Real-Time Hybrid Search Using RRF: A Hands-On Guide with Spice
Search
Spice AI

Wyatt Wenzel
DevRel & Ops Leader at Spice AIOctober 23, 2025
TL;DR: Reciprocal Rank Fusion (RRF) combines keyword, vector, and metadata search results into a single ranked list without score normalization. This guide walks through building real-time hybrid search with RRF directly in SQL using Spice -- from setup and embedding generation to multi-signal queries with time decay.
Surfacing relevant answers to searches across datasets has historically meant navigating significant tradeoffs. Keyword (or lexical) search is fast, cheap, and commoditized, but limited by the constraints of exact matching. Vector (or semantic) search captures nuance and intent, but can be slower, harder to debug, and expensive to run at scale. Combining both usually entails standing up multiple engines (e.g. Elasticsearch for text, Pinecone for vectors), writing custom ranker logic, and maintaining ETL and data sync pipelines.
As real-time, AI-powered applications and agents become ubiquitous, these compromises are less tenable. Users demand instant, context-rich results that balance precision with intent. This applies to both consumer and enterprise application search environments; for example, a business user searching across internal knowledge bases, or a customer searching for an item in their chat history on a consumer app. Waiting for data pipelines to sync, dealing with custom APIs, or troubleshooting a multi-system ranking stack introduces a variety of sub-optimal outcomes: inconsistent rankings, higher latency, or just simply inaccurate results.
Hybrid Search with Reciprocal Rank Fusion (RRF)
Reciprocal Rank Fusion (RRF) is an algorithm for hybrid search that helps mitigate the search challenge unfolded above. Instead of favoring one search modality, RRF merges results from multiple independent searches and variables (text, vector, metadata, recency, etc.) by combining their ranks and giving each signal proportional influence. This avoids "winner take all" blending and delivers results that are both topically relevant and contextually meaningful.
In practice, each search query is executed independently, and the ranks of the returned results are combined using the following formula:
RRF Score = Σ(rank_weight / (k + rank))
Documents that appear across multiple result sets receive higher scores, while the smoothing parameter k controls how much rank position affects the final score (lower values make higher-ranked items more influential).
RRF can also incorporate custom weighting and temporal decay, enabling developers to:
- Adjust the influence of each query type using the
rank_weightparameter. - Apply recency boosting by specifying a
time_columnanddecayfunction.- Exponential decay: : e^(-decay_constant * age_in_units) where age is in decay_scale_secs
- Linear decay: max(0, 1 - (age_in_units / decay_window_secs))
This approach lets you incorporate exact keyword matches, semantic similarity, and time-based relevance in one consistent ranking.
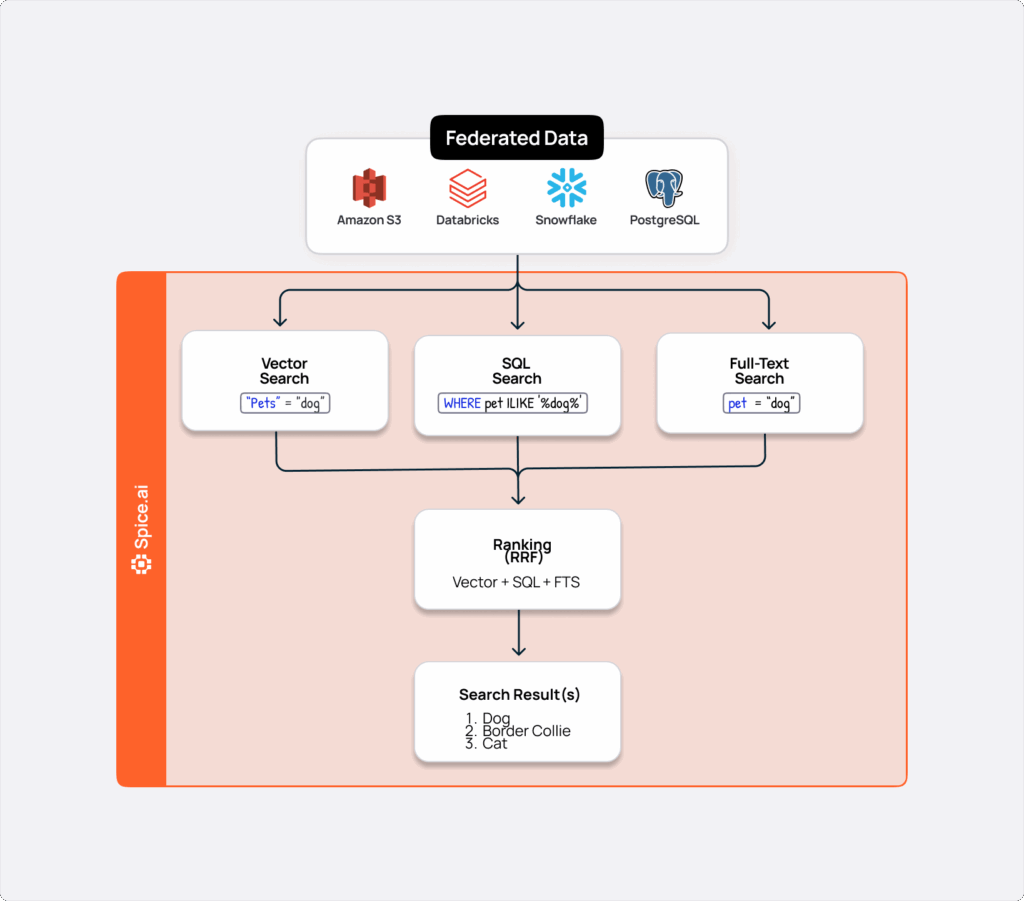
- SQL operators combine text and vector search in a single query
- Rank weights can be tuned per-query
- Recency and metadata can be included with no extra code
- No external ranking server, no additional infrastructure, and no manual pipeline management are required
Let's take this out of the abstract and review a sequence of queries that illustrate the business value of RFF in Spice, from basic to more sophisticated ranking techniques.
Hybrid Search
-- Combine vector and text search for enhanced relevance
SELECT id, title, content, fused_score
FROM rrf(
vector_search(documents, 'machine learning algorithms'),
text_search(documents, 'neural networks deep learning', content),
join_key => 'id' -- explicit join key for performance
)
WHERE fused_score > 0.01
ORDER BY fused_score DESC
LIMIT 5;This first example illustrates the basic building blocks of RRF-powered hybrid search: merging semantic/vector and traditional keyword/text retrieval in one query. The result set balances conceptual relevance - capturing results related to "machine learning algorithms" - with precise keyword matches like "neural networks" or "deep learning.". Using the join_key ensures that performance scales commensurately with data volume.
Weighted Ranking
-- Boost semantic search over exact text matching
SELECT fused_score, title, content
FROM rrf(
text_search(posts, 'artificial intelligence', rank_weight => 50.0),
vector_search(posts, 'AI machine learning', rank_weight => 200.0)
)
ORDER BY fused_score DESC
LIMIT 10;Weighting lets you fine-tune intent. Semantic results for "AI machine learning" are given four times more influence than exact text matches for "artificial intelligence." This allows development teams to favor context and meaning, surfacing more relevant content even when users don't type a precise phrase.
Recency-Boosted
-- Exponential decay favoring recent content
SELECT fused_score, title, created_at
FROM rrf(
text_search(news, 'breaking news'),
vector_search(news, 'latest updates'),
time_column => 'created_at',
recency_decay => 'exponential',
decay_constant => 0.05,
decay_scale_secs => 3600 -- 1 hour scale
)
ORDER BY fused_score DESC
LIMIT 10;Finally, RRF can incorporate time as a ranking signal (important for use cases like trading exchanges, news, or social media).
By specifying a time_column and a decay function, you can automatically boost time-pertinent results. In this example, exponential decay prioritizes newer stories while keeping hybrid relevance intact.
Use Case Walk-Through
Now, let's walk through a hands-on example: capturing real-time Bluesky posts, embedding and full-text indexing them automatically, and running hybrid search queries with RRF via SQL.
Step 1. Set up
Clone this repository:
git clone https://github.com/spiceai/cookbook.git
cd cookbook/searchInstall websocat and set up Python:
brew install websocat
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtStep 2. Preview and capture data
We can read real-time posts using Bluesky's Jetstream relay service. Use websocat to preview the stream and ensure that the relay is functional:
websocat wss://jetstream2.us-east.bsky.network/subscribe\?wantedCollections=app.bsky.feed.post | jq
{
"did": "did:plc:ei3py27iy2orpykshoudxnls",
"time_us": 1758813540806266,
"kind": "commit",
"commit": {
"rev": "3lzoas6yujs2z",
"operation": "create",
"collection": "app.bsky.feed.post",
"rkey": "3lzoas6nbhs2e",
"record": {
"$type": "app.bsky.feed.post",
"createdAt": "2025-09-25T15:19:00.163Z",
"langs": [
"ja"
],
"text": "🧐🧐🧐🧐🧐"
},
"cid": "bafyreighkijp5zyclu6qdjtfskmr65ttvxvedvqmfvwgfyf6iaq4jfdje4"
}
}
...
^CLet's convert this stream into a Parquet file that Spice AI can read. Let this run for a little while, until satisfied with the total number collected. Run again at any time to resume appending:
websocat wss://jetstream2.us-east.bsky.network/subscribe\?wantedCollections=app.bsky.feed.post | ./generate_parquet.py
[info] boot!
[info] INSERTED 250 ROWS; TOTAL 250
[info] INSERTED 250 ROWS; TOTAL 500Step 3. Start Spice and Search
In a new terminal, start Spice. It will embed, full-text index, and ingest the latest data. Additionally, the file connector is using fsnotify to watch it for updates, to eagerly ingest data.
spice runYou should see this output:
2025-09-26T15:21:38.154354Z INFO spiced: Starting runtime v1.8.0-unstable-build.71ac09ff2+models.metal
2025-09-26T15:21:38.225135Z INFO runtime::init::caching: Initialized results cache; max size: 128.00 MiB, item ttl: 1s
2025-09-26T15:21:38.229824Z INFO runtime::init::caching: Initialized search results cache; max size: 128.00 MiB, item ttl: 1s
2025-09-26T15:21:38.230575Z INFO runtime::init::caching: Initialized embeddings cache; max size: 128.00 MiB, item ttl: 1s
2025-09-26T15:21:38.658824Z INFO runtime::opentelemetry: Spice Runtime OpenTelemetry listening on 127.0.0.1:50052
2025-09-26T15:21:38.658888Z INFO runtime::flight: Spice Runtime Flight listening on 127.0.0.1:50051
2025-09-26T15:21:38.678694Z INFO runtime::http: Spice Runtime HTTP listening on 127.0.0.1:8090
2025-09-26T15:21:47.550688Z INFO runtime::init::embedding: Embedding Model potion_128m ready
2025-09-26T15:21:47.659106Z INFO runtime::init::dataset: Dataset bluesky_posts initializing...
2025-09-26T15:21:47.730735Z INFO runtime::dataconnector::file: Watching changes to bluesky_posts.parquet
2025-09-26T15:21:47.730999Z INFO runtime::init::dataset: Dataset bluesky_posts registered (file://bluesky_posts.parquet), acceleration (duckdb:file, append), results cache enabled.
2025-09-26T15:21:47.740354Z INFO runtime::accelerated_table::refresh_task: Loading data for dataset bluesky_posts
2025-09-26T15:21:57.885819Z INFO runtime::accelerated_table::refresh_task: Dataset bluesky_posts received 38,101 records
2025-09-26T15:21:58.507599Z INFO runtime::accelerated_table::refresh_task: Loaded 38,101 rows (54.72 MiB) for dataset bluesky_posts in 10s 775ms.
2025-09-26T15:21:58.550191Z INFO runtime: All components are loaded. Spice runtime is ready!
2025-09-26T15:22:20.335633Z INFO runtime::accelerated_table::refresh_task: Loading data for dataset bluesky_posts
2025-09-26T15:22:21.960722Z INFO runtime::accelerated_table::refresh_task: Loaded 251 rows (339.49 kiB) for dataset bluesky_posts in 1s 656ms.In a new terminal, start the Spice SQL REPL:
spice sqlBasic Hybrid Search
Combine exact text matching with semantic similarity for comprehensive results:
-- Find posts about space travel using both exact text and semantic search
select fused_score, text, created_at, langs
from rrf(
text_search(bluesky_posts, 'space travel'),
vector_search(bluesky_posts, 'space travel')
) order by fused_score desc limit 10;Weighted Ranking
Boost specific search strategies using rank_weight to prioritize different result types:
-- Heavily prioritize semantic similarity over exact text matches
select fused_score, text, rkey
from rrf(
text_search(bluesky_posts, 'artificial intelligence', rank_weight => 50.0),
vector_search(bluesky_posts, 'AI machine learning', rank_weight => 200.0)
) order by fused_score desc limit 15;
-- Prioritize exact mentions while including semantic results
select fused_score, text, created_at
from rrf(
text_search(bluesky_posts, 'climate change', rank_weight => 300.0),
vector_search(bluesky_posts, 'environmental sustainability', rank_weight => 100.0)
) order by fused_score desc limit 20;Recency-Boosted Search
Use temporal information to surface recent content with exponential or linear decay:
-- Recent posts get higher scores with exponential decay
select fused_score, text, created_at, rkey
from rrf(
text_search(bluesky_posts, 'breaking news'),
vector_search(bluesky_posts, 'latest updates'),
time_column => 'created_at',
recency_decay => 'exponential',
decay_constant => 0.05,
decay_scale_secs => 3600 -- 1 hour scale
) order by fused_score desc limit 10;
-- Linear decay for trending topics over the last day
select fused_score, text, created_at
from rrf(
text_search(bluesky_posts, 'trending now'),
vector_search(bluesky_posts, 'viral popular'),
time_column => 'created_at',
recency_decay => 'linear',
decay_window_secs => 86400 -- 24 hours
) order by fused_score desc limit 15;Advanced Parameter Tuning
Fine-tune the RRF algorithm using the smoothing parameter k:
-- Lower k value for more aggressive ranking differences
select fused_score, text, langs
from rrf(
text_search(bluesky_posts, 'technology innovation'),
vector_search(bluesky_posts, 'tech startups'),
k => 20.0 -- More aggressive than default 60.0
) order by fused_score desc limit 12;
-- Higher k for smoother score distribution
select fused_score, text, created_at
from rrf(
text_search(bluesky_posts, 'social media'),
vector_search(bluesky_posts, 'online platforms'),
k => 120.0 -- Smoother than default 60.0
) order by fused_score desc limit 10;Multi-Language and Content Analysis
Combine vector search queries across languages for similar concepts:
-- Find posts about "breaking news" with semantic query in Spanish, but keyword match in English
select fused_score, text, langs, created_at
from rrf(
vector_search(bluesky_posts, 'ultimas noticias', rank_weight => 100),
text_search(bluesky_posts, 'news'),
time_column => 'created_at',
recency_decay => 'exponential',
decay_constant => 0.05,
decay_scale_secs => 3600 -- 1 h
) where trim(text) != '' order by fused_score desc limit 15;
-- Find posts about breaking news using two semantic queries in Spanish, but filter results for English
select fused_score, text, langs, created_at
from rrf(
vector_search(bluesky_posts, 'ultimas noticias'),
vector_search(bluesky_posts, 'noticias de ultima hora'),
time_column => 'created_at',
recency_decay => 'exponential',
decay_constant => 0.05,
decay_scale_secs => 3600 -- 1 h
) where langs like '%en%' and trim(text) != '' order by fused_score desc limit 15;Step 4. Enable agentic support
Stop Spice, and go to spicepod.yml and uncomment the models block. Update the .env file with your OpenAI key. Then start Spice again.
spice runAfterwards, begin a chat session:
spice chatTry to query for insights using natural language:
chat> Can you see how many posts there are in the last day about photography?
There were 676 posts about photography in the last day on the Bluesky platform. If you have any further questions or need additional insights, feel free to ask!
Time: 10.12s (first token 9.50s). Tokens: 1635. Prompt: 1588. Completion: 47 (75.62/s).
chat> Can you show me a breakdown by language?
Here's a breakdown of the posts about photography in the last day by language:
1. **English (en):** 596 posts
2. **German (de):** 41 posts
3. **Finnish (fi):** 20 posts
4. **Unspecified:** 17 posts
5. **English, Hebrew, Sanskrit (en, he, sa):** 1 post
6. **Dutch (nl):** 1 postAnd that's it. We've just walked through a full
Next steps
Hybrid Search with RRF in Spice eliminates external ranking servers, sync pipelines, or duplicated datasets; you can query, rank, and reason across disparate data sources from a single SQL interface. Whether you're powering an internal knowledge assistant or surfacing live content from social feeds, you get near-real-time, context-rich results with minimal overhead.
Get started:
- Sign up for Spice Cloud for free, or get started with Spice OSS
- Explore the Hybrid Search Docs
- Go through the RFF cookbook example
- Schedule a demo if you'd like full a walk-through
Frequently Asked Questions
What is Reciprocal Rank Fusion (RRF) and how does it work?
Reciprocal Rank Fusion is a ranking algorithm that merges results from multiple search methods -- such as keyword search and vector search -- into a single, unified ranking. RRF scores each result based on its position in each individual ranking using the formula 1 / (k + rank), then sums scores across all rankings. This approach is lightweight, requires no model training, and consistently produces high-quality hybrid results.
When should I use hybrid search instead of vector search alone?
Hybrid search outperforms vector-only search when queries contain specific identifiers, product names, error codes, or exact terms that semantic embeddings may miss. It also helps when your dataset includes both structured metadata and unstructured text. Combining keyword precision with semantic understanding via RRF produces more consistent results across diverse query types.
How does Spice implement hybrid search in a single query?
Spice provides built-in vector_search and text_search SQL functions that can be combined with standard SQL joins and a rrf() ranking function. This means keyword search, vector similarity, and RRF fusion all execute within the same query engine -- no external services, no multi-system orchestration. Results are ranked and returned in a single round-trip.
What is the advantage of RRF over other fusion methods like weighted scoring?
RRF is rank-based rather than score-based, which makes it robust across search methods that use different scoring scales. Weighted scoring requires tuning weights for each method and can be sensitive to score distribution changes. RRF delivers strong results out of the box without hyperparameter tuning, making it a practical default for most application search use cases.
Explore more Spice resources
Tutorials, docs, and blog posts to help you go deeper with Spice.
A Developer’s Guide to Understanding Spice.ai
This guide helps developers build a mental model of why, how, and where to use Spice.

Operationalizing Amazon S3 for AI: From Data Lake to AI-Ready Platform in Minutes
Amazon S3 has evolved with S3 Tables and S3 Vectors, but leveraging them for real-time AI workloads requires significant distributed systems work. This post shows how Spice handles ingestion, federation, acceleration, and hybrid search - transforming S3 into a low-latency, AI-ready platform with minimal configuration.

How we use Apache DataFusion at Spice AI
Why we chose to build on DataFusion and how we extended it with custom TableProviders, optimizer rules, and UDFs for federated SQL

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer