Announcing Spice.ai Open Source 1.0-stable: A Portable Compute Engine for Data-Grounded AI - Now Ready for Production
Spice AI
Spice OSS

Luke Kim
Founder and CEO of Spice AIJanuary 22, 2025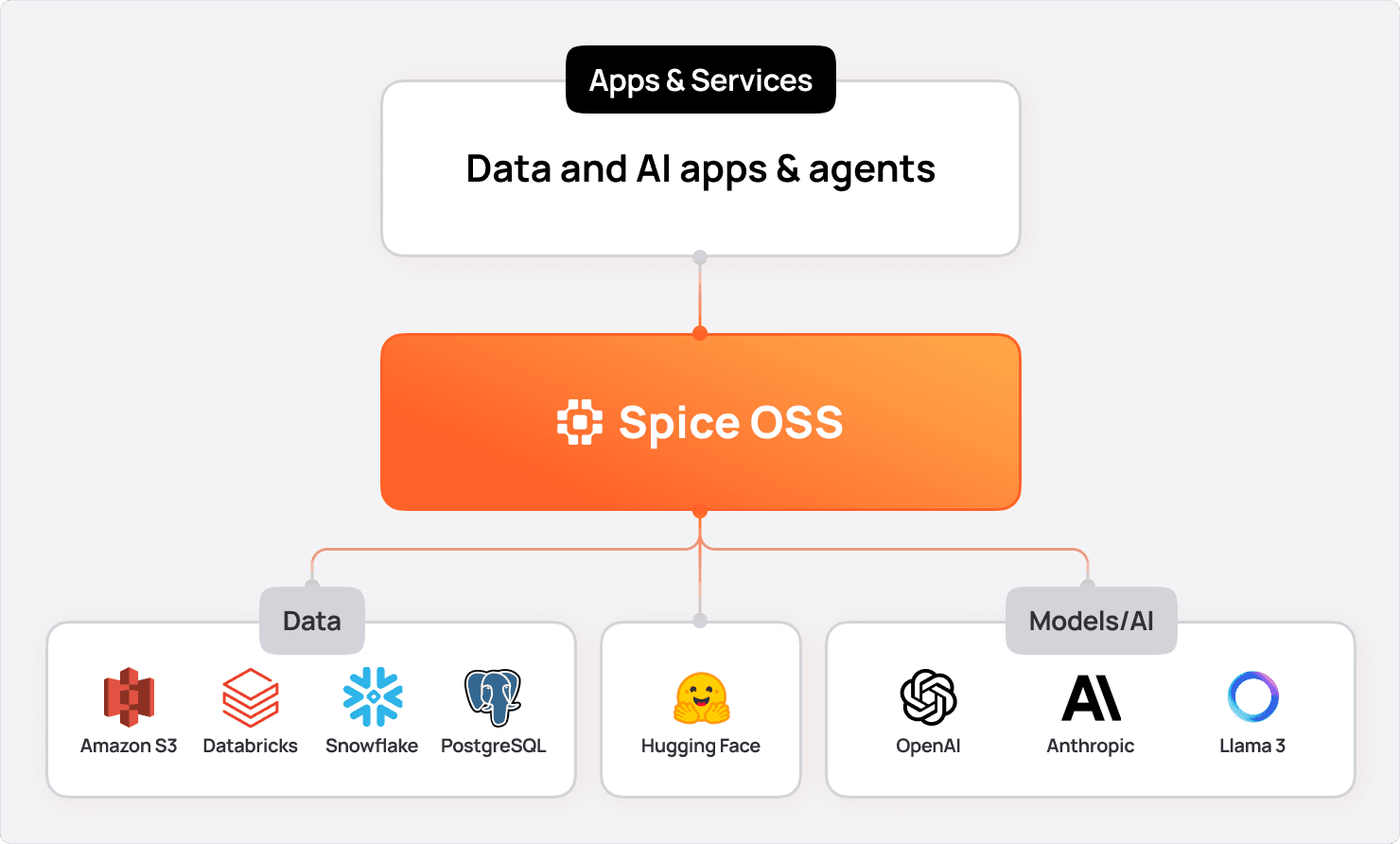
Today marks the 1.0-stable release of Spice.ai Open Source-purpose-built to help enterprises ground AI in data. By unifying federated data query, retrieval, and AI inference into a single engine, Spice mitigates AI hallucinations, accelerates data access for mission-critical workloads, and makes it simple and easy for developers to build fast and accurate data-intensive applications across cloud, edge, or on-prem.
