Apache Ballista at Spice AI: Distributed Query Execution Without the Operational Tax
Spice AI
Spice Open-Source
Engineering

Luke Kim
Founder and CEO of Spice AIApril 9, 2026
TL;DR: Spice.ai has evolved from a single-node query engine into a distributed data platform built for enterprise workloads. By integrating Apache Ballista for distributed query execution and the Vortex columnar format for high-performance data transport, we've built a system that scales horizontally across compute clusters while maintaining the simplicity of a single-node deployment. The most significant extension we made to stock Ballista was replacing its single-scheduler architecture with multi-active HA coordinated through object store state, so high availability has no external infrastructure dependency beyond the object store itself.
This post is the fourth installment in our series on the open-source technologies powering Spice.ai, following Apache DataFusion, Apache Iceberg, and Vortex at Spice AI. We'll focus on the distributed query layer: what Ballista gives us, what we built on top, and what we learned going to production.
The Problem: Single-Node Ceilings
Spice.ai is a portable data, search, and AI-inference engine built in Rust on Apache DataFusion. It connects to 30+ data sources (S3, Snowflake, Databricks, PostgreSQL, Kafka, and more) and accelerates queries locally for sub-second response times, serving SQL query, search, AI inference, and catalog APIs over HTTP, Arrow Flight, FlightSQL, ODBC, JDBC, and ADBC.
Queries against 100GB+ data lakes were exceeding the memory and compute capacity of a single process, and we didn't have a good fault tolerance solution for long-running analytical workloads. It became clear we needed to enable enterprises to scale query compute independently of storage without taking on the operational complexity of a system like Spark, and without sacrificing the developer experience that makes Spice.ai straightforward to deploy.
Distributed query execution on top of object storage was the answer.
An important design constraint: distributed mode targets throughput and scale for batch/analytical workloads (seconds to minutes). Sub-second real-time queries continue to use single-node Spice with acceleration. This distinction shaped every architecture decision that followed.
Why Apache Ballista
When we evaluated distributed query frameworks in late 2025, three candidates emerged:
| Criteria | Apache Ballista | datafusion-distributed | Custom Build |
|---|---|---|---|
| Production maturity | 4+ years, ASF governance, 440+ dependents | ~10 months, 20 contributors | N/A |
| Fault tolerance | Disk-based shuffle; failed stages retried from intermediate data | Fully in-memory; failures restart from scratch | 6-12+ months to build |
| Ecosystem | Core contributors from Apple; Coralogix (65+ releases of production fork) | Primarily Datadog internal tooling | N/A |
| DataFusion integration | Native; same query planning, same Arrow types | Native but minimal scaffolding | Requires Substrait bridge |
We chose Ballista because it is batteries-included. It ships with a mature scheduler-executor model, a shuffle service with disk-based fault tolerance, Arrow Flight RPC, and metrics collection. Building equivalent capabilities from scratch would have taken 6-12+ months, time better spent on Spice's differentiating features: acceleration, search, and AI inference.
Published TPC-H SF100 benchmarks show 2.9x overall speedup vs. single-node DataFusion, with 5-10x lower memory usage than Apache Spark.
Early Distributed Results: Spice vs. Spark
Even in early preview (Oct 2025), our distributed cluster showed striking results against Apache Spark on Databricks:
| Query | Spice Cluster (48 cores, 24GB RAM) | Spark on Databricks (48 cores, 192GB RAM) | Speedup |
|---|---|---|---|
| Wildcard filter (no hits) | 6.1s | 47s | 7.7x faster |
| Wildcard filter (with hits) | 6.6s | 25s | 3.8x faster |
| Distributed embed (~100k rows) | 9.8s | 17s | 1.7x faster |
The Spice cluster used 8x less RAM than Spark while delivering 2-8x better query performance, a direct consequence of building on Rust and Arrow, where zero-copy data transport via Arrow Flight eliminates the JVM overhead and garbage collection pauses that constrain Java-based systems.
The Architecture
A distributed Spice cluster has two roles:
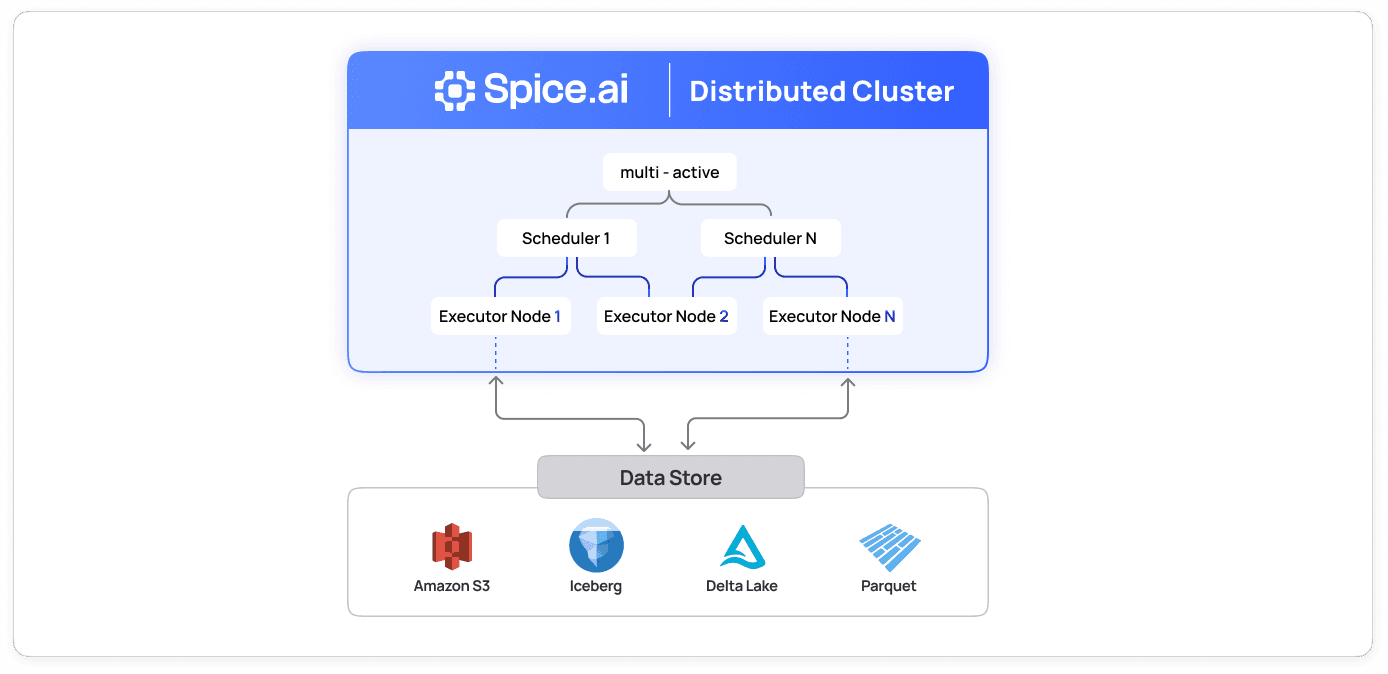
-
Schedulers accept SQL queries, plan distributed execution, and coordinate task dispatch across the executor fleet. Multiple schedulers run multi-active for high availability, coordinating through object store state instead of requiring etcd, ZooKeeper, or other external coordination services.
-
Executors run physical query plans and exchange intermediate data via shuffle. They establish bidirectional control streams to all schedulers, enabling transparent failover, on-demand metrics, task cancellation, and partition management.
Standalone mode remains fully functional. A single spiced binary with no cluster configuration behaves exactly as before, with zero operational overhead for single-node deployments.
Distributed Query Flow
- Client submits SQL to any scheduler via HTTP, Arrow Flight, or FlightSQL
- Scheduler creates a logical plan using DataFusion, then a distributed physical plan via Ballista
- Plan stages are dispatched as tasks to executors via push-based scheduling for minimal latency
- Executors run tasks, writing intermediate shuffle data to disk, memory, or object store
- Results stream back to the client through the scheduler as Arrow record batches
Failed tasks are automatically retried from intermediate shuffle data, avoiding full re-execution.
A key architectural consequence: synchronous queries cannot survive scheduler death mid-execution. For long-running distributed workloads, Spice provides an async query submission API where clients submit jobs and poll for results. This ensures jobs are resilient to scheduler failure after acceptance.
Multi-Active Schedulers with Object Store State
Stock Ballista has a single-scheduler architecture, making it a single point of failure. We built multi-active HA using object store (S3, Azure Blob, or local filesystem) as the shared state layer, with no external coordination services.
Each scheduler registers itself by writing a JSON record to a well-known path in the object store (e.g. s3://bucket/schedulers/{scheduler_id}.json). The ObjectState layer provides optimistic concurrency control via ETag-based conditional writes (PutMode::Create for initial registration, conditional updates for heartbeats) with Fibonacci backoff on conflicts (MAX_CONDITIONAL_ATTEMPTS = 5).
The protocol works as follows:
- Registration: On startup, a scheduler inserts its record. If the key already exists and the existing record is stale (heartbeat expired past TTL + clock skew tolerance), it overwrites via conditional update. If the record is still active, startup fails to prevent duplicate IDs.
- Heartbeat: Every
TTL / 3(default: 10 seconds), each scheduler conditionally updates its record with a freshlast_heartbeat_ms. The conditional write ensures that if two schedulers race, only one succeeds per ETag version. - Discovery: Every 5 seconds, each scheduler lists all scheduler records, filters out stale entries, and updates its in-memory peer map. New and removed peers are logged.
- Shutdown: On graceful shutdown, the scheduler deletes its record.
This design means the only infrastructure requirement for HA is an object store that supports conditional writes (S3, Azure Blob Storage, or even a shared local filesystem). The only external dependency is the object store itself; there is no etcd, ZooKeeper, or Redis cluster to operate. The tradeoff is that shared state is eventually consistent and the object store is in the hot path for coordination, which is acceptable for batch/analytical workloads where scheduling overhead is small relative to query runtime.
Clients can submit queries to any scheduler. Each scheduler independently plans and coordinates query execution across the shared executor fleet.
What We Built on Top of Ballista
Stock Ballista provides the distributed execution foundation. But integrating it with Spice's feature set (acceleration, search, UDFs, telemetry, multi-tenancy) required significant extension work maintained in our fork.
1. Bidirectional Control Streams
Executors establish long-lived bidirectional gRPC streams (ControlStream) to every known scheduler. These streams carry:
- Heartbeats: Executors send periodic heartbeats with task slot availability.
- PollNow commands: Schedulers send
PollNowto trigger immediate work polling on executors when new tasks are available, reducing scheduling latency from the poll interval (100ms) to near-zero. - Task cancellation: Schedulers route cancellation requests through the control stream rather than requiring a separate RPC.
- Metrics requests: Schedulers request on-demand metrics from executors for observability.
- Partition updates: Schedulers push partition assignment changes (for distributed acceleration) to executors, with a callback handler that loads/unloads data partitions.
When a scheduler becomes unreachable, the executor reconnects with Fibonacci backoff (max 10 seconds). When new schedulers are discovered, the executor opens additional control streams automatically.
2. Remote Catalog and UDF Synchronization
The scheduler is the source of truth for table schemas and custom functions. When executors join the cluster, they automatically receive the full catalog and UDF registry via our ClusterService gRPC protocol (GetCatalog and GetFunctions RPCs). No manual registration, no configuration drift.
This means a single spicepod.yaml on the scheduler defines all datasets, models, and views for the entire cluster.
The current implementation is SQL-only: clients submit SQL and the scheduler handles all query planning. The catalog sync architecture is designed for a second phase where clients perform local query planning via DataFrame API or submit pre-planned Substrait queries. The RemoteTableProvider and RemoteScalarUDF stubs participate in planning but defer execution to the scheduler.
3. mTLS Cluster Security
Distributed communication includes highly privileged RPCs: GetAppDefinition (full cluster config), ExpandSecret (secret values from the scheduler's store), and Ballista's task dispatch protocol. These must be protected because a rogue process impersonating an executor could exfiltrate secrets and query data.
We implemented mandatory mutual TLS with strict port separation:
| Port | Visibility | Services | mTLS |
|---|---|---|---|
| 50051 | Public | Arrow Flight (user queries), OpenTelemetry | Optional |
| 8090 | Public | HTTP API (REST queries, health, status) | Optional |
| 9090 | Public | Prometheus metrics | No |
| 50052 | Internal | SchedulerGrpcServer, ClusterService | Required |
CLI tooling simplifies certificate management:
spice cluster tls init
spice cluster tls add scheduler1
spice cluster tls add executor1 --host executor1.cluster.localFor development and testing, --allow-insecure-connections disables the mTLS requirement. In production, all three certificate files (CA, node cert with SAN matching --node-advertise-address, and private key) are required.
4. Shuffle Backends
Spice supports three shuffle storage backends, configured via shuffle_location:
- Local disk (default): Writes shuffle data to the executor's local filesystem. Stock Ballista behavior, suitable for single-node or colocated deployments.
- In-memory: Keeps intermediate data in executor memory for lower latency. Falls back to remote Flight fetch when data isn't available locally.
- Object store (S3, Azure, GCS): Writes shuffle data to S3, Azure Blob Storage, or Google Cloud Storage, decoupling shuffle storage from executor local disks. Essential for cloud-native deployments where executors may be ephemeral.
5. Vortex Shuffle Format
As covered in Vortex at Spice AI, Vortex's encoding-aware compression extends into the shuffle layer. When enabled, the shuffle writer serializes intermediate data using Vortex IPC instead of Arrow IPC (which uses LZ4 frame compression). Vortex's adaptive per-column encoding produces smaller shuffle files, reducing network transfer and disk I/O between executors.
runtime:
params:
shuffle_format: vortex # or arrow_ipc (default)The shuffle format is transparent to query semantics. The Vortex shuffle path converts Arrow RecordBatches to Vortex arrays on write and back to Arrow on read. For in-memory shuffles, data stays in Vortex encoding between stages, eliminating the decompress-recompress cycle.
6. Custom Codec for Spice Extensions
Distributed execution requires serializing execution plans across the network. We built custom physical and logical codecs that handle Spice-specific plan nodes: UdtfExec (for vector_search, text_search, RRF), CayenneAccelerationExec, SchemaCastScanExec, and BytesProcessedExec.
Vortex scan plans survive this serialization boundary via protobuf support added in our DataFusion fork (see Vortex at Spice AI), so distributed queries against Cayenne tables work transparently.
7. Observability
All cluster metrics flow through OpenTelemetry with a pre-built Grafana dashboard. Metrics include node status, active tasks, task duration, shuffle sizes, scheduler count, and active executor count. The distributed task_history table provides a federated view of all query execution across the cluster.
Distributed Acceleration
Ballista distributes query execution, but the data still has to live somewhere. In a single-node Spice deployment, accelerated tables are local: one process owns all the data. Scaling to a cluster requires distributing the data itself across executors so that queries can be planned and executed against the partitions where data actually resides.
We built a full partition management system that coordinates which executor owns which partitions of an accelerated table, using the same object store state layer that powers scheduler HA.
How It Works
Partition discovery. When an accelerated table is configured with partition_by, the scheduler discovers the full set of partition values. If the partition expression has a statically known value set (e.g. bucket(N, col) produces 0..N-1), values are generated without querying the source. Otherwise, a SELECT DISTINCT is executed against the federated source to discover partition values dynamically.
Partition metadata in object store. Each table's partition state is stored as a JSON file at accelerations/partitions/{table}.json in the shared object store. This file contains the full list of PartitionMetadata entries, each recording the partition value (a map of column names to values, supporting composite keys like {"date": "2024-01-01", "region": "us-east"}), assigned executor IDs, and assignment timestamps.
Allocation with optimistic concurrency control (OCC). The scheduler's PartitionManager allocates unassigned partitions to executors using optimistic concurrency control, the same ETag-based conditional write pattern used for scheduler registration. A greedy allocation loop iterates unassigned partitions and assigns them to the requesting executor, up to a configurable max_partitions_per_executor soft limit. On ETag conflict (another scheduler allocated concurrently), it retries with Fibonacci backoff up to 5 attempts.
Executor selection for queries. When a distributed query hits a partitioned accelerated table, the planner needs to know which executors to send tasks to. The select_executors algorithm finds the minimal set of executors that cover all required partitions using a greedy set cover: it repeatedly picks the executor with the most coverage of remaining needed partitions, breaking ties by executor ID for determinism. If any required partition is unassigned, the query fails with a clear error rather than returning partial results.
Push-based partition updates. When the scheduler assigns or reassigns partitions, it pushes UpdatePartitions messages to the affected executors via the bidirectional control stream. The executor's PartitionUpdateHandler callback receives the new and removed partition maps and loads or unloads data accordingly without polling or stale state.
Write-through forwarding. DML operations (INSERT, UPDATE, DELETE, MERGE INTO) on partitioned tables are forwarded to the correct executor based on partition assignment. The write-through layer inspects the incoming FlightData stream, evaluates partition expressions against the data's schema, and routes each batch to the executor that owns that partition via Arrow Flight do_put. This ensures writes are always co-located with the data.
Partition Management Cycle
The scheduler runs a periodic management task (configurable interval and discovery_timeout) that:
- Refreshes partition metadata from the object store
- Discovers new partition values from source tables
- Writes updated partition lists back to the object store
- Allocates unassigned partitions to available executors (up to
max_assignments_per_cycle) - Pushes partition updates to affected executors via control streams
This cycle means the system self-heals: if an executor goes down, its partitions become unassigned and are reallocated on the next cycle. New executors joining the cluster automatically receive partition assignments.
What This Enables
Ballista distributes query execution. The partition management layer extends that to the data itself, so queries are planned and dispatched against the executors where data actually lives. Each executor materializes and serves only its assigned partitions, and writes are routed to the correct executor. The result is a horizontally scaled acceleration layer where adding executors increases both query capacity and data capacity proportionally.
Use Case: Distributed Embeddings
A concrete application of distributed query is scaling embedding generation with the built-in embed() UDF. In single-node mode, embedding large datasets is bottlenecked by one process. In distributed mode, the query planner captures embedding model requirements during planning and pushes EnsureRuntimeDependencyExec nodes to executors, which instantiate the model on demand:
SELECT review_id, embed(review_headline, 'potion_2m') FROM amazon_reviews;Each executor processes its assigned partitions in parallel, generates embeddings locally, and shuffles the results back. The embedding model (potion_2m in this example) is defined once in the spicepod.yaml and distributed to executors automatically via the catalog sync protocol.
On a ~100k-row Amazon Reviews dataset, the Spice cluster completed distributed embedding in 9.8 seconds (48 cores, 24GB RAM). The equivalent Spark job, which requires a custom PySpark UDF wrapping model2vec and manual model distribution, took 17 seconds on 48 cores with 192GB RAM.
This pattern generalizes to any compute-heavy UDF: the distributed planner handles parallelization and data movement, while the UDF itself remains a single-node implementation.
Configuration: Simple by Default, Powerful When Needed
See the distributed query documentation for the full configuration reference.
Single-Node (unchanged)
spicedDistributed Cluster
# Scheduler
spiced --role scheduler \
--node-mtls-ca-certificate-file ca.crt \
--node-mtls-certificate-file scheduler.crt \
--node-mtls-key-file scheduler.key
# Executor (role inferred from --scheduler-address)
spiced --scheduler-address spiced://scheduler:50052 \
--node-mtls-ca-certificate-file ca.crt \
--node-mtls-certificate-file executor.crt \
--node-mtls-key-file executor.keyHA Cluster with Object Store
runtime:
scheduler:
state_location: s3://my-bucket/spice-cluster
params:
shuffle_format: vortex
shuffle_location: s3://my-bucket/shuffle-data
datasets:
- from: s3://warehouse/events
name: events
acceleration:
enabled: true
engine: cayenne
mode: file
refresh_mode: append
retention_sql: |
DELETE FROM events WHERE created_at < NOW() - INTERVAL '30 days'Business Value
For Data Engineers
The transition to distributed mode requires no query rewrites. The same SQL and spicepod.yaml configurations are shared across single-node and cluster deployments. Adding --role scheduler and --scheduler-address is the only change. Failed stages retry from intermediate shuffle data rather than restarting from scratch, which matters for multi-hour analytical jobs.
For Platform Teams
Scheduler HA runs entirely through object store conditional writes, without needing to operate etcd, ZooKeeper, or Redis. All cluster communication is secured with mTLS by default, with CLI-generated certificates. Full OpenTelemetry integration and a pre-built Grafana dashboard cover cluster health and task metrics.
For Teams Evaluating Spark or Trino
Early benchmarks show the Spice cluster running 7.7x faster than Spark while using 8x less RAM, a consequence of Rust and Arrow eliminating JVM overhead and garbage collection pauses. The platform is built on Apache DataFusion (top-5 Apache project), Apache Ballista (ASF governance), and Vortex (Linux Foundation), all under open source governance. Adoption is incremental: start single-node with the same binary and configuration format, then scale to a cluster when needed.
What's Next
We're continuing to push forward on distributed query capabilities:
- Distributed acceleration with Arrow and Cayenne: Extending partition management to Arrow and Cayenne, Spice's premier acceleration engines
- Substrait plan submission: Enabling client-side query planning with cross-language plan portability
- Adaptive query execution: Dynamic partition coalescing and stage retries based on runtime statistics
- Upstream contributions: Working to contribute our Ballista extensions (mTLS, object store shuffle, in-memory shuffle) back to the Apache project
The Ballista integration is available in Spice.ai v2.0+. Try the distributed query quickstart or explore the Cayenne accelerator documentation.
Spice.ai is open source at github.com/spiceai/spiceai. Our Ballista fork is at github.com/spiceai/datafusion-ballista. The architecture decisions behind these choices are recorded in our ADRs.
Apache Ballista at Spice AI FAQ
What is Apache Ballista and why does Spice AI use it?
Apache Ballista is a distributed query execution framework built on Apache DataFusion and Apache Arrow. Spice AI uses Ballista because it provides a mature scheduler-executor model, disk-based fault-tolerant shuffle, and native DataFusion integration. These capabilities would have taken 6-12+ months to build from scratch.
How does distributed mode differ from single-node Spice?
Single-node Spice handles sub-second real-time queries with local data acceleration. Distributed mode targets throughput and scale for batch and analytical workloads (seconds to minutes) by splitting query execution across a fleet of executors. The same SQL, spicepod.yaml, and APIs work in both modes. Adding --role scheduler and --scheduler-address flags is the only change.
How does Spice achieve high availability without etcd or ZooKeeper?
Spice schedulers coordinate through object store conditional writes (S3, Azure Blob, or local filesystem) using optimistic concurrency control with ETag-based versioning. Each scheduler registers, heartbeats, and discovers peers via a shared state directory in the object store, removing the need for external coordination infrastructure.
What is distributed acceleration and how does partition management work?
Distributed acceleration assigns partitions of accelerated tables to specific executors so queries run against data where it lives. The scheduler discovers partitions, allocates them to executors via optimistic concurrency control, and pushes updates through bidirectional control streams. If an executor goes down, its partitions are automatically reassigned on the next management cycle.
How does distributed embedding work with the embed() UDF?
The query planner captures embedding model requirements during planning and pushes them to executors, which instantiate the model on demand. Each executor processes its assigned partitions in parallel, generates embeddings locally, and shuffles results back, all within a single SQL statement. This pattern generalizes to any compute-heavy UDF.
How does Spice compare to Apache Spark for distributed queries?
Early benchmarks show a Spice cluster running 7.7x faster than Spark on Databricks while using 8x less RAM, a consequence of Rust and Arrow eliminating JVM overhead and garbage collection pauses. Spice also provides a simpler operational model: a single binary, declarative YAML configuration, and built-in mTLS, compared to Spark's JVM-based ecosystem and external cluster managers.