Adding Spice - The Next Generation of Spice.ai OSS
Spice AI
Spice OSS

Phillip LeBlanc
Co-Founder and CTO of Spice AIMarch 28, 2024
TL;DR: We've rebuilt Spice.ai OSS from the ground up in Rust, as a unified SQL query interface and portable runtime to locally materialize, accelerate, and query datasets sourced from any database, data warehouse or data lake. Learn more at github.com/spiceai/spiceai.
In September, 2021, we introduced Spice.ai OSS as a runtime for building AI-driven applications using time-series data.
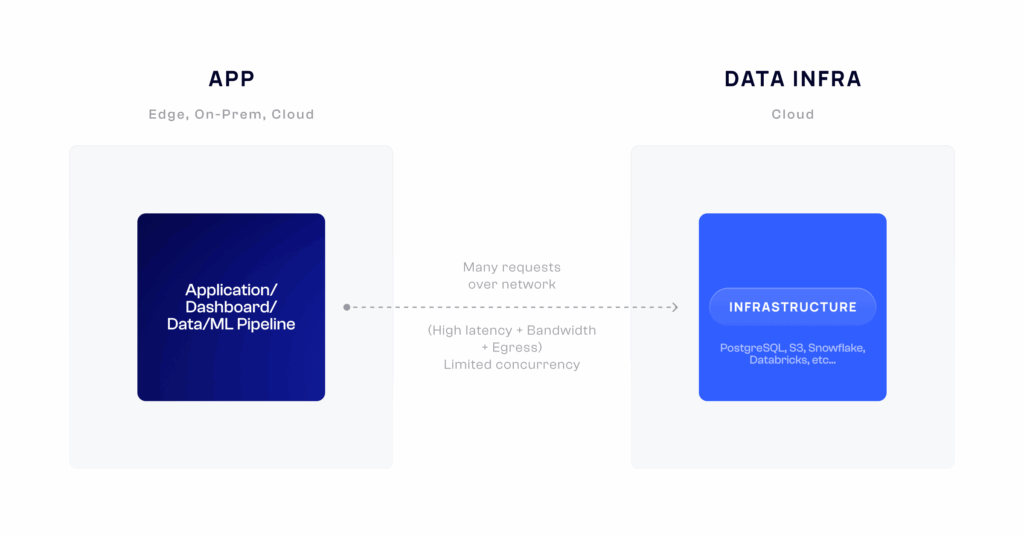
We quickly ran into a big problems in making these applications work... data, the fuel for intelligent software, was painfully difficult to access, operationalize, and use, not only in machine learning, but also in web frontends, backend applications, dashboards, data pipelines, and notebooks. And we had to make hard tradeoffs between cost and query performance.
We felt this pain every day building 100TB+ scale data and AI systems for the Spice.ai Cloud Platform. So we took our learnings and infused them back into Spice.ai OSS with the capabilities we wished we had.
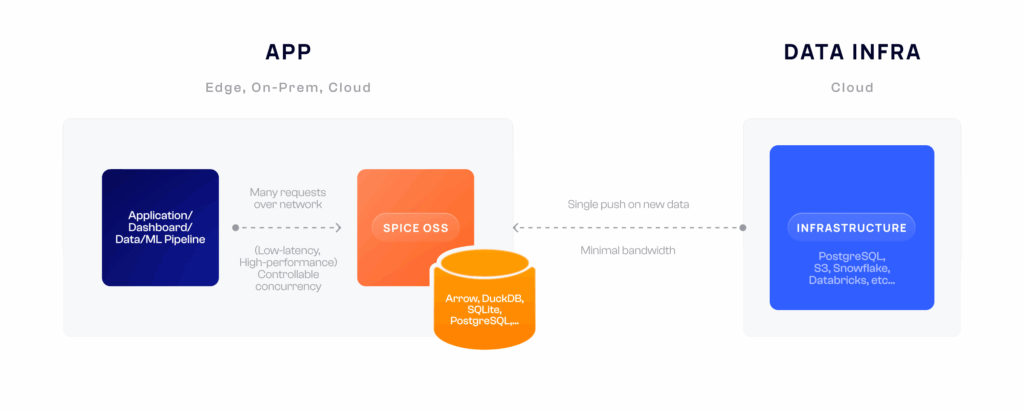
We rebuilt Spice.ai OSS from the ground up in Rust, as a unified SQL query interface and portable runtime to locally materialize, accelerate, and query data tables sourced from any database, data warehouse or data lake.

Spice is a fast, lightweight (< 150 MB), single binary, designed to be deployed alongside your application, dashboard, and within your data or machine learning pipelines. Spice federates SQL queries across databases (MySQL, PostgreSQL, etc.), data warehouses (Snowflake, BigQuery, etc.) and data lakes (S3, MinIO, Databricks, etc.) so you can easily use and combine data wherever it lives. Datasets, declaratively defined, can be materialized and accelerated using your engine of choice, including DuckDB, SQLite, PostgreSQL, and in-memory Apache Arrow records, for ultra-fast, low-latency query. Accelerated engines run in your infrastructure giving you flexibility and control over price and performance.
Before Spice
With Spice
Use-Cases
The next-generation of Spice.ai OSS enables:
Better applications. Accelerate and co-locate data with frontend and backend applications, for high concurrent queries, serving more users with faster page loads and data updates. Try the CQRS sample app.
Snappy dashboards, analytics, and BI. Faster, more responsive dashboards without massive compute costs. Spice supports Arrow Flight SQL (JDBC/ODBC/ADBC) for connectivity with Tableau, Looker, PowerBI, and more. Watch the Apache Superset with Spice demo.
Faster data pipelines, machine learning training and inference. Co-locate datasets with pipelines where the data is needed to minimize data-movement and improve query performance. Predict hard drive failure with the SMART data demo.
Data lake acceleration. Materialize and accelerate data from S3, Delta Lake, or Apache Iceberg for sub-second queries without moving data into a centralized warehouse.
Easily query many data sources. Federated SQL query across databases, data warehouses, and data lakes using Data Connectors.
Community Built
Spice is open-source, Apache 2.0 licensed, and is built using industry-leading technologies including Apache DataFusion, Arrow, and Arrow Flight SQL. We're launching with several built-in Data Connectors and Accelerators and Spice is extensible so more will be added in each release. If you're interested in contributing, we'd love to welcome you to the community!
Getting Started
You can download and run Spice in less than 30 seconds by following the quickstart at spiceai.org/docs/getting-started.
Conclusion
Spice, rebuilt in Rust, introduces a unified SQL query interface, making it simpler and faster to build data-driven applications. The lightweight Spice runtime is easy to deploy and makes it possible to materialize and query data from any source quickly and cost-effectively. Applications can serve more users, dashboards and analytics can be snappier, and data and ML pipelines finish faster, without the heavy lifting of managing data.
For developers this translates to less time wrangling data and more time creating innovative applications and business value.
Check out and star the project on GitHub!
Thank you,
Phillip
Frequently Asked Questions
What is Spice.ai OSS?
Spice.ai OSS is an open-source, portable runtime written in Rust that provides developers with a unified SQL query interface to locally materialize, accelerate, and query datasets sourced from any database, data warehouse, or data lake. It is designed for data-intensive applications that require fast, reliable data access.
How is Spice.ai OSS different from a traditional database or data warehouse?
Rather than replacing your existing databases, Spice sits alongside your application and federates queries across multiple data sources. It materializes working datasets locally for sub-second performance while keeping your source of truth intact.
What programming languages and protocols does Spice support?
Spice exposes data over industry-standard protocols including HTTP, Apache Arrow Flight, and Arrow Flight SQL. This means any language or tool that speaks SQL, Arrow Flight, or ODBC/JDBC can query Spice without custom integration.
To evaluate Spice for your own workloads, review Spice Cloud pricing or get a demo to walk through your architecture with the team.
Explore more Spice resources
Tutorials, docs, and blog posts to help you go deeper with Spice.
A Developer’s Guide to Understanding Spice.ai
This guide helps developers build a mental model of why, how, and where to use Spice.

Real-Time Control Plane Acceleration with DynamoDB Streams
How to sync DynamoDB data to thousands of nodes with sub-second latency using a two-tier architecture with DynamoDB Streams and Spice acceleration.

How we use Apache DataFusion at Spice AI
Why we chose to build on DataFusion and how we extended it with custom TableProviders, optimizer rules, and UDFs for federated SQL

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer