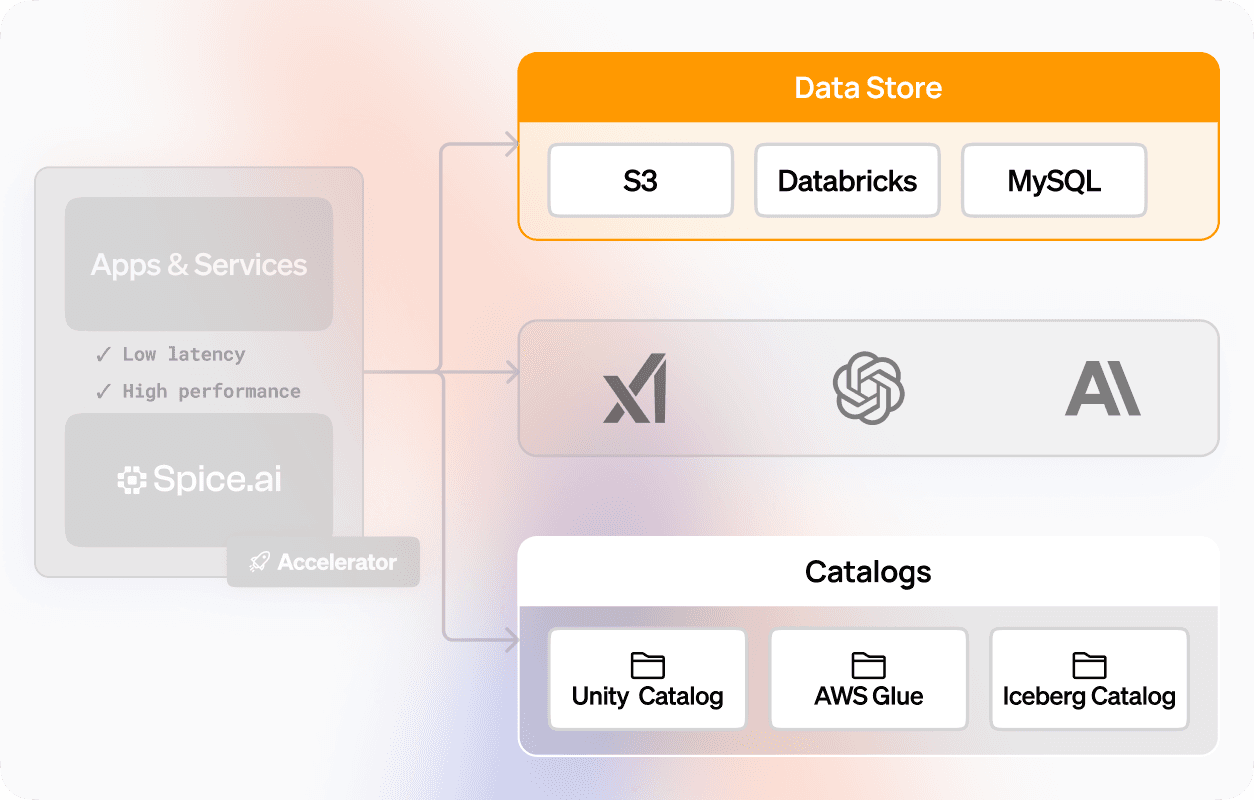
Why enterprises operationalize their lakehouse with Spice
Spice bridges the gap between analytical and operational workloads. Combine federation, acceleration, and AI in one lightweight, portable runtime.
SQL-First Hybrid Search
Bring hybrid search - keyword, full-text, and vector - directly to your lakehouse to surface insights and relationships using simple SQL.
Mixed Workload Execution
Serve both operational applications and analytical queries from one runtime.
Open Table Support
Built-in support for Iceberg, Delta Lake, and Parquet for structured governance.
Reliability and Continuity
Failover to object storage if local acceleration is unavailable.
Governance and Observability
Enterprise access control, metrics, and auditability included.
Deployment Flexibility
Run Spice anywhere: as a sidecar, microservice, cluster, or on the managed Spice Cloud Platform.
Proven in production
Run data-intensive workloads on a high-performance engine trusted by teams building real-time systems at scale.



“Spice opened the door to take these critical control-plane datasets and move them next to our services in the runtime path.”
Peter Janovsky
Software Architect, Twilio

0x
Faster queries
“It just spins up and works, which is really nice. The responsiveness is amazing, which is a huge gain for the customer.”
Darin Douglass
Principal Software Engineer, Barracuda

“Partnering with Spice AI has transformed how NRC Health delivers AI-driven insights. By unifying siloed data across systems, we accelerated AI feature development, reducing time-to-market from months to weeks - and sometimes days. With predictable costs and faster innovation, Spice isn't just solving some of our data and AI challenges - it's helping us redefine personalized healthcare.”
Tim Ottersburg
VP of Technology, NRC Health
Trusted by global enterprises


Use Spice as an operational data lakehouse
Guides and examples to learn more about building an operational data lakehouse with Spice.
Making Object Storage Operational for Real-Time and AI Workloads
TLDR Introduction Although legacy systems and workflows remain common, many enterprises are re-evaluating their architectures to meet new demands – driven in part, but not exclusively, by AI – that require support for more data-intensive and real-time applications. The underlying storage needs for these novel workloads are generally outside the bounds of a traditional operational […]
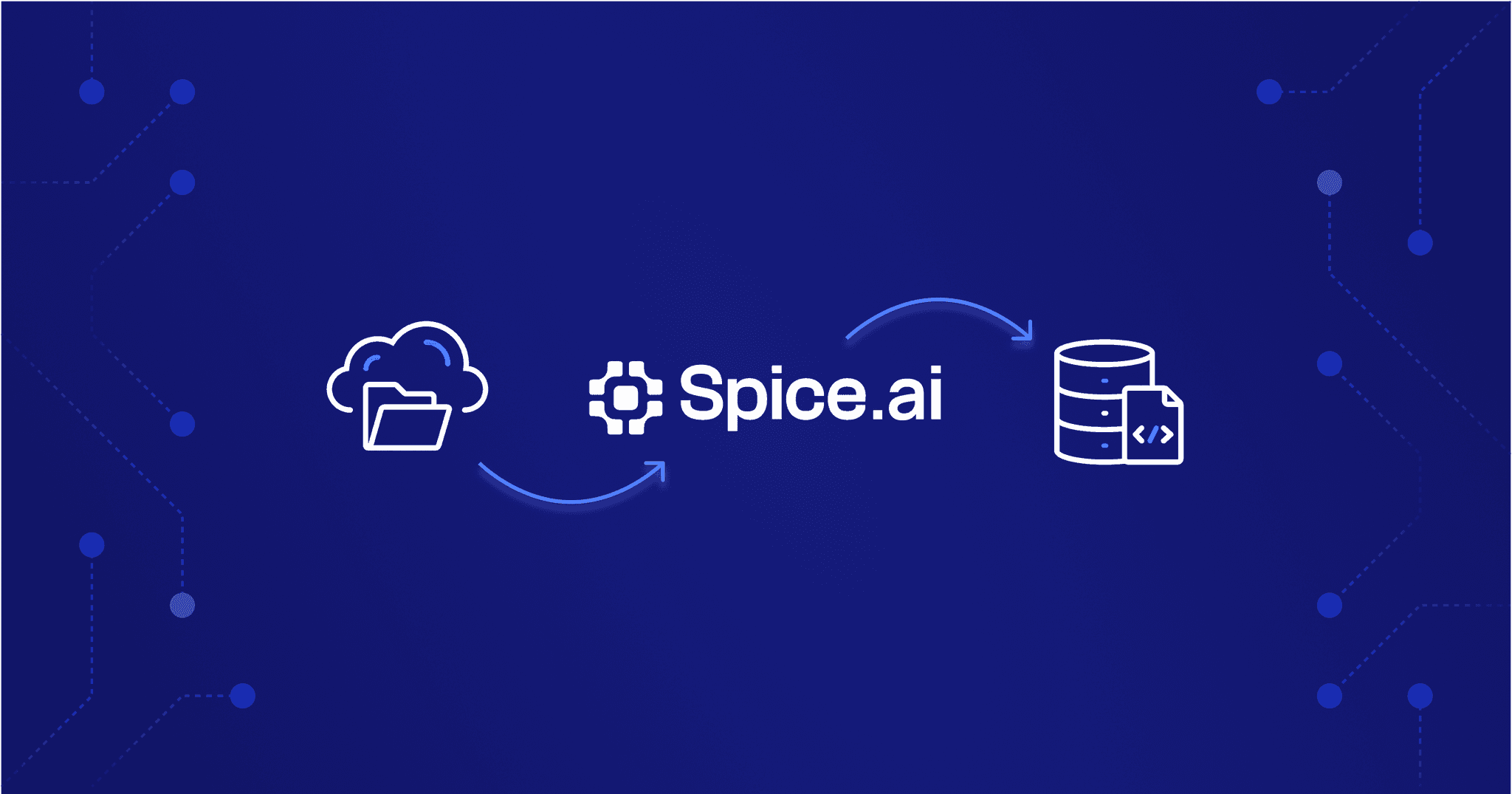
Federated SQL Query Cookbook
Learn how to fetch combined data from S3 Parquet, PostgreSQL, and Dremio in a single query.

Data Acceleration with DuckDB
This recipe walks through how to accelerate a local copy of the taxi trips dataset stored in S3 using DuckDB as the data accelerator engine.
FAQs
Answers to common questions about running operational workloads on a lakehouse
What is an operational data lakehouse?
An operational data lakehouse serves live applications and AI workloads directly from object storage with low-latency queries, instead of limiting the lakehouse to batch analytics. Spice adds federation, acceleration, and AI inference on top of open table formats, so one runtime answers both operational and analytical queries in real time.
How does Spice achieve millisecond queries on object storage?
Spice materializes and caches hot datasets locally using data accelerators such as Spice Cayenne, DuckDB, or SQLite. This reduces query latency from seconds to milliseconds while maintaining the scale and economics of object storage. The same approach powers data lake acceleration for interactive workloads.
Which open table formats does Spice support?
Spice natively supports Apache Iceberg, Delta Lake, and Parquet. Open table format support provides schema management, ACID transactions, and optimized query planning while keeping data governed in open formats on your own object storage.
Can I combine lakehouse data with databases and APIs in one query?
Yes. Spice federates queries across databases, APIs, and object storage using standard SQL, so transactional and analytical data combine in a single query with zero ETL. The SQL federation and acceleration engine plans and executes the query across sources.
What happens if local acceleration is unavailable?
Queries fail over to the underlying object storage source automatically. This keeps applications available and results consistent even when locally accelerated data cannot be served.
See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer