Spice Cloud v1.7.0: DataFusion v49, Full-Text Search Updates & More
Spice Cloud

Wyatt Wenzel
DevRel & Ops Leader at Spice AISeptember 24, 2025
Spice Cloud & Spice.ai Enterprise 1.7.0 are now live, bringing performance upgrades with DataFusion v49, real-time full-text search indexing, EmbeddingGemma support, and improvements across search, embeddings, and API integrations. Spice Cloud customers will automatically upgrade to v1.7.0 on deployment, while Spice.ai Enterprise customers can consume the Enterprise v1.7.0 image from the Spice AWS Marketplace listing.
What's New in Spice Cloud v1.7.0
DataFusion v49 Upgrade
Spice now runs on DataFusion v49, delivering lower latency and improved query optimization.
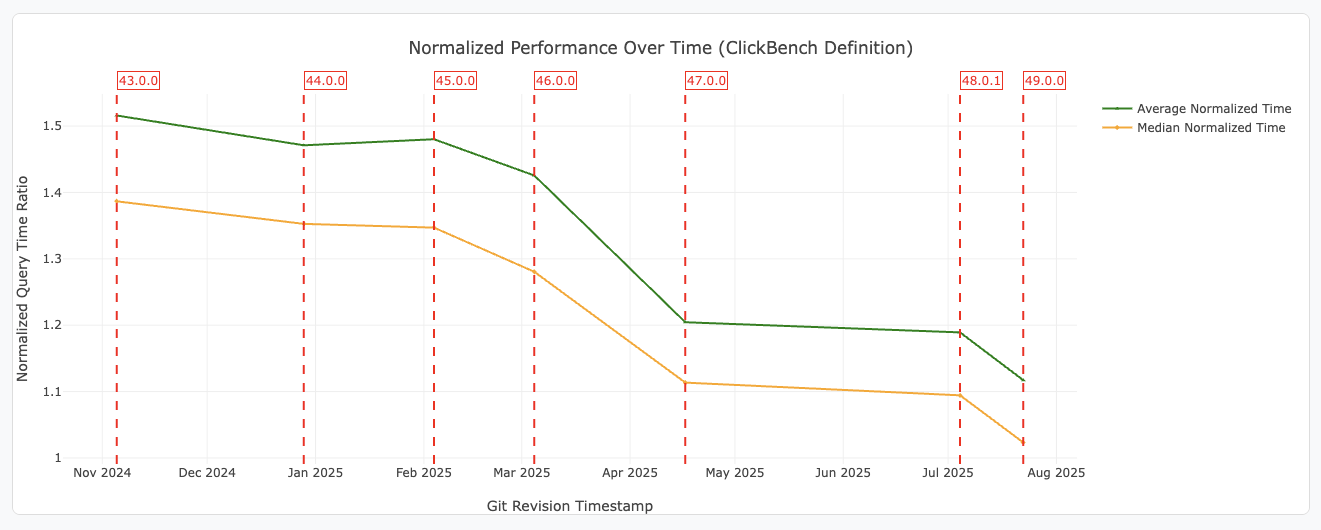
DataFusion v49 highlights include:
- Dynamic filters and pushdown to skip unnecessary reads in
ORDER BY & LIMITqueries - Compressed spill files to reduce disk usage during large sorts and aggregations
- Support for ordered-set aggregates with
WITHIN GROUP - New
REGEXP_INSTRfunction to identify regex match positions
EmbeddingGemma Support
Spice now supports EmbeddingGemma, Google's latest embedding model for text and documents. It delivers high-quality embeddings for semantic search, retrieval, and recommendation tasks. Configure it directly in your Spicepod via HuggingFace.
Embedding Request Caching
Repeated embedding requests can now be cached in the Spice runtime. This reduces both latency and costs, with configurable cache size and TTL options. Check out the caching documentation for more details.
Real-Time Indexing for Full Text Search
Full-text indexing now supports real-time changes from CDC streams such as Debezium. New events are searchable as they arrive, ensuring continuously fresh results.
OpenAI Responses API Tool Calls with Streaming
The OpenAI Responses API in Spice now supports tool calls with streaming. Results from tools like web_search and code_interpreter are streamed as they're generated, enabling more responsive agent and application experiences.
Bug & Stability Fixes
v1.7.0 includes numerous fixes and improvements:
- CDC streams readiness and full-text indexing reliability
- Vector search pipeline and
vector_searchUDTF fixes - Kafka schema inference, consumer group persistence, and cooperative mode
- Error reporting improvements (e.g., ThrottlingException handling)
- Iceberg connector support for
LIMITpushdown - S3 Vector ingestion reliability and tracing fixes
v1.7 Release Community Call
We'll walk through highlights of v1.7 live on our Release Community Call. Join us to see the new functionality in action and bring your questions! Register here.
.png)
To get started with Spice Cloud v1.7.0, review vCPU-based pricing plans or get a demo to see the new capabilities live.
See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer