Vortex at Spice AI: The Columnar Format for Data-Intensive Workloads
Spice AI
Spice OSS
Data Acceleration
Engineering

Luke Kim
Founder and CEO of Spice AIApril 7, 2026
TL;DR
Legacy columnar formats decompress data before compute touches it. While often negligible at small scale, this becomes a tax on memory, latency, and CPU as workloads expand.
Vortex is a next-gen open-source columnar format from the Linux Foundation that eliminates that tax. It runs compute kernels directly on encoded data, skipping decompression entirely for many operations. When decompression is needed, data lands directly in Arrow arrays with no intermediate copies.
We built Spice Cayenne on Vortex as the acceleration engine for data-intensive workloads. On TPC-H SF-100, Spice Cayenne runs 1.4x faster than DuckDB file mode and uses 3x less memory, and 14% faster and 3.4x less memory on ClickBench.
This post covers what Vortex is, how it drives Cayenne's performance, and what we learned shipping it.
Introduction
In late 2025, we selected Vortex as the premier columnar format for the Spice.ai platform. It now powers Spice Cayenne in production.
This post explains how we got there and what we learned shipping it:
- What Vortex is and how it differs from Parquet
- Why we chose Vortex for Cayenne's data layer
- How we designed Cayenne's architecture, using Vortex for data files and SQLite/Turso as the metadata store
- Strategies for managing virtual files, deletion vectors, and compression
- Vortex's DataFusion integration
- 7 production lessons from shipping Vortex in Spice Cayenne
Engineering at Spice AI Series
This post is the third installment of our series on the open-source technologies powering Spice.ai:
- Apache DataFusion: SQL query engine foundation
- Apache Iceberg: Open table format integration
Up next:
- Apache Ballista: Distributed query execution
- Rust: Systems programming foundation
- Apache Arrow: Core data format
- DuckDB: Embedded analytics and acceleration
So, What Is Vortex?
Vortex is an open-source columnar file format from the Linux Foundation, built to resolve the tradeoff between compression and query speed that makes existing formats struggle at scale. Vortex delivers 100x faster random access, 10-20x faster full scans, and 5x faster writes than Parquet. It is the product of decades of database research but was built for the present: the access patterns, ingestion rates, and modern AI workloads that existing formats were not designed for.

Source: Vortex
Vortex's architecture separates logical from physical concerns. The logical layer defines types and schema, while the physical layer handles encoding and storage. Each column is encoded independently based on data statistics: dictionary for low-cardinality strings, delta for monotonic integers, bit-packing for small integer ranges. Encodings can nest; for example, a dictionary-encoded column can itself be bit-packed. Beyond these foundational encodings, Vortex also supports FSST (Fast Static Symbol Table) for string compression with O(1) random access, FastLanes for SIMD-vectorized decoding of bit-packed integers, and ALP for adaptive lossless floating-point compression. Files are split into chunks, which enables parallel reads and gives the query engine granular statistics for skipping irrelevant segments before any data I/O happens.
The step function in performance improvement comes where computation happens. Compute kernels operate directly on encoded data, and many operations skip decompression entirely. When decompression is needed, data lands directly in Arrow arrays with no intermediate copies. The kernels are built for modern hardware. Vortex uses AVX2 gather instructions for take operations (with runtime detection and scalar fallback), SIMD-friendly FastLanes bit-packing, and is developing CUDA GPU kernels for filter and slice operations. Finally, Vortex is implemented in Rust, which aligns with Spice's systems stack and keeps memory overhead predictable without a garbage collector.
This design sits at a deliberate point in the compression spectrum, around 0.4x, between Arrow IPC (1.0x, uncompressed) and Parquet (roughly 0.3x). Arrow IPC is fast to read but storage costs scale poorly for large hot datasets. Parquet compresses well, but at high query repetition, 100 queries per second against the same dataset, you decompress the same blocks 100 times.
Vortex resolves those tradeoffs.
How Vortex Fits in Spice's Architecture
Spice is built on four core primitives: data federation, query acceleration, hybrid search, and LLM inference. Combined, they offer a complete data platform for AI context. Vortex sits at the acceleration layer.
Spice accelerates datasets by materializing working sets from distributed sources into local engines. Instead of querying a remote database or object storage bucket on every request, Spice maintains a working set of locally accelerated data and serves queries from there. For application and agent-serving workloads, this is the difference between hundreds of milliseconds and seconds to minutes latency.
A core design principle of Spice is optionality. As such, several acceleration engines are offered to customers to align with use case requirements: Arrow for in-memory speed, DuckDB for analytical workloads, SQLite for small relational tables, and PostgreSQL for workloads that need a full relational engine. Each has a different performance and operational profile, and customers choose based on their use case.
As customers pushed higher data volumes into Spice, three problems with the existing accelerators appeared consistently:
- DuckDB's single-file architecture, serialized concurrent writes, and ingestion under load creates queuing
- Memory overhead grows proportionally with dataset size
- With large enough datasets, the single-file model creates practical size limits
These production limitations reduced the surface area of use cases Spice could support.
Spice Cayenne is the engine built to address those use cases.
Why Vortex for Cayenne?
We needed a storage layer that could handle high write throughput, compress efficiently for hot data, and stay operationally simple.
We evaluated several storage options beyond existing DuckDB and SQLite engines:
| Option | Problem |
|---|---|
| Multiple DuckDB files | Significant resource and operational overhead with limited optimization potential |
| Parquet | Slow decompression for hot data, no native update support, still requires catalog |
| Arrow IPC | Large uncompressed files, expensive to store |
| Nimble & Lance (LV2) | Less adoption and lower performance profile. |
| Iceberg/Delta | Slow, complex metadata management, catalog server requirements |
Vortex solved our key challenges:
| Requirement | Vortex solution |
|---|---|
| DuckDB-like performance and latency profile | Encoding-efficient compression + zero-copy |
| No single-file limits | Multi-file architecture with metadata in SQLite |
| Arrow-native | Direct decompression to Arrow arrays |
| Simple operations | Files + SQL metadata |
| High concurrency | Stage files, then single SQL transaction |
| Extensibility | Every major component is extensible, enabling custom encodings, compression, and layouts |
The benchmarks confirmed the decision. On TPC-H SF-100, Cayenne runs 1.4x faster than DuckDB file mode and uses 3x less memory:
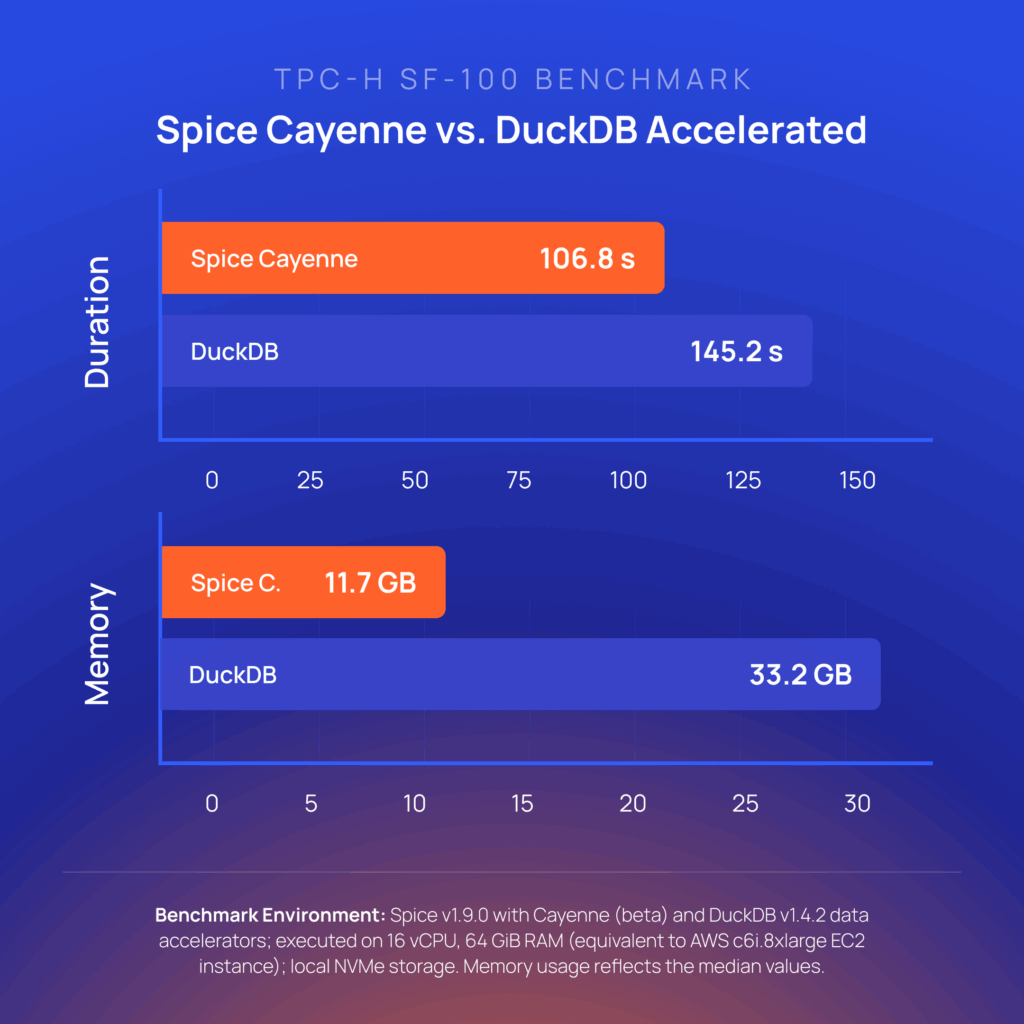
On ClickBench, 14% faster and 3.4x less memory:
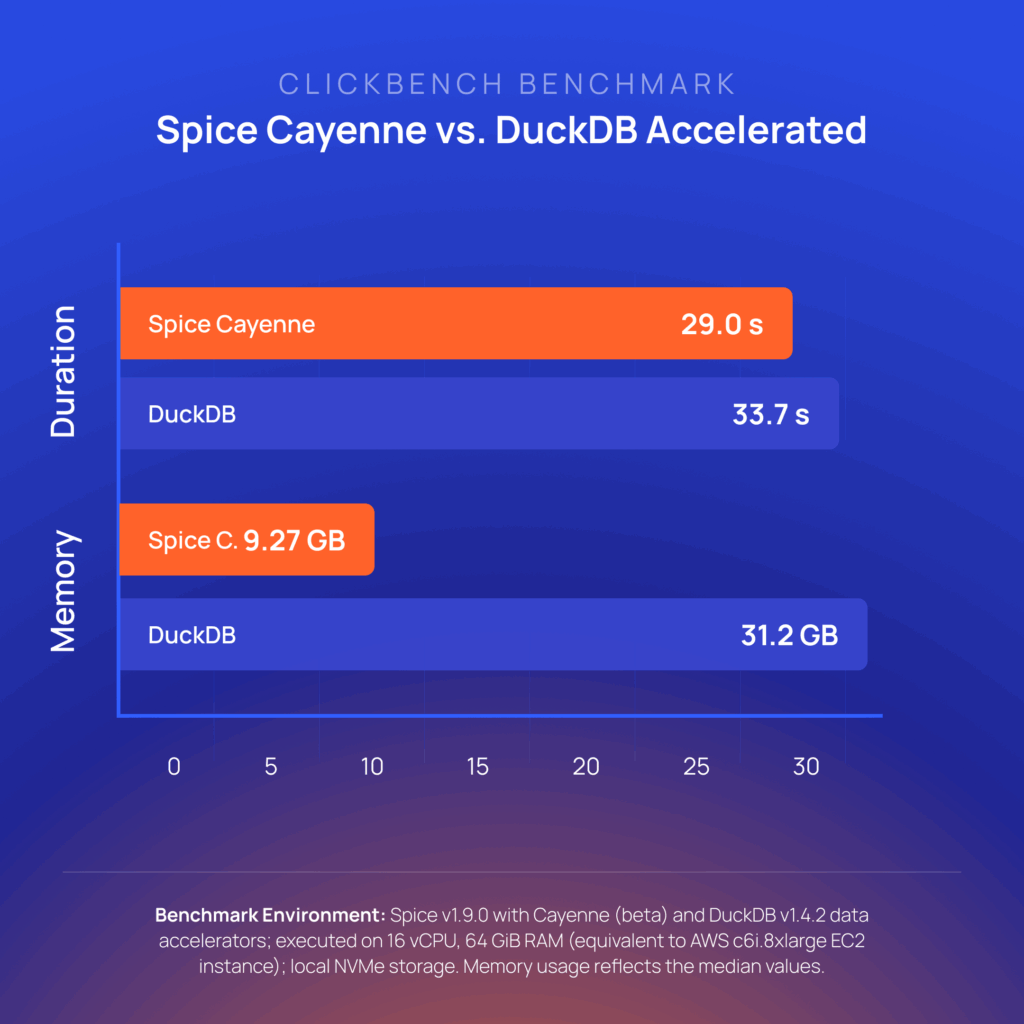
Full results are in the Spice Cayenne launch blog.
Cayenne Architecture
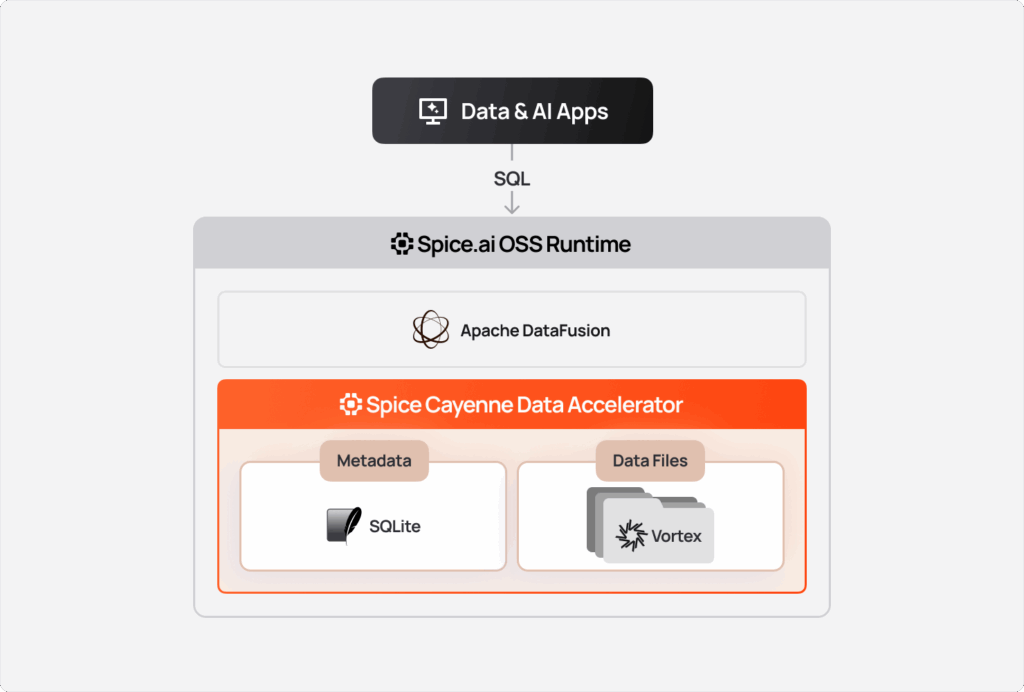
Spice Cayenne uses SQLite as a metadata store and Vortex files for the actual data. This design is also used by the DuckLake architecture: separate the catalog from the data, use a transactional database for metadata, and immutable files for data storage.
While we are agnostic on the choice of metadata provider, the current implementation leverages SQLite (or Turso) because it offers atomic transactions and the ability to store millions of snapshots as rows. A single SQL query retrieves all metadata needed to plan a scan.
Key Design Decisions
Virtual Files: Directories as ListingTables
Each Cayenne snapshot is a directory, not a single physical file. Inside that directory, Vortex manages multiple segment files. DataFusion sees it as a ListingTable over that directory.
This matters for lifecycle management. To delete or expire a snapshot, you drop the directory. New segments write into the directory without blocking reads. Directories are also a natural unit for compaction: write merged data into a new snapshot directory, then atomically swap the metadata pointer and clean up the old one.
Vortex automatically splits writes into multiple chunk files within the directory. The cayenne_target_file_size_mb parameter controls when a new chunk file is created, giving you tunable parallelism and more granular statistics for query optimization. If you frequently filter on a specific column, the sort_columns parameter lets you pre-sort data on ingestion so that segments align with your query patterns, maximizing how many segments get pruned at scan time.
Vortex maintains per-chunk zone map statistics for every column: minimum and maximum values, null count, distinct count, and uncompressed size. These statistics are embedded in Vortex file footers, and the ListingTable aggregates them across all files for DataFusion's query optimizer. When sort_columns is configured, sorted data produces tighter min/max bounds per zone, making pruning more effective. For a table with sorted timestamps, a query filtering on WHERE timestamp > '2024-01-20' skips every zone whose maximum timestamp falls below that threshold before any decompression happens.
Deletion Vectors and Sequence Numbers
Upsert semantics in an immutable file format require a way to mark rows as deleted without rewriting files. Deletion vector metadata (which files exist, their sequence numbers, deletion type, etc.) is stored in the SQLite metastore while deletion vector data is stored as separate Arrow IPC files alongside the data segments.
The key insight behind sequence numbers is that a delete record carries a delete_sequence. That delete only applies to rows where the data sequence is less than the delete sequence. This means you can write new versions of a row without retroactively deleting them. The ordering is self-contained in the metadata.
We support three deletion vector strategies based on table configuration:
| Strategy | Use Case | Implementation |
|---|---|---|
| PositionBased | No Primary key | RoaringBitmap of row positions |
| Int64Pk | Single Int64 primary key | HashMap<i64, i64> direct lookup (PK → delete sequence) |
| RowConverterBased | Composite or non-integer PK | HashMap<Box<[u8]>, i64> via Arrow RowConverter (key bytes → delete sequence) |
The performance characteristics differ significantly. For position-based deletion, the RoaringBitmap is pushed down directly to Vortex's scan layer via Selection::ExcludeRoaring. Deleted rows are skipped during decompression and never materialize as Arrow arrays. The PK-based strategies filter in a DataFusion execution plan node after scanning, but the Int64Pk path uses a SIMD-optimized DeletionIndex, a Swiss table-style hash index with bloom filter that checks 16 slots in parallel on x86, providing O(1) rejection of non-deleted keys before probing the hash table.
Compaction
Deletion vectors accumulate over time. Compaction resolves this by merging data and deletion vectors into a new snapshot. The commit_compaction operation is a single atomic SQLite transaction that updates the snapshot ID, clears all delete files, and resets insert tracking records. After compaction, the old snapshot directory and its deletion vector files can be cleaned up.
For position-based deletion, RoaringBitmap provides 50-90% memory savings over a HashSet for sparse deletions, with SIMD-accelerated contains operations.
Compression Strategies
Vortex supports two compression strategies, configurable per-accelerator.
Btrblocks is the default. It selects the best encoding per column based on data statistics, drawing from a cascade of lightweight encodings: dictionary for low-cardinality strings, delta for monotonic integers, or bit-packing for small integer ranges. The encodings are designed for SIMD execution, so decode is fast.
Zstd is the right choice for cold data you want to store cheaply but do not query frequently. It compresses further than Btrblocks in many cases but decode is slower.
DataFusion Integration
Spice Cayenne plugs into Apache DataFusion as a custom TableProvider. When a query hits a Cayenne table, DataFusion's physical planning calls into Cayenne's scan implementation, which resolves SQLite metadata, identifies which Vortex segments to read, applies deletion vectors, and returns Arrow record batches.
Projection and predicate pushdown work at the Vortex layer. Vortex's per-segment statistics skip segments that cannot satisfy a filter predicate before any decompression happens.
Memory behavior under concurrent load is predictable because Spice uses a DataFusion GreedyMemoryPool wrapped in a TrackConsumersPool that enforces a per-runtime memory ceiling. When a query exceeds runtime.query.memory_limit, DataFusion automatically spills to disk rather than failing, which matters for large analytical queries running alongside ingestion.
For more on how DataFusion fits into Spice's query architecture, see Apache DataFusion at Spice AI.
Distributed Execution: Vortex Shuffles
Vortex extends beyond Cayenne's local storage into Spice's distributed execution layer. Spice integrates Apache Ballista for multi-node distributed queries, and shuffle data between query stages can be serialized in Vortex IPC format instead of the default Arrow IPC.
The shuffle format is configurable at the runtime level. Vortex's encoding-aware compression produces smaller shuffle files than Arrow IPC, reducing network transfer and disk I/O between executors.
Shuffle writer: The VortexWriteTracker converts Arrow RecordBatches to Vortex arrays and serializes them via Vortex IPC. For hash-repartitioned shuffles, each output partition's arrays are buffered independently and serialized to Vortex IPC bytes before uploading to disk or object storage.
Shuffle reader: The reader auto-detects .vortex files and reads them back using SyncIPCReader, converting Vortex arrays to Arrow RecordBatches on the fly. A CoalescedShuffleReaderStream coalesces small batches from shuffle files into target-sized batches for efficient downstream processing.
In-memory shuffles: When shuffle data fits in executor memory, InMemoryShuffleData holds either Arrow RecordBatches or Vortex arrays. For Vortex shuffles, data stays in Vortex encoding between stages, no decompress-recompress cycle.
Flight service integration: Vortex partitions are served over Arrow Flight between executors, with on-the-fly conversion from Vortex arrays to Arrow RecordBatches at the serving boundary.
Contributing to Vortex
The Spice AI team is actively contributing to the Vortex project. A few examples:
N-ary CASE WHEN expression pushdown. We implemented SQL-style CASE WHEN expressions as a native Vortex scalar function (vortex-data/vortex#6786). This enables CASE WHEN expressions to evaluate directly on encoded data, condition checks and branch selection happen without decompression. The DataFusion integration converts CaseExpr nodes into Vortex's native representation and pushes them down through the scan layer.
Production hardening. Shipping Vortex in production surfaced edge cases that we have fixed and are working to upstream.
Resilient filter pushdown: Unsupported filter nodes (such as empty IN-lists) aborted entire scans. We changed the behavior to bubble up TRUE for unsupported nodes within AND/OR trees, so partial pushdown still works.
Balanced IN-list OR trees: Large IN (...) filters produced deeply nested OR trees that stack-overflowed. We restructured list_contains to build balanced binary trees.
Optional direct VortexSink file writing: DataFusion's demuxer registered child metrics under parents, causing OOM on high-partition tables. For these tables, we write files directly in VortexSink, which also fixed target file size enforcement under parallel writes.
Production Lessons
After building Cayenne with Vortex, here are some learnings that are hopefully helpful in your own project:
Lesson 1: SQLite is a very capable embedded metadata store
SQLite handles concurrent reads effectively, transactions are rock-solid, and the operational model (just a file) is trivially simple.
Lesson 2: Cache sizing matters
Footer and segment caches have dramatic impact on read performance. Our defaults (128MB footer, 256MB segment) work well for typical workloads, but expose tuning parameters for users with specific needs.
Lesson 3: Push deletions down as far as possible
Reject deleted rows at the lowest layer you can. Position-based deletion via ExcludeRoaring skips rows during decompression. PK-based deletion uses a bloom filter for O(1) rejection before the hash table. Each layer you avoid, decompression, materialization, filtering, saves CPU and memory.
Lesson 4: Zero-copy is worth the constraints
Accepting Vortex's type constraints (no Interval, no Duration, etc.) is worth it for true zero-copy Arrow access. The performance difference is substantial.
Lesson 5: Expression pushdown compounds
Pushing expressions like CASE WHEN into Vortex so they evaluate on encoded data compounds with other pushdowns (predicate, projection). Each layer you skip reduces the work for every subsequent layer.
Lesson 6: Keep shuffle data in encoding-efficient format
In distributed queries, shuffle data is typically serialized as Arrow IPC between stages. Replacing this with Vortex IPC keeps data compressed during transfer without paying decompression cost at the sender or re-compression cost at the receiver.
Lesson 7: Rewrite filters to maximize pushdown
Getting the best performance from Vortex with DataFusion depends on pushing as many filter expressions as possible into Vortex so they run on Vortex compute kernels. Not every DataFusion predicate maps cleanly to a native Vortex filter, so it is worth identifying the ones that do not push down and rewriting them into equivalent forms that do.
Getting Started with Vortex and Cayenne
Cayenne's separation of data and metadata is an implementation detail handled internally. From a configuration perspective, enabling it is as simple as:
datasets:
- from: spice.ai:path.to.my_dataset
name: my_dataset
acceleration:
engine: cayenne
mode: fileFor storage, NVMe gives the lowest latency and best throughput for Vortex's random access patterns and is the recommended choice for most deployments. If you need data to persist across restarts or be shared across Spice instances, Cayenne also supports S3 Express One Zone, which provides single-digit millisecond latency with full durability while keeping metadata local.
Conclusion
Choosing a storage format is ultimately a bet on a set of tradeoffs. We believe Vortex makes the right ones for where data infrastructure is heading: compressing efficiently enough to be practical at scale, reading fast enough for real-time workloads, and built on an architecture extensible enough to support the heterogeneous access patterns that AI applications are introducing.
Built on that foundation, Cayenne gives Spice a local acceleration layer that scales with data volume and write concurrency without the operational complexity of a distributed system or the scaling limits of a single-file engine. With Vortex-based shuffles in Ballista, that same format efficiency extends across the distributed query pipeline.
We encourage you to explore the Vortex project if you want to go deeper on the format itself, the Spice Cayenne documentation for configuration and deployment details, and the Cayenne launch blog for the full benchmark breakdown.
Questions or feedback? Find us in the Vortex and Spice Slack communities.
Vortex at Spice AI FAQ
What is Vortex and why did Spice AI choose it for Cayenne?
Vortex is an open-source columnar format optimized for running compute directly on encoded data. Spice AI chose Vortex for Cayenne because it provides a strong balance of compression, low-latency reads, and operational simplicity for high-concurrency, data-intensive workloads.
How is Vortex different from Parquet in this architecture?
Parquet is widely adopted and efficient for many analytical workloads, but frequent decompression can become expensive on hot query paths. In the Cayenne architecture, Vortex enables more work to happen on encoded data and uses richer segment-level statistics for pruning, reducing CPU and memory overhead under repeated access patterns.
What role does SQLite play in Spice Cayenne?
SQLite acts as the transactional metadata store for snapshots, file manifests, and deletion vector metadata, while Vortex files hold table data. This split keeps metadata operations simple and atomic while allowing data files to scale independently.
How does Cayenne handle deletes and upserts with immutable files?
Cayenne uses deletion vectors and sequence numbers. Deletes are tracked in metadata and applied according to sequence ordering, which allows new row versions to be written without rewriting full data files. Periodic compaction then merges data and delete state into fresh snapshots.
How can I start using Cayenne with Vortex in Spice?
Enable file-mode acceleration with engine: cayenne in your dataset configuration, then run Spice with your configured source. For setup details and tuning guidance, see the Cayenne documentation and the launch blog.