How we use Apache DataFusion at Spice AI
Spice AI
Spice Cloud Platform
Spice OSS
SQL Federation

Phillip LeBlanc
Co-Founder and CTO of Spice AIJanuary 15, 2026
TL;DR: Spice is built on Apache DataFusion, a Rust-native query engine. This post covers how Spice extends DataFusion with custom table providers for SQL federation, optimizer rules for acceleration routing, UDFs for hybrid search and LLM inference, and lessons learned building a production SQL platform on DataFusion.
Introducing 'Engineering at Spice AI'
'Engineering at Spice AI' is a technical blog series that breaks down the systems and abstractions behind Spice's data and AI platform.
We'll explain why we chose specific open-source technologies, how we've extended them, and what we've learned building a SQL-first platform for federated query and acceleration, search, and embedded LLM inference.
The goal of this series is to share concrete engineering patterns that teams building data and AI infrastructure can apply in their own systems, while also unfolding how Spice is designed so users understand and can trust the foundations they're relying on. Familiarity with SQL engines, Arrow, or Rust will help.
This article kicks off the series by diving into Apache DataFusion, the query engine at the core of Spice.
Future posts will cover:
- Rust at Spice AI - Our systems programming foundation
- Apache Arrow at Spice AI- Arrow as our core in-memory data format
- DuckDB at Spice AI - Embedded analytics acceleration
- Apache Iceberg at Spice AI - Open table format and SQL-based ingestion
- Vortex at Spice AI - Columnar compression for Cayenne, our premier data accelerator
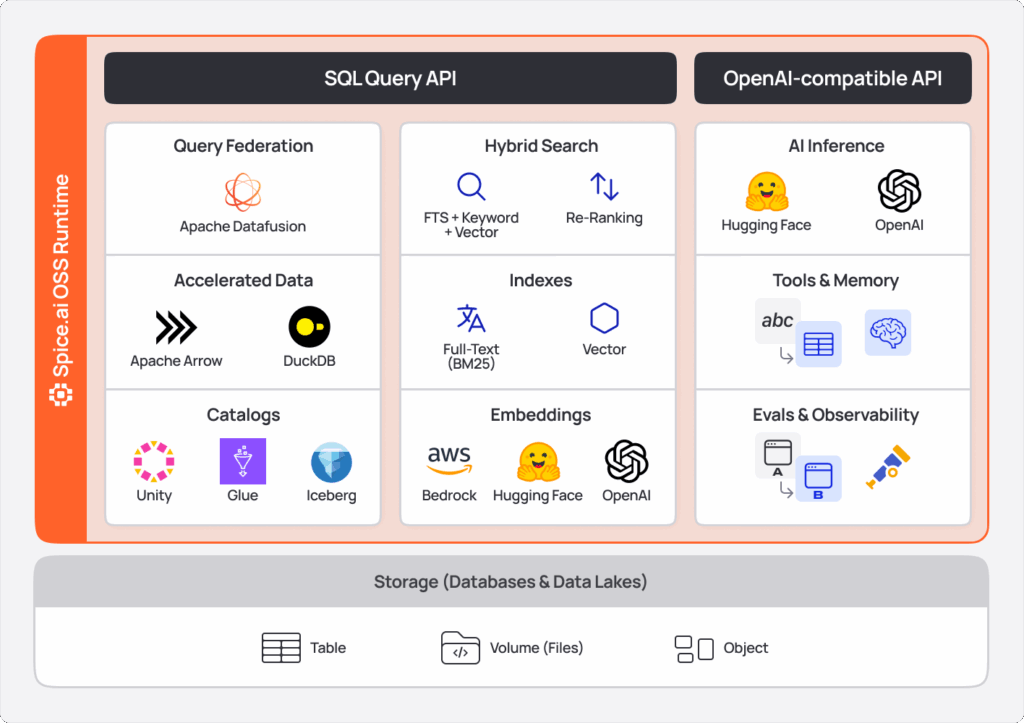
What is Apache DataFusion?
Apache DataFusion is a fast, extensible query engine written in Rust. It provides SQL and DataFrame APIs, a query planner, a cost-based optimizer, and a multi-threaded execution engine, all built on Apache Arrow.
DataFusion provides the complete query execution pipeline:
SQL → Parsed SQL (*AST) → Logical Plan → Optimizer → Physical Plan → Execution → Arrow Results
DataFusion provides extension points across planning and execution, which we use to add custom table providers (20+ sources), optimizer rules (federation and acceleration pushdowns), and UDFs (AI inference, vector search, and text search).
Each stage is extensible:
| Stage | Extension Point | Spice Extensions |
|---|---|---|
| Parser | Custom SQL syntax | - |
| Logical Planning | TableProvider, ScalarUDF, TableFunction | 20+ data connectors |
| Optimization | OptimizerRule, AnalyzerRule | Federation analyzer |
| Physical Planning | ExtensionPlanner | DuckDB aggregate pushdowns |
| Execution | ExecutionPlan | Schema casting, managed streams, fallback execution |
Why DataFusion at Spice
The core technical challenge we were looking to solve was executing one logical query across many fundamentally different systems: operational databases, data warehouses, object stores, streams, APIs, and more - while still making that query fast, composable, and extensible enough to evolve with rapidly changing data and AI workloads.
After evaluating several engines, DataFusion was the one that met those requirements without forcing architectural compromises:
- Native Rust and Arrow: DataFusion is written in Rust and uses Arrow as its native memory format, matching our architecture without foreign function interface (FFI) overhead, runtime boundary crossings, or data format conversions.
- Extensibility: Every component can be replaced or extended. We can add custom data sources, optimizer rules, and execution plans without forking the core engine.
- Active community: DataFusion has an active community with regular releases. We contribute upstream when our extensions benefit the broader ecosystem.
- Performance: DataFusion's execution engine uses:
- Vectorized processing with Arrow arrays
- Push-based execution for streaming
- Partition-aware parallelism that scales with CPU cores
- Predicate and projection pushdown to minimize data movement
How we use DataFusion
We treat DataFusion as a programmable query compiler and runtime.
At a high level, DataFusion gives us:
- A full SQL -> logical -> physical execution pipeline
- A cost-based optimizer we can extend and rewrite
- Stable extension points at every stage of planning and execution
- Arrow-native, vectorized execution that works equally well for analytics and streaming results
The unique qualities around our DataFusion implementation includes:
- Deciding where a query should execute (source vs. local accelerator)
- Deciding when cached data is valid, stale, or needs fallback
- Injecting AI inference and search functions directly into SQL
- Coordinating execution across local, remote, and hybrid plans
DataFusion is one of the few engines where these decisions can be expressed inside the planner and execution engine itself, rather than bolted on externally.
What DataFusion delivers for Spice
DataFusion enables several components that define Spice today:
- SQL federation: We can push computation down to source systems or pull it into local accelerators
- Pluggable acceleration: Spice accelerates datasets by materializing them in local compute engines, providing applications with high-performance, low-latency queries and dynamic compute flexibility beyond static materialization.
- Spice supports multiple acceleration engines as first-class execution targets: ApacheDataFusion + Apache Arrow, SQLite, Spice Cayenne, and DuckDB, with options for in-memory or on-disk storage. Accelerations are implemented as a standard DataFusion TableProvider that manages two underlying table providers: a federated table provider (pointing to the source system) and an acceleration engine table provider (the local materialized copy). This architecture enables accelerations to integrate with DataFusion's query planning and execution; Spice manages refresh by executing special DataFusion queries on the federated table and inserting results into the accelerated table. Most user queries are served directly from the accelerated table, with automatic fallbacks to the federated table under specific conditions (such as cache misses or data freshness requirements).
pub struct AcceleratedTable {
dataset_name: TableReference,
accelerator: Arc<dyn TableProvider>, // Local cache (DuckDB, SQLite, Arrow)
federated: Arc<FederatedTable>, // Source data
zero_results_action: ZeroResultsAction, // Fallback behavior
refresh_mode: RefreshMode, // Full, Append, Changes
}- Search and AI as query operators: Vector search, text search, and LLM calls are modeled as UDFs and table functions.
- Resilient, production-grade execution: Deferred connections, fallback execution, schema casting, and cache invalidation all live inside the engine, not the application layer.
- Incremental improvements: As DataFusion adds new optimizer capabilities, execution primitives, and APIs, we can adopt them incrementally while still shipping Spice-specific features on our own cadence
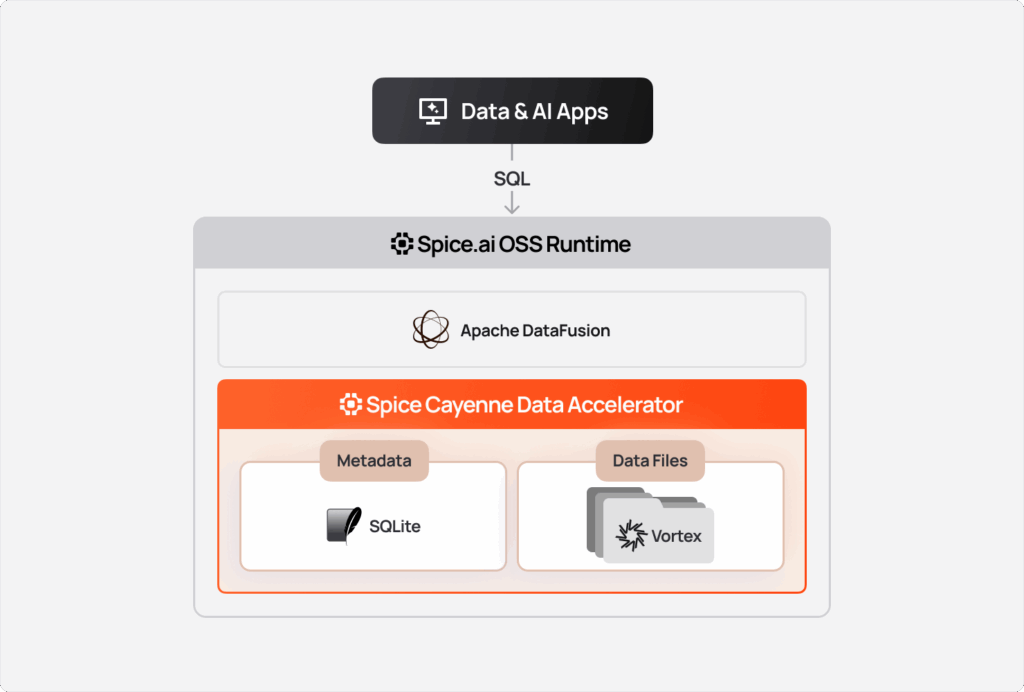
With that context, let's zoom in to some of the specifics of our implementation.
SessionState Configuration
DataFusion's SessionState holds all configuration for query execution.
Key configuration choices:
- PostgreSQL Dialect: We use PostgreSQL syntax to provide a widely supported SQL dialect with consistent, well-understood semantics.
- Case-Sensitive Identifiers: Disabled normalization preserves column case from source systems. While we use the PostgreSQL dialect for syntax, we differ from PostgreSQL's behavior of normalizing identifiers to lower-case.
- Custom Analyzer Rules: Our federation analyzer runs before DataFusion's default rules to ensure we produce valid federated plans. Some default optimizer rules assume a single execution engine and can generate invalid plans for federation, so we intercept early and then selectively apply DataFusion optimizations such as predicate and column pushdown.
Custom TableProvider Implementations
TableProvider is the interface between DataFusion and data sources. We implement it for every connector, but they fall into two distinct categories based on execution model:
SQL-Federated Sources: For these sources (e.g. PostgreSQL, MySQL, DuckDb, and Snowflake), the TableProvider acts primarily as a marker for the federation analyzer to discover. The actual execution doesn't follow DataFusion's normal path - instead, the federation analyzer identifies these tables and replaces them with a simple execution plan that defers computation to the remote source.
Take this query as an example:
SELECT
count(*),
course
FROM duckdb_table
GROUP BY
course;This query is sent almost unchanged to DuckDB, with DataFusion doing minimal work in the middle.
For single-source queries, Spice can often push the SQL down nearly unchanged. When a query spans multiple sources (e.g., JOIN/UNION across tables from different systems), Spice splits the work: it pushes per-source subqueries down, then lets DataFusion combine the results locally (see the SQL Federation section below for details).
Non-Federated Sources: For data lake tables and streaming sources where data is stored in formats like Parquet or Vortex files, all execution happens within DataFusion. Here, the TableProvider implementation is critical; DataFusion directly uses the scan() method to create execution plans, and proper implementation of filter pushdown, projection, and other capabilities directly impacts query performance.
Accelerated dataset architecture
When acceleration is enabled for a dataset, we use a layered TableProvider architecture:
┌─────────────────────────────────────────────────────────┐
│ AcceleratedTable │
│ Wraps federated source with local cache │
│ Handles refresh, fallback, zero-results policies │
├─────────────────────────────────────────────────────────┤
│ Accelerator TableProvider │
│ DuckDB, SQLite, Arrow, Cayenne, PostgreSQL │
├─────────────────────────────────────────────────────────┤
│ FederatedTable │
│ Supports immediate or deferred connection │
│ Enables SQL pushdown to source │
├─────────────────────────────────────────────────────────┤
│ Connector TableProvider │
│ PostgreSQL, Snowflake, S3, DuckDB, etc. │
└─────────────────────────────────────────────────────────┘For non-accelerated datasets, the architecture is simpler; we register the federated TableProvider directly in DataFusion, without the AcceleratedTable layer or accelerator engine.
AcceleratedTable
pub struct AcceleratedTable {
dataset_name: TableReference,
accelerator: Arc<dyn TableProvider>, // Local cache (DuckDB, SQLite, Arrow)
federated: Arc<FederatedTable>, // Source data
zero_results_action: ZeroResultsAction, // Fallback behavior
refresh_mode: RefreshMode, // Full, Append, Changes
}AcceleratedTable provides:
- Local query execution against the accelerator
- Background refresh from the federated source
- Fallback to source when local returns zero results (configurable)
FederatedTable
pub enum FederatedTable {
// TableProvider available immediately
Immediate(Arc<dyn TableProvider>),
// Retries connection in background, serves stale data from checkpoint
Deferred(DeferredTableProvider),
}Deferred mode enables resilient startup. If a source is temporarily unavailable, Spice starts with cached data and retries in the background.
Data Source Coverage
We implement TableProvider for 20+ sources:
| Category | Sources |
|---|---|
| Databases | PostgreSQL, MySQL, SQLite, DuckDB, MongoDB, Oracle, MSSQL, ClickHouse, Turso |
| Warehouses | Snowflake, Databricks, BigQuery, Redshift |
| Lakes | Delta Lake, Iceberg, S3, Azure Blob, GCS |
| Streaming | Kafka, Debezium, DynamoDB Streams |
| APIs | GraphQL, HTTP/REST, GitHub, SharePoint |
| Specialized | FTP/SFTP, SMB/NFS |
SQL Federation
For sources that support SQL (databases, warehouses), we push queries down rather than pulling all data; this means we minimize the work DataFusion does in the middle. The user query is parsed into a LogicalPlan, which the federation analyzer captures and converts (via the DataFusion unparser) into dialect-specific SQL executed directly by the source.
-- User query
SELECT name, SUM(amount) FROM sales
WHERE region = 'NA' AND date > '2024-01-01'
GROUP BY name
-- What we push to Snowflake (via Arrow Flight SQL)
SELECT name, SUM(amount) FROM sales
WHERE region = 'NA' AND date > '2024-01-01'
GROUP BY name
-- Only aggregated results flow over the networkMulti-source query splitting
When a query references multiple federated tables - like a JOIN between Postgres and Snowflake - the federation analyzer rewrites the LogicalPlan into per-source subqueries. Each source executes its portion with filters/projections pushed down, and DataFusion performs the remaining work locally (e.g., join, union, final projection).
Consider this query:
SELECT
o.order_id,
o.order_date,
c.name AS customer_name
FROM postgres.sales.orders o
JOIN snowflake.crm.customers c
ON o.customer_id = c.customer_id
WHERE
o.order_date >= DATE '2025-01-01'
AND c.country = 'KR';The federation analyzer will split this into two queries, one each to Postgres and Snowflake:
Postgres:
SELECT
order_id,
order_date,
customer_id
FROM sales.orders
WHERE order_date >= DATE '2025-01-01';Snowflake:
SELECT
customer_id,
name
FROM crm.customers
WHERE country = 'KR';Federation Architecture
We use the datafusion-federation crate to handle query pushdown. At a high level, this enables DataFusion to identify sub-plans in a query that can be executed by an external system (for example, a database or warehouse), push those sub-plans down for remote execution, and then combine the results locally only when necessary.
This is how Spice can efficiently execute queries that span multiple systems, pushing filters, projections, joins, and aggregates to each source when supported, while handling any cross-source work inside DataFusion.
Future articles will explore Spice's federation architecture in more detail. For readers interested in the underlying framework today, see the datafusion-federation README.
Dialect Translation
Different databases have different SQL dialects. As part of the query pipeline, we first parse the user query into a DataFusion LogicalPlan. The federation analyzer then captures that plan and uses the DataFusion unparser - extended with source-specific dialect rules - to convert it back into SQL that can be executed natively by the underlying system.
We rewrite DataFusion functions into their source-native equivalent:
pub fn new_duckdb_dialect() -> Arc<dyn Dialect> {
DuckDBDialect::new().with_custom_scalar_overrides(vec![
// cosine_distance → array_cosine_distance
(COSINE_DISTANCE_UDF_NAME, Box::new(duckdb::cosine_distance_to_sql)),
// rand() → random()
("rand", Box::new(duckdb::rand_to_random)),
// regexp_like → regexp_matches
(REGEXP_LIKE_NAME, Box::new(duckdb::regexp_like_to_sql)),
])
}Custom Optimizer Rules
DataFusion's optimizer is a pipeline of rules that can rewrite or wrap a logical plan. We extend this pipeline with our own rules for two purposes: (1) semantics-preserving rewrites that produce logically equivalent plans with better execution characteristics, and (2) engine-level behavior that we inject at planning time using the same rule extension point (for example, cache invalidation around DML).
Some examples:
Cache Invalidation Rule
Cache invalidation is not a performance optimization; it's engine logic needed to keep cached results consistent after data changes. We implement it using DataFusion's optimizer rule interface as an extension point: when the planner encounters a DML statement (INSERT, UPDATE, DELETE), we wrap that DML plan in an extension node that triggers invalidation for the affected table(s) after the statement completes.
impl OptimizerRule for CacheInvalidationOptimizerRule {
fn name(&self) -> &'static str {
"cache_invalidation"
}
fn rewrite(
&self,
plan: LogicalPlan,
_config: &dyn OptimizerConfig,
) -> Result<Transformed<LogicalPlan>> {
plan.transform_down(|plan| match plan {
LogicalPlan::Dml(dml) => {
// Wrap DML with cache invalidation node
let node = CacheInvalidationNode::new(
LogicalPlan::Dml(dml),
table_name,
Weak::clone(&self.caching),
);
Ok(Transformed::yes(LogicalPlan::Extension(
Extension { node: Arc::new(node) }
)))
}
_ => Ok(Transformed::no(plan)),
})
}
}DuckDB Aggregate Pushdown
When federation is enabled, aggregate pushdown is normally handled by the federation analyzer. When federation is disabled, those analyzer-based pushdowns do not run, and aggregates would not be pushed down through the standard TableProvider interface. To preserve aggregate pushdown for DuckDB-accelerated tables in that configuration, we apply a DuckDB-specific optimizer rule that recognizes supported aggregate functions and rewrites the plan to execute the aggregation inside DuckDB:
static SUPPORTED_AGG_FUNCTIONS: LazyLock<HashSet<&str>> = LazyLock::new(|| {
HashSet::from([
// Basic aggregates
"avg", "count", "max", "min", "sum",
// Statistical
"corr", "covar_pop", "stddev_pop", "var_pop",
// Boolean
"bool_and", "bool_or",
// Approximate
"approx_percentile_cont",
])
});When enabled, the optimizer rewrites:
-- Original (DataFusion executes aggregate)
SELECT region, SUM(sales) FROM duckdb_table GROUP BY region
-- Rewritten (DuckDB executes aggregate via SQL federation)
SELECT region, SUM(sales) FROM duckdb_table GROUP BY region
-- Pushed as native DuckDB SQLPhysical Optimizer: Empty Hash Join
If we can prove one side of a join is empty at planning time, we skip execution:
impl PhysicalOptimizerRule for EmptyHashJoinExecPhysicalOptimization {
fn optimize(
&self,
plan: Arc<dyn ExecutionPlan>,
_config: &ConfigOptions,
) -> Result<Arc<dyn ExecutionPlan>> {
plan.transform_down(|plan| {
let Some(join) = plan.as_any().downcast_ref::<HashJoinExec>() else {
return Ok(Transformed::no(plan));
};
let is_empty = match join.join_type() {
JoinType::Inner =>
guaranteed_empty(join.left()) || guaranteed_empty(join.right()),
JoinType::Left =>
guaranteed_empty(join.left()),
// ... other join types
};
if is_empty {
Ok(Transformed::yes(Arc::new(EmptyExec::new(join.schema()))))
} else {
Ok(Transformed::no(plan))
}
}).data()
}
}User-Defined Functions
DataFusion supports scalar UDFs, aggregate UDFs, and table-valued functions.
We use all three:
Scalar UDFs
Simple functions that operate on individual values:
use datafusion::common::hash_utils::create_hashes;
pub struct Bucket;
impl ScalarUDFImpl for Bucket {
fn name(&self) -> &'static str {
"bucket"
}
fn signature(&self) -> &Signature {
&Signature::any(2, Volatility::Immutable)
}
fn return_type(&self, arg_types: &[DataType]) -> Result<DataType, DataFusionError> {
Ok(DataType::Int32)
}
fn invoke_with_args(&self, args: ScalarFunctionArgs) -> Result<ColumnarValue, DataFusionError /> {
let args = args.args;
let num_args = args.len();
if num_args != 2 {
return Err(BucketError::InvalidArgumentCount { count: args.len() }.into());
}
let num_buckets = match &args[0] {
ColumnarValue::Scalar(ScalarValue::Int64(Some(n))) => {
if *n <= 0 || *n > MAX_NUM_BUCKETS {
return Err(BucketError::InvalidNumBuckets { num_buckets: *n }.into());
}
*n
}
arg => {
return Err(BucketError::InvalidFirstArgType {
description: describe_columnar_value(arg),
}
.into());
}
};
match &args[1] {
ColumnarValue::Scalar(scalar) => {
let bucket = compute_bucket(scalar, num_buckets)?;
Ok(ColumnarValue::Scalar(bucket))
}
ColumnarValue::Array(array) => {
let buckets = compute_bucket_array(array, num_buckets)?;
Ok(ColumnarValue::Array(Arc::new(buckets)))
}
}
}
}
fn compute_bucket(scalar: &ScalarValue, num_buckets: i64) -> Result<ScalarValue, DataFusionError> {
if scalar.is_null() {
return Ok(ScalarValue::Int32(None));
}
let array = scalar.to_array()?;
let mut hashes = vec![0; 1];
create_hashes(&[array], &RANDOM_STATE, &mut hashes)?;
Ok(ScalarValue::Int32(Some(
u64::try_from(num_buckets)
.and_then(|n| i32::try_from(hashes[0] % n))
.context(BucketLargerThanTypeSnafu)?,
)))
}Async Scalar UDFs for AI
LLM calls are async. DataFusion's AsyncScalarUDFImpl trait enables this:
pub struct Ai {
model_store: Arc<RwLock<ChatModelStore>>,
}
#[async_trait]
impl AsyncScalarUDFImpl for Ai {
fn name(&self) -> &str { "ai" }
async fn invoke_async(
&self,
args: ScalarFunctionArgs,
) -> DataFusionResult<ColumnarValue /> {
let prompt = extract_string(&args.args[0])?;
let model_name = extract_string(&args.args[1])?;
let model = self.model_store.read().get(&model_name)?;
let response = model.complete(&prompt).await?;
Ok(ColumnarValue::Scalar(ScalarValue::Utf8(Some(response))))
}
}Example usage:
SELECT ai('Summarize this text: ' || content, 'gpt-4') as summary
FROM documentsTable-Valued Functions
impl TableFunctionImpl for VectorSearchTableFunc {
fn call(&self, args: &[Expr]) -> DataFusionResult<Arc<dyn TableProvider>> {
let parsed = Self::parse_args(args)?;
let df = self.df.upgrade().context("Runtime dropped")?;
let table = df.get_table_sync(&parsed.table)?;
let embedding_table = find_embedding_table(&table)?;
Ok(Arc::new(VectorSearchUDTFProvider {
args: parsed,
underlying: table,
embedding_models: embedding_table.embedding_models,
}))
}
}Example usage:
SELECT * FROM vector_search(
'documents',
'embedding_column',
'search query text',
10 -- top k
)UDF Registration
pub async fn register_udfs(runtime: &crate::Runtime) {
let ctx = &runtime.df.ctx;
// Scalar UDFs
ctx.register_udf(CosineDistance::new().into());
ctx.register_udf(Bucket::new().into());
ctx.register_udf(Truncate::new().into());
// Async UDFs for AI
#[cfg(feature = "models")]
{
ctx.register_udf(Embed::new(runtime.embeds()).into());
ctx.register_udf(
Ai::new(runtime.completion_llms())
.into_async_udf()
.into_scalar_udf(),
);
}
// Table-valued functions
ctx.register_udtf("vector_search", Arc::new(VectorSearchTableFunc::new(...)));
ctx.register_udtf("text_search", Arc::new(TextSearchTableFunc::new(...)));
}Physical Execution Extensions
Sometimes we need custom execution behavior beyond logical planning:
FallbackOnZeroResultsScanExec
If an accelerated table returns zero rows, optionally fall back to the source:
pub struct FallbackOnZeroResultsScanExec {
input: Arc<dyn ExecutionPlan>,
fallback_table_provider: FallbackAsyncTableProvider,
fallback_scan_params: TableScanParams,
}
impl ExecutionPlan for FallbackOnZeroResultsScanExec {
fn execute(
&self,
partition: usize,
context: Arc<TaskContext>,
) -> DataFusionResult<SendableRecordBatchStream> {
let input_stream = self.input.execute(partition, context.clone())?;
// Wrap stream to detect zero results and trigger fallback
Ok(Box::pin(FallbackStream::new(
input_stream,
self.fallback_table_provider.clone(),
self.fallback_scan_params.clone(),
context,
)))
}
}SchemaCastScanExec
SchemeCastScanExec handles type representation differences across systems during streaming. Different systems represent the same logical types differently. For example, SQLite only supports 5 types while Arrow has 30+ types. SchemaCastScanExec maps between these type system differences as data streams through DataFusion, ensuring type compatibility across connectors:
pub struct SchemaCastScanExec {
input: Arc<dyn ExecutionPlan>,
target_schema: SchemaRef,
}
impl ExecutionPlan for SchemaCastScanExec {
fn execute(...) -> DataFusionResult<SendableRecordBatchStream> {
let input_stream = self.input.execute(partition, context)?;
Ok(Box::pin(SchemaCastStream::new(
input_stream,
Arc::clone(&self.target_schema),
)))
}
}Extension Planners
Custom logical plan nodes need physical planners:
pub fn default_extension_planners() -> Vec<Arc<dyn ExtensionPlanner>> {
vec![
Arc::new(IndexTableScanExtensionPlanner::new()),
Arc::new(FederatedPlanner::new()),
Arc::new(CacheInvalidationExtensionPlanner::new()),
#[cfg(feature = "duckdb")]
DuckDBLogicalExtensionPlanner::new(),
]
}Our DataFusion fork and contributions
Building Spice on Apache DataFusion meant moving quickly at layers of the engine that are still actively evolving upstream. Very early on, we made a deliberate decision to maintain a fork of DataFusion rather than treat it as a fixed dependency. We maintain a fork of DataFusion at spiceai/datafusion:
datafusion = { git = "https://github.com/spiceai/datafusion", rev = "10b5cc5" }The benefits of maintaining our own fork include:
Faster iteration: We can ship features before they're merged upstream. Some patches are tightly coupled to Spice-specific concepts-federation semantics, acceleration policies, or execution behaviors that don't generalize cleanly to other DataFusion users. Keeping those changes in our fork lets us move fast without forcing premature abstractions into the core engine.
Predictable stability: We control when we rebase, when we absorb breaking changes, and how we roll out upgrades. This is critical for a production system that spans dozens of connectors and execution paths.
That said, we work hard to avoid drifting away from the community. When improvements are broadly useful-bug fixes, performance optimizations, clearer APIs, or missing documentation-we contribute them back upstream. We stay close to DataFusion's main branch and regularly rebase our fork, treating upstream not as an external dependency but as a shared foundation we help maintain.
Lessons learned from building on DataFusion
After building Spice on top of DataFusion in production for multiple years, a few patterns and lessons have consistently stood out:
1. TableProvider is incredibly powerful: The TableProvider abstraction lets us add any data source without modifying DataFusion. We've implemented 20+ connectors this way.
2. Optimizer rules compose well: Each rule does one thing. Cache invalidation, aggregate pushdown, and empty join elimination all coexist without conflicts.
3. Physical planning is the escape hatch: When logical transformations aren't enough, custom ExecutionPlan implementations let us do anything - fallback streams, schema casting, managed runtimes.
4. Schema metadata is your friend: Arrow schema metadata flows through the entire pipeline. We use it for:
- Source tracking (which connector)
- Acceleration status (accelerated vs. federated)
- Optimization hints (enable aggregate pushdown)
5. Async UDFs open new possibilities: DataFusion's async UDF support enables SQL-embedded AI:
SELECT ai('Summarize: ' || text) FROM articlesThis wouldn't be possible with synchronous-only UDFs.
6. Federation requires dialect awareness: Different databases have different SQL. Plan for dialect translation from the start, not as an afterthought.
Conclusion
Apache DataFusion is the foundation of Spice's query engine: parsing, planning, optimization, and execution all delivered entirely in Rust, with native Arrow memory and vectorized execution. Its design lets us extend the engine at every layer, adding custom table providers, optimizer rules, and execution operators without rewriting or wrapping the core.
DataFusion isn't just a fast SQL engine - it's a programmable query compiler. Stable extension points like TableProvider, OptimizerRule, ExecutionPlan, and ScalarUDFImpl allow us to express federation, acceleration, search, and AI inference inside the planner and runtime, not as external systems. By building on these abstractions and contributing improvements back upstream, we get a production-grade engine that evolves with our needs rather than constraining them.
If you have further questions about our implementation or are interested in learning more about the Spice platform, join us on Slack.
References
Frequently Asked Questions
What is Apache DataFusion?
Apache DataFusion is an extensible SQL query engine written in Rust that uses Apache Arrow as its in-memory columnar format. It provides SQL parsing, query planning, optimization, and execution, and is designed to be embedded into other systems via well-defined extension points like TableProvider, OptimizerRule, and ExecutionPlan.
How does Spice AI use Apache DataFusion?
Spice uses DataFusion as its core query engine for parsing SQL, planning queries, optimizing execution, and running federated queries across 30+ data sources. Spice extends DataFusion with custom table providers for SQL federation, optimizer rules for acceleration routing, UDFs for hybrid search and LLM inference, and physical operators for schema casting and fallback streams.
What are DataFusion TableProviders?
TableProviders are DataFusion's abstraction for data sources. Each TableProvider implements methods to describe the table schema, report statistics, and produce execution plans. Spice uses custom TableProviders to connect to databases like PostgreSQL, DynamoDB, Snowflake, and Iceberg catalogs, enabling federated SQL queries across all of them.
Can DataFusion handle federated queries across multiple databases?
Yes. Through DataFusion's TableProvider interface and custom optimizer rules, Spice routes queries to remote databases via predicate and projection pushdown, executes portions of queries at the source, and combines results locally. This enables joining data across PostgreSQL, S3, Snowflake, and other sources in a single SQL query.
Does Spice contribute back to the Apache DataFusion project?
Yes. Spice maintains a fork of DataFusion for rapid iteration but regularly contributes improvements back upstream, including bug fixes, performance optimizations, and API enhancements. The team treats upstream DataFusion as a shared foundation rather than an external dependency.
Explore more Spice resources
Hands-on tutorials, product docs, and real-world examples.
A Developer’s Guide to Understanding Spice.ai
This guide helps developers build a mental model of why, how, and where to use Spice.

Spice Cloud v1.11: Spice Cayenne Reaches Beta, Apache DataFusion v51, DynamoDB Streams Improvements, & More
Spice Cloud v1.11 focuses on what matters most in production: faster queries, lower memory usage, and predictable performance across acceleration and caching.

Real-Time Control Plane Acceleration with DynamoDB Streams
How to sync DynamoDB data to thousands of nodes with sub-second latency using a two-tier architecture with DynamoDB Streams and Spice acceleration.

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer