2025 Spice AI Year in Review
Spice AI

Wyatt Wenzel
DevRel & Ops Leader at Spice AIJanuary 2, 2026
In January 2025, Spice announced 1.0 stable, marking the transition from an open-source project to an enterprise-grade, production-ready platform. Spice has shipped 35 stable releases and 11 major releases since then.
From day one, Spice was designed to simplify building modern, intelligent applications. In 2025 that vision turned into reality. Spice now serves as the data and AI substrate for global, production workloads at enterprises like Twilio and Barracuda - where mission-critical applications query, search, and reason over big data in real time.
These data and AI workloads impose fundamentally different demands on the data layer than previous generations of applications. Instead of the complexity of multiple query engines, search platforms, caches, and inference layers, Spice brings this functionality into a single, high-performance data and AI stack. Development teams can query operational databases, data lakes, analytical warehouses, and more with a single SQL interface, while taking advantage of built-in acceleration, hybrid search, and AI.
All of this is delivered by a fully open-source engine built in Rust that can be deployed anywhere - as a sidecar, at the edge, in the cloud, or in enterprise clusters. Developers have complete optionality based on their access patterns and business requirements.
Below are some of the major features that defined 2025 across the core pillars of the Spice platform: federation and acceleration, search, and embedded LLM inference.
Major 2025 Federation & Acceleration Features
SQL federation and acceleration is at the core of Spice and the applications it enables; enterprise AI applications depend on contextual data drawn from many different systems, and that data must be fast and available to search and reason over in real time.
In 2025, Spice simplified querying across disparate data sources while improving performance, scale, and reliability. The connector ecosystem also significantly expanded, enabling teams to ingest and combine data across any source.
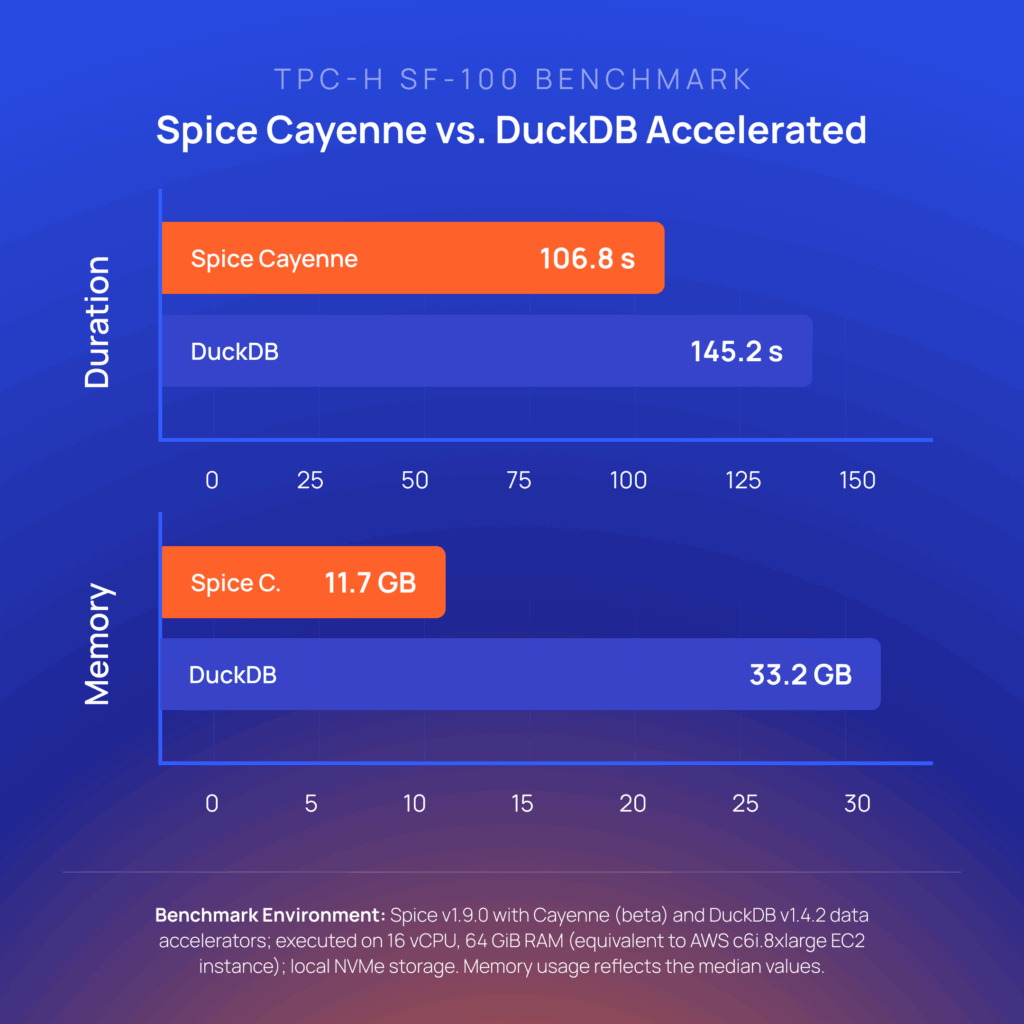
- Spice Cayenne data accelerator: Introduced in v1.9, Spice Cayenne is the new premier data accelerators built on the Vortex columnar format that enables low-latency, highly concurrent queries over large datasets, overcoming the scalability and memory limits of single-file accelerators like DuckDB.
- Iceberg and Amazon S3 writes: Spice added write support for Iceberg tables (v1.8) and Amazon S3 Tables (1.10), delivering direct ingestion, transformation, and materialization of data into object storage. This simplifies writing operational data to object-stores, eliminating the need for complex and costly batch or streaming pipelines.
- Multi-node distributed query (preview): v1.9 brought multi-node distributed query execution based on Apache Ballista, designed for querying partitioned data lake formats across multiple execution nodes for significantly improved query performance on large datasets.
- Managed acceleration snapshots: Acceleration Snapshots enable faster restarts, shared accelerations across multiple Spice instances, reduced load on federated systems, and continued query serving even when source systems are temporarily unavailable for enterprise-grade resiliency.
- Caching acceleration mode: A new caching mode introduced in v1.10 provides stale-while-revalidate (SWR) behavior for accelerations with background refreshes, and file-persistence with Spice Cayenne, SQLite, or DuckDB.
- Expanded connector ecosystem: Delta Lake, S3, Databricks, Unity Catalog, AWS Glue, PostgreSQL, MySQL, Kafka, DynamoDB, Kafka, MongoDB, Iceberg and more were introduced or reached stable.
Federation & Acceleration Feature Highlight: Spice Cayenne
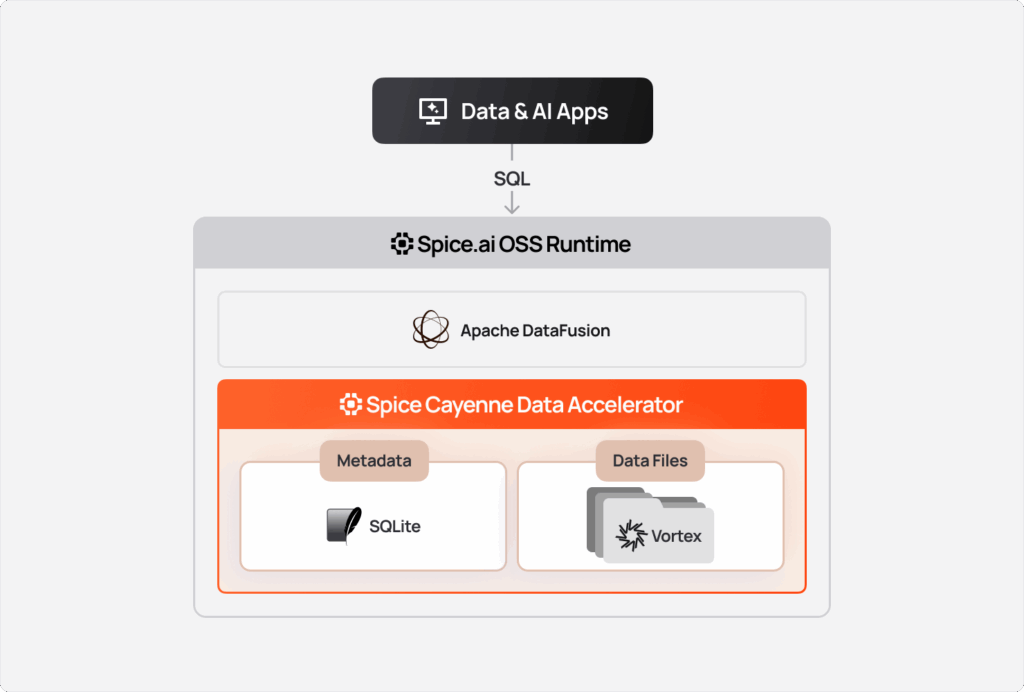
Spice leans into the industry shift to object storage as the source of truth for applications. These workloads are often multi-terabyte datasets using open data lake formats like Parquet, Iceberg, or Delta that must serve data and search queries to applications with sub-second performance.
Existing data accelerators like DuckDB, are fast and simple for datasets up to 1TB, however for multi-terabyte workloads, a new class of accelerator is required.
So we built Spice Cayenne, the next-generation data accelerator for high volume and latency-sensitive applications.
Spice Cayenne combines Vortex, the next-generation columnar file format from the Linux Foundation, with a simple, embedded metadata layer. This separation of concerns ensures that both the storage and metadata layers are fully optimized for what each does best. Cayenne delivers better performance and lower memory consumption than the existing DuckDB, Arrow, SQLite, and PostgreSQL data accelerators.
Spice Founder Luke Kim demonstrated and walked through the details of the Cayenne architecture in a December, 2025 Community Call:
Major 2025 Search Features
AI applications are only as effective as the data they can retrieve and reason over. Beyond extracting data, they need to search across both structured and unstructured sources to surface the most relevant context at query time. In 2025, search evolved into a core primitive of the Spice platform, designed to operate natively across federated datasets.
- Native Amazon S3 vectors integration: v1.5 added native support for Amazon S3 Vectors, making cost‑effective vector search on object storage a first‑class feature. Subsequent releases introduced multi-index scatter-gather, multi-column primary keys, and partitioned indexes to support scalable production workloads.
- Reciprocal Rank Fusion (RRF): Introduced in v1.7, RRF combines vector and full-text search results with configurable weighting and recency bias by a simple SQL table-function, producing higher-quality hybrid search rankings than either approach alone.
- Search on views (full-text and vector): Search on views enables advanced search scenarios across different search modalities over pre-aggregated or transformed data, extending the power of Spice's search functionality beyond base datasets.
- Search results caching: Runtime caching for search results improves performance for subsequent searches and chat completion requests that use the document_similarity LLM tool.
- Table‑level search enhancements: v1.8.2 added
additional_columnsandwheresupport for table relations in search, enabling multi‑table search workflows.
Search Feature Highlight: Amazon S3 Vectors
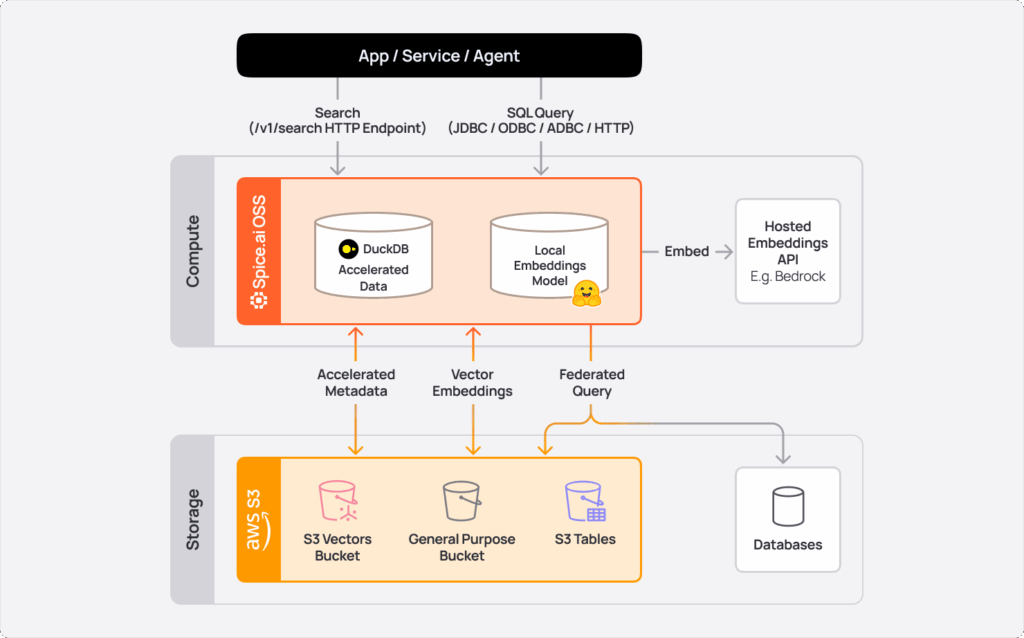
In July, Spice introduced native support for Amazon S3 Vectors as a day 1 launch partner at the AWS Summit in NYC. Vector similarity search, structured filters, joins, and aggregations can now be executed in SQL within Spice without duplicating data.
Developers can make vector searches using SQL or HTTP and combine similarity search with relational predicates and joins. Spice pushes filters down to S3 Vectors to minimize data scanned, delivering scalable sub-second query performance with the flexibility of SQL.
The Spice team presented a live demo of Spice and Amazon S3 Vectors at 2025 AWS re:Invent:
Major AI Features Released in 2025
Spice deepened its AI capabilities by making LLM inference via SQL native within the query engine. LLMs can be invoked directly in SQL alongside federated queries, joins, and transformations, helping teams move from raw data to insights all within SQL.
- AI SQL function: The AI SQL function was introduced in v1.8, supporting LLM calls directly from SQL for generation, translation and classification. Model inference can now run in the same execution path as joins, filters, search, and aggregations.
- MCP server support: Introduced in v1.1, Spice works as both an MCP server and client. Spice can run stdio-based MCP tools internally or connect to external MCP servers over HTTP SSE and streaming.
- Amazon Nova & Nova 2 embeddings: Support for models like Nova (v1.5.2) and Nova 2 multimodal embeddings (v1.9.1), which support high-dimensional vector representations with configurable truncation modes.
- Expanded model provider ecosystem: Spice added support for new providers including Anthropic, xAI, HuggingFace, Amazon Bedrock, Model2Vec static models, and more.
- Expanded tools ecosystem: Added native tool integrations including the OpenAI Responses API (for streaming tool calls and responses) and a Web Search tool powered by Perplexity. These tools can be invoked within the same execution context as SQL queries and model inference, enabling retrieval-augmented and agent-style workflows without external orchestration.
AI Feature Highlight: AI SQL Function
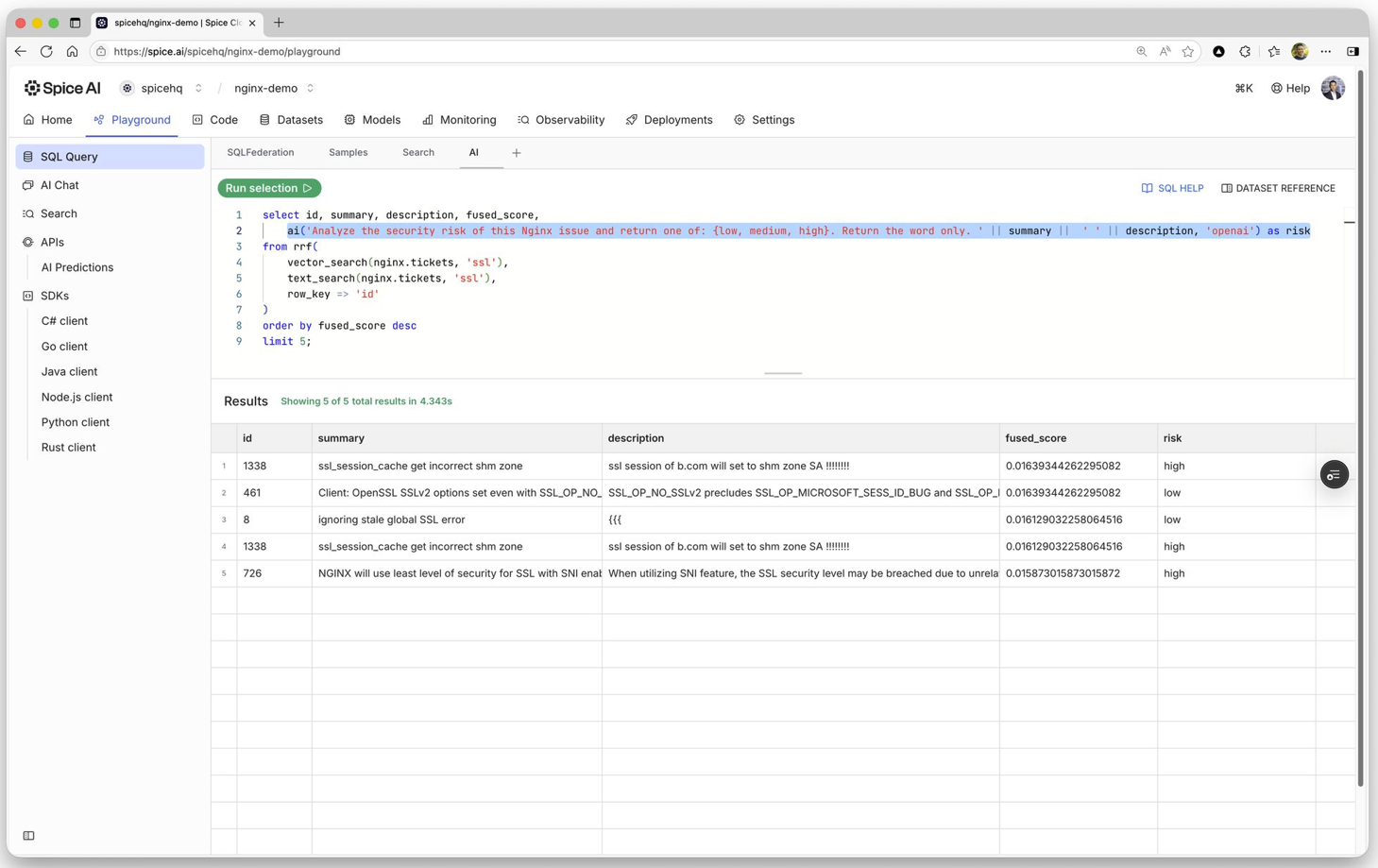
The ai() SQL function enables developers to invoke LLMs directly within SQL for bulk generation, classification, translation, or analysis. Inference runs alongside joins, filters, aggregations, and search results without additional application-layer plumbing. Developers can transform federated data into structured insights extracting data, call external completion APIs, or orchestrate separate pipelines.
Check out a live demo of the AI SQL function here:
Looking ahead
2025 was a major year for Spice as it grew from single-node data acceleration to a multi-node data, search, and AI platform. In 2026, Spice 2.0 will focus on bringing multi-node distributed query execution to GA, alongside continued improvements to search, acceleration, and AI primitives. These investments will help deliver even more predictable performance and operational simplicity.
The mission remains the same: to provide a durable, open data substrate that helps teams build and scale the next generation of intelligent, data and AI-driven applications.
Interested in seeing it for yourself? Get started with the open source runtime, explore pricing, or try the cloud platform today.
Frequently Asked Questions
What is Spice.ai?
Spice.ai is a portable, open-source data and AI compute engine built in Rust. It provides SQL federation and acceleration, hybrid search, and LLM inference in a single runtime that can be deployed anywhere from edge to cloud.
What were the biggest Spice releases in 2025?
Spice shipped 35 stable releases and 11 major releases in 2025. Key milestones included the 1.0-stable production release, the Spice Cayenne data accelerator built on the Vortex columnar format, native Amazon S3 Vectors integration, multi-node distributed query execution, and the AI SQL function for invoking LLMs directly from SQL.
How does Spice compare to a traditional data warehouse?
Unlike centralized data warehouses that require data movement, Spice federates queries across databases, data lakes, and warehouses in place. It materializes working sets locally for sub-millisecond performance and is designed for application serving rather than batch analytics. See pricing for deployment options.
See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer