Multi-Tenancy for AI Agents without the Pipelines
Spice AI
Data Federation
Engineering

Wyatt Wenzel
DevRel & Ops Leader at Spice AIApril 15, 2026
TL;DR: Multi-tenant AI agents need access to customer data across disparate enterprise data sources, and building an ETL pipeline for every tenant doesn't scale. Spice.ai is a data and AI platform built on first principles for this category of use case, offering the optionality to deploy one sandboxed runtime per agent or tenant, all the way up to distributed multi-node query execution for larger workloads. This post walks through four patterns for deploying Spice as the data substrate for multi-tenant agents - each with different isolation guarantees, from logical filtering to fully sandboxed runtimes suited for regulated enterprise environments:
- Query-time tenant isolation
- Config-level tenant isolation
- Runtime-level tenant isolation
- Hybrid isolation
For more significant and variable SaaS workloads, we generally recommend the hybrid configuration, where large accounts get dedicated Spice instances, and the long tail shares a partitioned deployment.
The AI Agent Challenge in Multi-Tenant SaaS
Multi-tenant SaaS infrastructure has always been operationally complex. The pipeline-per-integration model works at small scale, but hits a wall when you have hundreds or thousands of customers, each with their own data lakes, databases, and warehouses. ETL pipelines encode assumptions about schema, refresh schedules, and ownership that collapse when customer environments change. This naturally leads to significant overhead dedicated to managing ETL orchestration.
AI agents that need to query across all of these sources with strict tenant isolation add another layer entirely.
Spice is designed for exactly this problem - a data platform for AI context that queries disparate enterprise data sources with tenant isolation and without ETL pipelines.
What Spice Enables
Spice is a portable data, search, and AI-inference engine built in Rust on Apache DataFusion. It connects to 30+ data sources -- S3, Snowflake, Databricks, PostgreSQL, Kafka, and more -- and accelerates queries locally for sub-second response times, serving SQL query, search, AI inference, and catalog APIs over HTTP, Arrow Flight, FlightSQL, ODBC, JDBC, and ADBC.
What makes Spice well-suited for multi-tenant agent deployments is its footprint and optionality. Unlike centralized clusters that require every tenant to share compute, memory, and query infrastructure, the Spice runtime is lightweight enough to deploy one instance per agent or per tenant, giving each agent its own sandboxed data and AI stack with its own sources, acceleration layers, and secrets. For workloads that demand it, Spice also supports distributed, multi-node query execution at scale. Isolation is a deployment property rather than something you enforce in application code - and the foundation for the kind of enterprise data policy controls that regulated industries increasingly require.
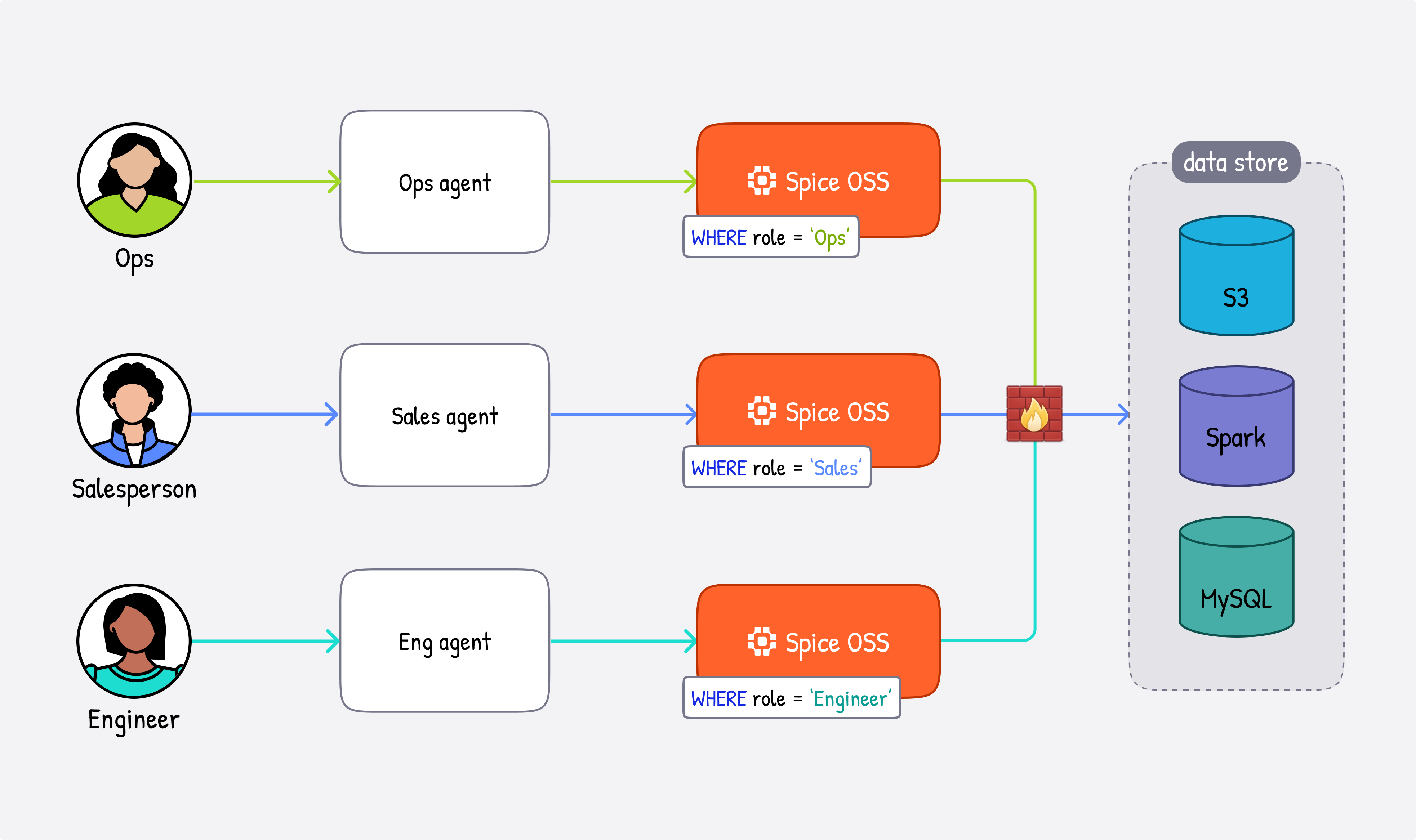
The unit of configuration is a spicepod.yaml, a declarative manifest for datasets, models, and secrets.
We call this out because tenant topology, source definitions, and acceleration behavior are all configured at this layer, making it the right abstraction for understanding the deployment patterns below.
Pattern 1: Query-Time Tenant Isolation
This is the simplest operating model; one runtime serves many tenants. Datasets include tenant-partitioned tables, and the application always includes tenant filters in queries.
version: v1
kind: Spicepod
name: saas-shared
datasets:
- from: postgres:public.events
name: events
params:
pg_host: db.shared.internal
pg_port: '5432'
pg_db: app
pg_user: ${secrets:PG_USER}
pg_pass: ${secrets:PG_PASS}
acceleration:
enabled: true
engine: arrow
refresh_check_interval: 1sWhat this Spicepod is doing:
version,kind, andnamedefine a standard Spicepod manifest and runtime identity.datasetsdeclares which source objects are queryable through Spice.from: postgres:public.eventsmaps to one shared table that contains many tenants.paramskeeps connection settings explicit, while secrets stay externalized.acceleration.refresh_check_interval: 1skeeps local acceleration refreshes frequent.
Tradeoff summary:
- Pros: easiest to operate and cheapest to start.
- Cons: tenant isolation is logical. Correctness depends on consistent tenant filtering in every query path.
Variant: View-Based Tenant Isolation
A lightweight extension of Pattern 1 moves tenant filtering from application code into the Spicepod itself using views. Each tenant gets a named view that wraps the shared dataset with a pre-applied filter. Agents query the view directly rather than constructing filters at runtime.
datasets:
- name: events
from: postgres:public.events
params:
...
views:
- name: view_tenant_abc
sql: "select * from events where tenant='tenant_abc'"
- name: view_tenant_xyz
sql: "select * from events where tenant='tenant_xyz'"This makes tenant boundaries explicit in configuration without the overhead of separate dataset entries or multiple runtimes. The tradeoff is the same as Pattern 1 (isolation is still logical), but the filter is enforced at the Spice layer rather than relying on every query path in the application to get it right.
Pattern 2: Config-Level Tenant Isolation
This pattern keeps one runtime but makes tenant boundaries explicit in configuration by declaring separate dataset entries per tenant. In practice, these entries are generated from onboarding metadata.
version: v1
kind: Spicepod
name: saas-many-datasets
datasets:
- from: postgres:tenant_abc.events
name: tenant_abc_events
params:
pg_host: db.pool.internal
pg_port: '5432'
pg_db: app
pg_user: ${secrets:PG_USER}
pg_pass: ${secrets:PG_PASS}
- from: postgres:tenant_xyz.events
name: tenant_xyz_events
params:
pg_host: db.pool.internal
pg_port: '5432'
pg_db: app
pg_user: ${secrets:PG_USER}
pg_pass: ${secrets:PG_PASS}
# In production this list can be generated from tenant onboarding metadata.What this Spicepod is doing:
- Each dataset name maps to a tenant-specific schema/table boundary.
- Isolation intent is encoded directly in configuration, not only at query time.
- The runtime still remains shared, so scheduling and memory are shared concerns.
Tradeoff summary:
- Pros: tenant boundaries are explicit in config and easier to audit.
- Cons: the manifest can become very large, and operational limits (reload time, config management, memory planning) become the bottleneck at very high tenant counts.
Pattern 3: Runtime-Level Tenant Isolation
For strict isolation, run a separate Spicepod per tenant (or per enterprise tenant tier) and route requests using tenant context from auth/session claims.
spicepod-tenant-abc.yaml:
version: v1
kind: Spicepod
name: tenant-abc
datasets:
- from: postgres:public.events
name: events
params:
pg_host: tenant-abc-db.internal
pg_port: '5432'
pg_db: app
pg_user: ${secrets:PG_USER}
pg_pass: ${secrets:PG_PASS}
acceleration:
enabled: true
engine: duckdb
mode: file
refresh_check_interval: 1s
params:
duckdb_file: /var/lib/spice/tenant-abc.dbRouter policy (conceptual):
tenants:
- id: enterprise-abc
spicepod: spicepod-tenant-abc
- id: enterprise-xyz
spicepod: spicepod-tenant-xyz
default:
spicepod: spicepod-sharedWhat this deployment is doing:
- Each tenant runtime has an independent manifest, compute envelope, and cache.
- Tenant routing is structural. Requests do not cross tenant runtime boundaries.
- You can apply stronger SLOs and controls to selected tenants.
Tradeoff summary:
- Pros: clearest isolation model and per-tenant operational control.
- Cons: higher operational overhead as tenant count grows.
Pattern 4: Hybrid Isolation
Most SaaS businesses follow a power-law distribution. A small cohort of high-value accounts justifies dedicated infrastructure, while the long tail is better served by shared infrastructure.
Large tenants run on dedicated Spicepods. Smaller tenants run in a shared, partitioned deployment. The router decides placement, and clients query one logical interface.
# router config (conceptual)
tenants:
- id: enterprise-abc
spicepod: spicepod-tenant-abc
- id: enterprise-xyz
spicepod: spicepod-tenant-xyz
default:
spicepod: spicepod-sharedWhat this deployment is doing:
- Keeps the query interface stable while allowing tenant placement by policy.
- Isolates high-load or regulated tenants on dedicated runtimes.
- Uses shared capacity for the long tail to control cost and ops overhead.
Tradeoff summary:
- Pros: best long-term balance of isolation, cost, and operational scalability.
- Cons: requires a routing layer and clear promotion criteria for moving tenants between tiers.
Getting Started
The right deployment shape depends on your workload: the scale of your tenant base, your isolation requirements, and how frequently each tenant's data is queried. Spice connects to 30+ sources through declarative configuration, so adding a new data source is a YAML entry rather than a pipeline build.
Explore the Spice docs to go deeper on the patterns covered here, or join the Spice Slack community to discuss your architecture with the team.
Zero-ETL Multi-Tenant AI Agents FAQ
What does zero-ETL mean in a multi-tenant AI application?
Zero-ETL means querying tenant data in place through federation and only accelerating the datasets that need low-latency repeated reads. Instead of pipeline code per tenant, teams configure source access and refresh behavior in Spicepods.
How should teams choose between shared and dedicated Spicepods?
Use shared runtimes for long-tail tenants with moderate traffic. Use dedicated Spicepods for high-load, high-sensitivity, or regulated tenants. Most production systems use a hybrid placement model and promote tenants based on observed thresholds.
When is CDC acceleration better than pure federation?
Use CDC acceleration for hot operational datasets that are queried frequently and require predictable low latency. Use federation for colder datasets where source-of-truth freshness matters more than sub-second response times.
Can one app query all tenant backends through one SQL interface?
Yes. Spice federates across disparate enterprise data sources and exposes a unified SQL interface. Your app or agent can keep one query layer while the runtime routes each table scan to accelerated or federated paths as configured.