Enterprise AI systems are only as good as the context they're provided. When data is inaccessible, incomplete, or outdated, even the most advanced models can generate outputs that are inaccurate, misleading, or worse, potentially harmful. In one example, a chatbot was tricked into selling a 2024 Chevy Tahoe for $1 due to a lack of contextual safeguards. For enterprises, errors like these are unacceptable-it's the difference between success and failure.
Retrieval-Augmented Generation (RAG) is part of the answer - but traditional RAG is only as good as the data it has access to. If data is locked away in disparate, often legacy data systems, or cannot be stitched together for accurate retrieval, you get, as Benioff puts it, "Clippy 2.0".
And often, after initial Python-scripted pilots, you're left with a new set of problems: How do you deploy AI that meets enterprise requirements for performance, security, and compliance while being cost efficient? Directly querying large datasets for retrieval is slow and expensive. Building and maintaining complex ETL pipelines requires expensive data teams that most organizations don't have. And because enterprise data is highly sensitive, you need secure access and auditable observability-something many RAG setups don't even consider.
Developers need a platform at the intersection of data and AI-one specifically designed to ground AI in data. A solution that unifies data query, search, retrieval, and model inference-ensuring performance, security, and accuracy so you can build AI that you and your customers can trust.
Spice.ai OSS: A portable data, AI, and retrieval engine
In March of 2024, we introduced Spice.ai Open Source, a SQL query engine to materialize and accelerate data from any database, data warehouse, or data lake so that data can be accessed wherever it lives across the enterprise - consistently fast. But that was only the start.
Building on this foundation, Spice.ai OSS unifies data, retrieval, and AI, to provide current, relevant context to mitigate AI "hallucinations" and significantly reduce incorrect outputs-just one of the many mission-critical use cases Spice.ai addresses.
Spice is a portable, single-node, compute engine built in Rust. It embeds the fastest single-node SQL query engine, DataFusion, to serve secure, virtualized data views to data-intensive apps, AI, and agents. Sub-second data query is accelerated locally using Apache Arrow, DuckDB, or SQLite.
Now at version 1.0-stable, Spice is ready for production. It's already deployed in enterprise use at Twilio, Barracuda Networks, and NRC Health, and can be deployed anywhere-cloud-hosted, BYOC, edge, on-prem.

Data-grounded AI
Data-grounded AI anchors models in accurate, current, and domain-specific data, rather than relying solely on pre-trained knowledge. By unifying enterprise data-across databases, data lakes, and APIs-and applying advanced ingestion and retrieval techniques, these systems dynamically incorporate real-world context at inference time without leaking sensitive information. This approach helps developers minimize hallucinations, reduce operational risk, and build trust in AI by delivering reliable, relevant outputs.
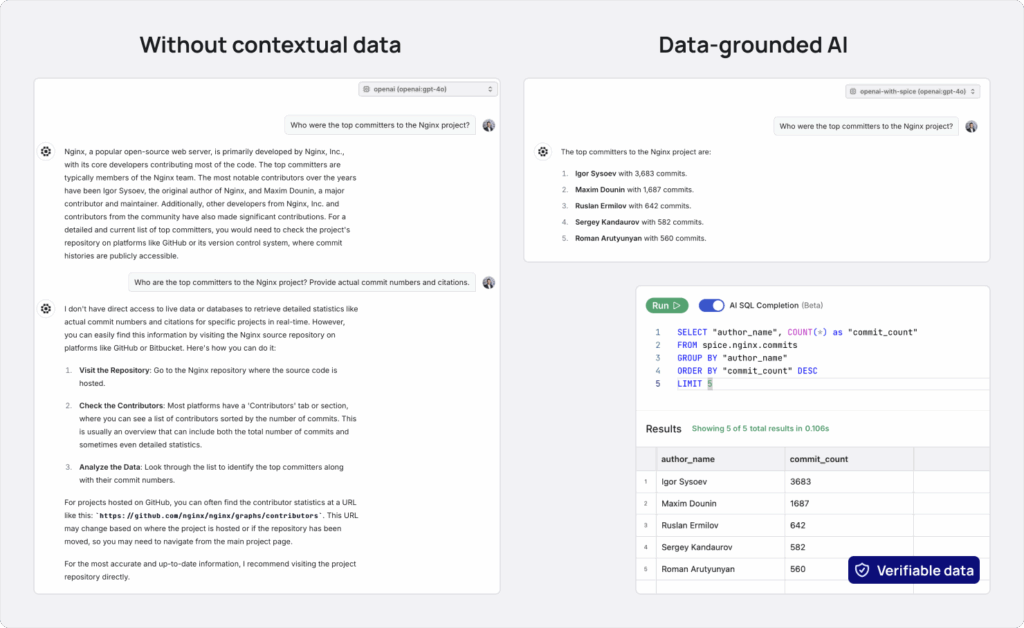
How does Spice.ai OSS solve data-grounding?
With Spice, models always have access to materializations of low-latency, real-time data for near-instant retrieval, minimizing data movement while enabling AI feedback so apps and agents can learn and adapt over time. For example, you can join customer records from PostgreSQL with sales data in Snowflake and logs stored in S3-all with a single SQL query or LLM function call.
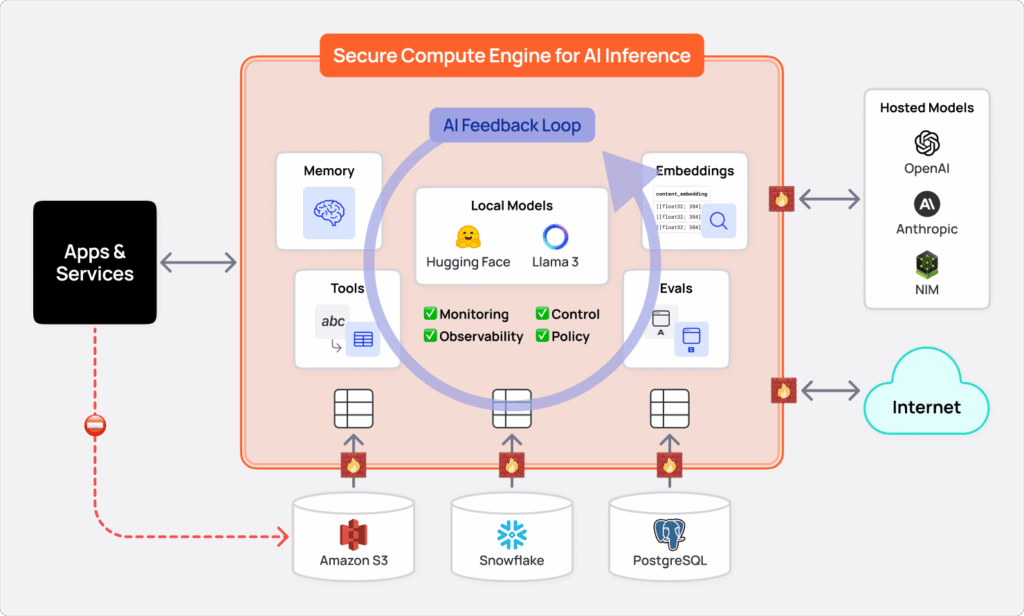
Spice includes an advanced suite of LLM tools including vector and hybrid search, text-to-SQL, SQL query and retrieval, data sampling, and context formatting-all purpose-built for accurate outputs.
The latest research is continually incorporated so that teams can focus on business objectives rather than trying to keep up with the incredibly fast-moving and often overwhelming space of AI.
Spice.ai OSS: The engine that makes AI work
Spice.ai OSS is a lightweight, portable runtime (single ~140 MB binary) with the capabilities of a high-speed cloud data warehouse built into a self-hostable AI inference engine, all in a single, run-anywhere package.
It's designed to be distributed and integrated at the application level, rather than being a bulky, centralized system to manage, and is often deployed as a sidecar. Whether running one Spice instance per service or one for each customer, Spice is flexible enough to fit your application architecture.
Apps and agents integrate with Spice.ai OSS via three industry-standard APIs, so that it can be adopted incrementally with minimal changes to applications.
- SQL Query APIs: HTTP, Arrow Flight, Arrow Flight SQL, ODBC, JDBC, and ADBC.
- OpenAI-Compatible APIs: HTTP APIs compatible with the OpenAI SDK, AI SDK with local model serving (CUDA/Metal accelerated), and gateway to hosted models.
- Iceberg Catalog REST APIs: A unified Iceberg Catalog REST API.
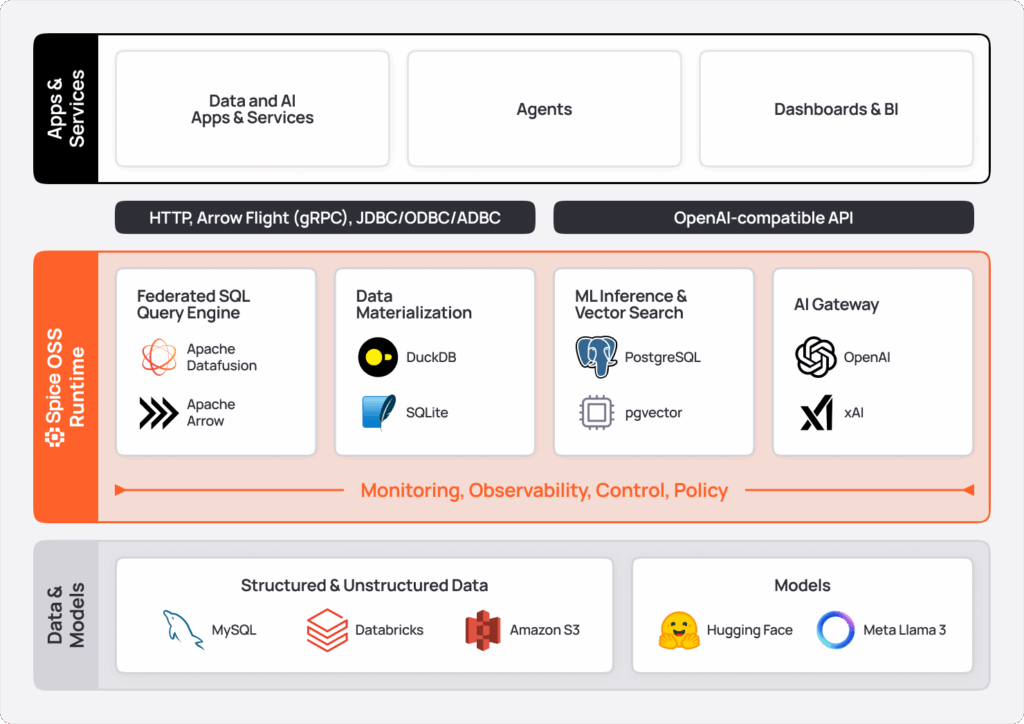
Key features of Spice.ai OSS include:
- Federated SQL Query Across Data Sources: Perform SQL queries across disparate data sources with over 25 open-source data connectors, including catalogs (Unity Catalog, Iceberg Catalog, etc), databases (PostgreSQL, MySQL, etc.), data warehouses (Snowflake, Databricks, etc.), and data lakes (e.g., S3, ABFS, MinIO, etc.).
- Data Materialization and Acceleration: Locally materialize and accelerate data using Arrow, DuckDB, SQLite, and PostgreSQL, enabling low-latency and high-speed transactional and analytical queries. Data can be ingested via Change-Data-Capture (CDC) using Debezium, Catalog integrations, on an interval, or by trigger.
- AI Inference, Gateway, and LLM toolset: Load and serve models like Llama3 locally, or use Spice as a gateway to hosted AI platforms including OpenAI, Anthropic, xAI, and NVidia NIM. Automatically use a purpose-built LLM toolset for data-grounded AI.
- Enterprise Search and Retrieval: Advanced search capabilities for LLM applications, including vector-based similarity search and hybrid search across structured and unstructured data. Real-time retrieval grounds AI applications in dynamic, contextually relevant information, enabling state-of-the-art RAG.
- LLM Memory: Enable long-term memory for LLMs by efficiently storing, retrieving, and updating context across interactions. Support real-time contextual continuity and grounding for applications that require persistent and evolving understanding.
- LLM Evaluations: Test and boost model reliability and accuracy with integrated LLM-powered evaluation tools to assess and refine AI outputs against business objectives and user expectations.
- Monitoring and Observability: Ensure operational excellence with telemetry, distributed tracing, query/task history, and metrics, that provide end-to-end visibility into data flows and model performance in production.
- Deploy Anywhere; Edge-to-Cloud Flexibility: Deploy Spice as a standalone instance, Kubernetes sidecar, microservice, or scalable cluster, with the flexibility to run distributed across edge, on-premises, or any cloud environment. Spice AI offers managed, cloud-hosted deployments of Spice.ai OSS through the Spice Cloud Platform (SCP).
Real-world use-cases
Spice delivers data readiness for teams like Twilio and Barracuda, and accelerates time-to-market of data-grounded AI, such as with developers on GitHub and at NRC Health.
Here are some examples of how Spice.ai OSS solves real problems for these teams.
CDN for Databases - Twilio
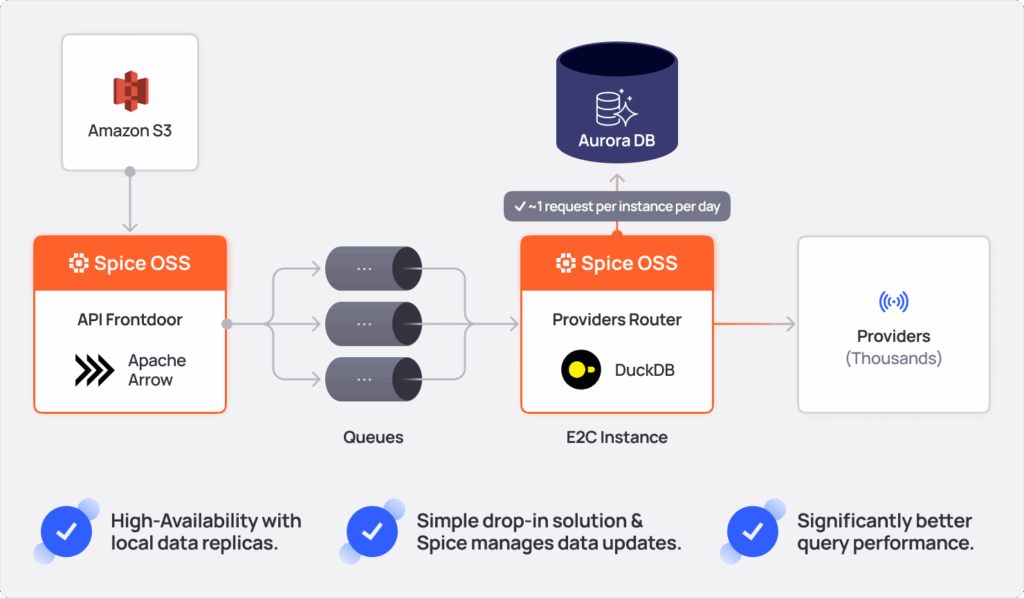
A core requirement for many applications is consistently fast data access, with or without AI. Twilio uses Spice.ai OSS as a data acceleration framework or Database CDN, staging data in object-storage that's accelerated with Spice for sub-second query to improve the reliability of critical services in its messaging pipelines. Before Spice, a database outage could result in a service outage.
Spice opened the door to take these critical control-plane datasets and move them next to our services in the runtime path.
Peter Jaovsky
Software Architect at Twilio
With Spice, Twilio has achieved:
- Significantly Improved Query Performance: Used Spice to co-locate control-plane data in the messaging runtime, accelerated with DuckDB, to send messages with a P99 query time of < 5ms.
- Low-Latency Multi-Tenancy Controls: Spice is integrated into the message-sending runtime to manage multi-tenancy data controls. Before, data changes required manual triggers and took hours to propagate. Now, they update automatically and reach the messaging front door within five minutes via a resilient data-availability framework.
- Mission-Critical Reliability: Reduced reliance on queries to databases by using Spice to accelerate data in-memory locally, with automatic failover to query data directly from S3, ensuring uninterrupted service even during database downtime.
With a simple drop in container, we are able to double our data redundancy by using Spice.
David Blum
Principal Software Engineer at Twilio
Datalake Accelerator - Barracuda
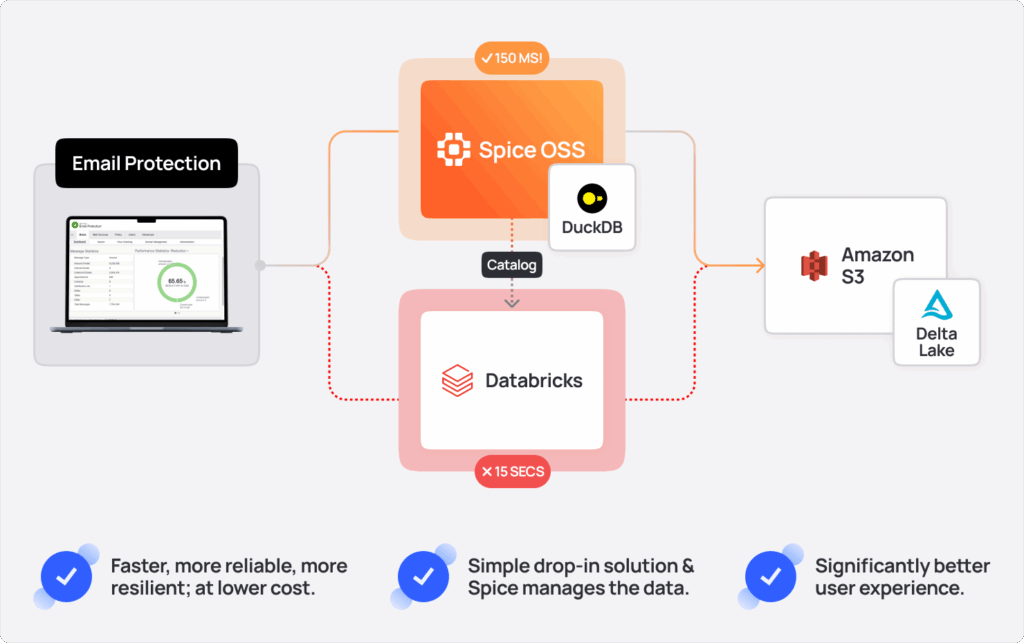
Barracuda uses Spice.ai OSS to modernize data access for their email archiving and audit log systems, solving two big problems: slow query performance and costly queries. Before Spice, customers experienced frustrating delays of up to two minutes when searching email archives, due to the data volume being queried.
It's just a huge gain in responsiveness for the customer.
David Stancu
Senior Principal Software Engineer at Barracuda
With Spice, Barracuda has achieved:
- Significant Cost Reduction: Replaced expensive Databricks Spark queries, significantly cutting expenses while improving performance.
- 100x Query Performance Improvement: Accelerated email archive queries from a P99 time of 2 minutes to 100-200 milliseconds.
- Efficient Audit Logs: Offloaded audit logs to Parquet files in S3, queried directly by Spice.
- Mission-Critical Reliability: Reduced load on Cassandra, improving overall infrastructure stability.
It just spins up and it just works, which is really nice.
Darin Douglass
Principal Software Engineer at Barracuda
Data-Grounded AI apps and agents - NRC Health
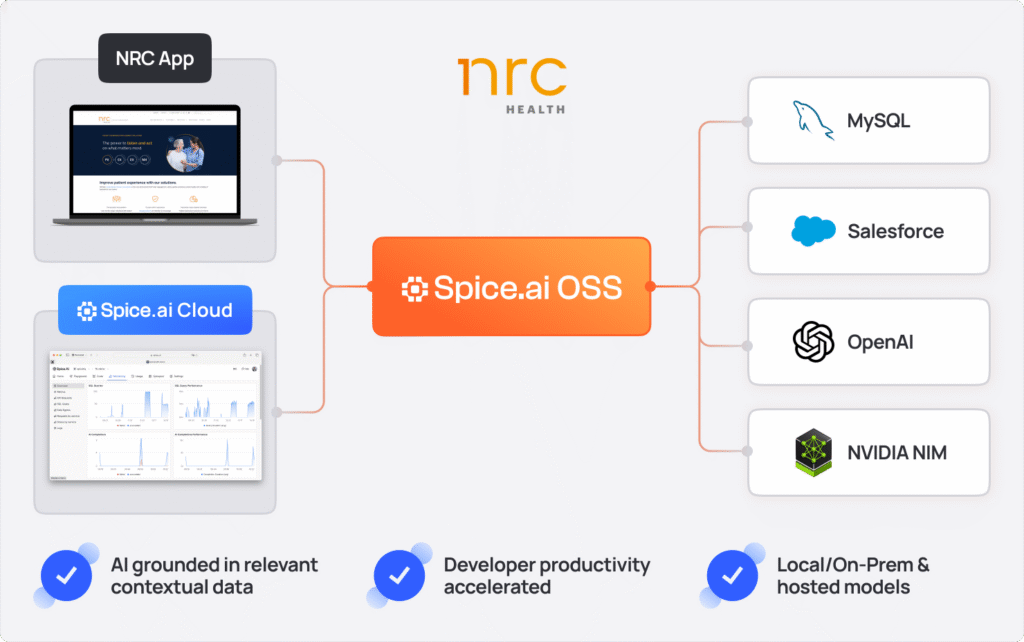
NRC Health uses Spice.ai OSS to simplify and accelerate the development of data-grounded AI features, unifying data from multiple platforms including MySQL, SharePoint, and Salesforce, into secure, AI-ready data. Before Spice, scaling AI expertise across the organization to build complex RAG-based scenarios was a challenge.
What I like the most about Spice, it's very easy to collect data from different data sources and I am able to chat with this data and do everything in one place.
Dustin Warner
Director of Software Engineering at NRC Health
With Spice OSS, NRC Health has achieved:
- Developer Productivity: Partnered with Spice in three company-wide AI hackathons to build complete end-to-end data-grounded AI features in hours instead of weeks or months.
- Accelerated Time-to-Market: Centralized data integration and AI model serving an enterprise-ready service, accelerating time to market.
Data-Grounded AI Software Development - Spice.ai GitHub Copilot Extension
When using tools like GitHub Copilot, developers often face the hassle of switching between multiple environments to get the data they need.
The Spice.ai for GitHub Copilot Extension built on Spice.ai OSS, gives developers the ability to connect data from external sources to Copilot, grounding Copilot in relevant data not generally available in GitHub, like test data stored in a development database.
Developers can simply type @spiceai to interact with connected data, with relevant answers now surfaced directly in Copilot Chat, significantly improving productivity.
Why choose Spice.ai OSS?
Adopting Spice.ai OSS addresses real challenges in modern AI development: it grounds models in accurate, domain-specific, real-time data. With Spice, engineering teams can focus on what matters-delivering innovative, accurate, AI-powered applications and agents that work. Additionally, Spice.ai OSS is open-source under Apache 2.0, ensuring transparency and extensibility so your organization remains free to innovate without vendor lock-in.
Get started in 30 seconds
You can install Spice.ai OSS in less than a minute, on macOS, Linux, and Windows.
macOS, Linux, and WSL:
curl https://install.spiceai.org | /bin/bashOr using brew:
brew install spiceai/spiceai/spiceWindows:
curl -L "https://install.spiceai.org/Install.ps1" -o Install.ps1 && PowerShell -ExecutionPolicy Bypass -File ./Install.ps1Once installed, follow the Getting Started with Spice.ai guide to ground OpenAI chat with data from S3 in less than 2 minutes.
Looking ahead
The 1.0-stable release of Spice.ai OSS marks a major step toward accurate AI for developers. By combining data, AI, and retrieval into a unified runtime, Spice anchors AI in relevant, real-time data-helping you build apps and agents that work.
A cloud-hosted, fully managed Spice.ai OSS service is available in the Spice Cloud Platform. It's SOC 2 Type II compliant and makes it easy to operate Spice deployments.
Beyond apps and agents, the vision for Spice is to be the best digital labor platform for building autonomous AI employees and teams. These are exciting times! Stay tuned for some upcoming announcements later in 2025!
The Spice AI Team
Learn more
- Cookbook: 47+ samples and examples using Spice.ai OSS
- Documentation: Learn about features, use cases, and advanced configurations
- X: Follow @spice_ai on X for news and updates
- Slack: Connect with the team and the community
- GitHub: Star the repo, contribute, and raise issues
Frequently Asked Questions
What is Spice.ai OSS 1.0-stable?
Spice.ai OSS 1.0-stable is the production-ready release of Spice, an open-source, portable compute engine built in Rust. It unifies SQL federation, hybrid search, and AI inference into a single lightweight runtime (~140 MB binary) that can be deployed anywhere from edge to cloud.
How does Spice ground AI in data?
Spice mitigates AI hallucinations by providing models with access to materializations of low-latency, real-time data from across the enterprise. Rather than relying solely on pre-trained knowledge, Spice enables retrieval-augmented generation by federating queries across databases, data warehouses, and data lakes so models receive accurate, current context at inference time.
How is Spice different from a data warehouse like Snowflake or Databricks?
Unlike centralized data warehouses that require data movement and introduce cold-start latency, Spice queries data in place with sub-second performance. It is designed for application serving rather than analytics, often deployed as a sidecar alongside production services. See pricing for deployment options.
What real-world results have enterprises achieved with Spice?
Twilio achieved P99 query times under 5 ms using Spice as a Database CDN. Barracuda improved email archive queries by 100x (from 15 seconds to 100-200 ms) while cutting costs by 50 percent with the data lake accelerator pattern. NRC Health accelerated development of data-grounded AI features by centralizing data from MySQL, SharePoint, and Salesforce into a single query layer.
Explore more Spice resources
Tutorials, docs, and blog posts to help you go deeper with Spice.
A Developer’s Guide to Understanding Spice.ai
This guide helps developers build a mental model of why, how, and where to use Spice.

Real-Time Control Plane Acceleration with DynamoDB Streams
How to sync DynamoDB data to thousands of nodes with sub-second latency using a two-tier architecture with DynamoDB Streams and Spice acceleration.

How we use Apache DataFusion at Spice AI
Why we chose to build on DataFusion and how we extended it with custom TableProviders, optimizer rules, and UDFs for federated SQL

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer