Real-time SQL
query for agents
Give agents secure, physically isolated access to operational, analytical, and streaming data. Open source and deployable anywhere.
Deployed in production by global enterprises
Make your data AI-ready
Sub-second query performance across sources, up to 80% lower lakehouse spend, and increased data redundancy.
0x
Up to 100x faster queries
0%
up to 80% cost savings on data lakehouse spend
0x
increase in data reliability for critical workloads
Ground apps and AI agents in enterprise data
Query, accelerate, search, and integrate AI across your data estate with zero ETL.
Fast and federated access to all of your data
Connect to and query operational databases, data lakes, and warehouses across the enterprise. Materialize and accelerate working sets in-memory or on disk for millisecond access.
Learn more

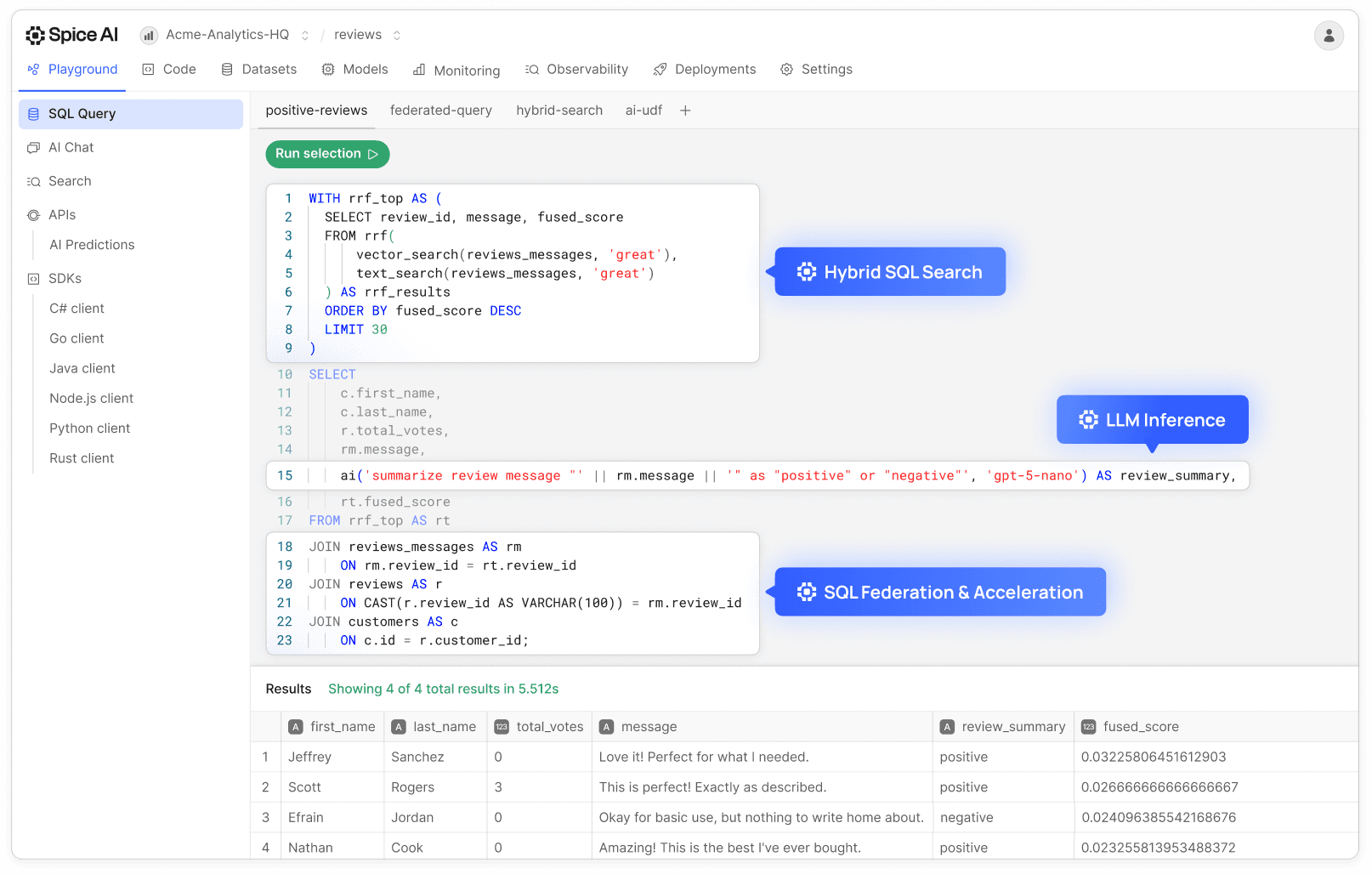
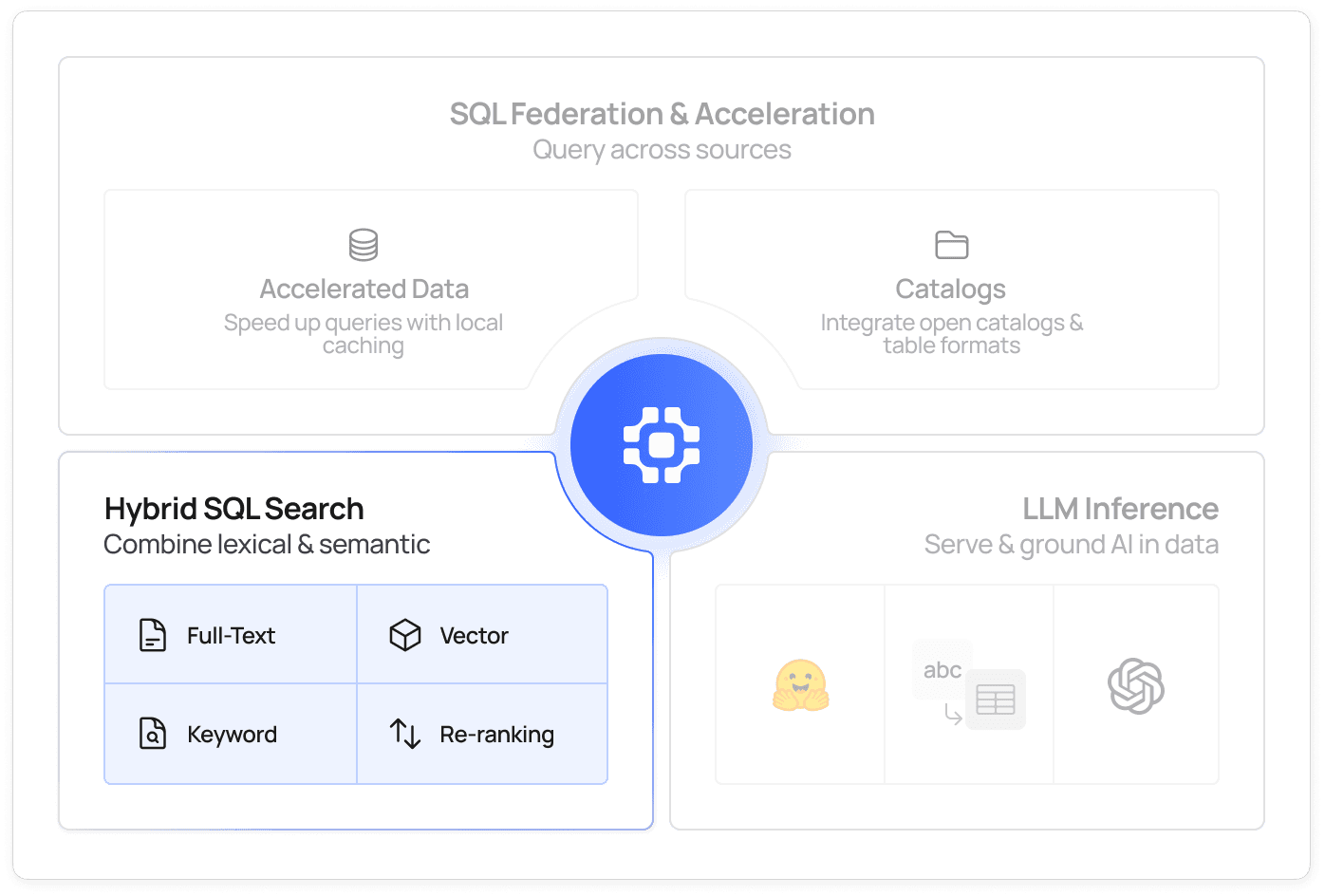
Combine keyword, vector, and full-text search in SQL
Use standard SQL to power hybrid search pipelines and deliver fast and context-aware results for search-driven apps. Rank structured filters, semantic similarity, and keyword matches to optimize relevance and robustness in your search results.
Learn more
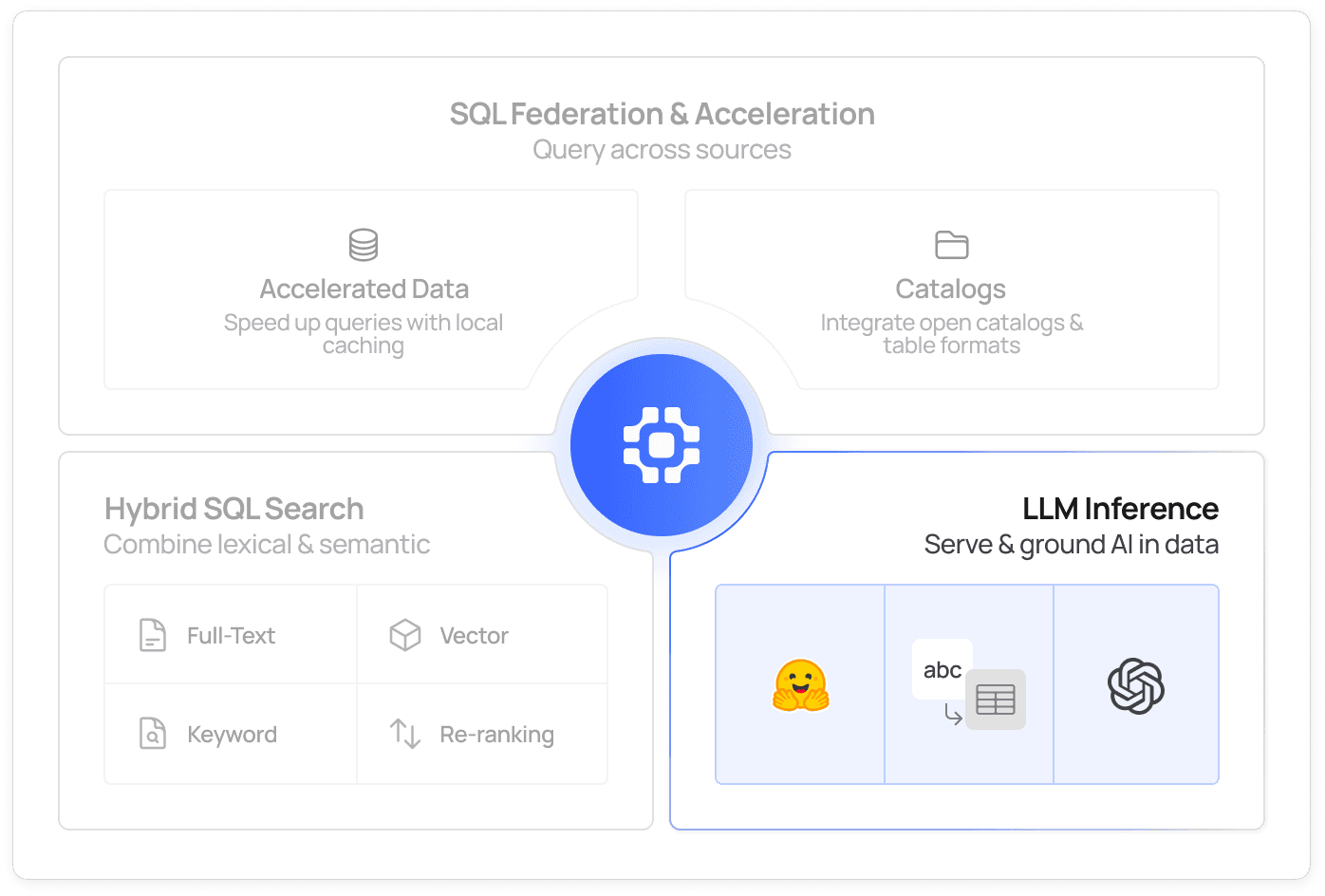
Call LLMs directly from the query layer
Call hosted or local LLMs inline using SQL UDFs or natural language. Translate text, generate summaries, classify entities, and augment query results on your enterprise data without leaving the Spice runtime.
Learn more
Control and optionality at every layer
Enable real-time, AI-driven apps on top of your existing data with the trust and scalability enterprises demand.

Deploy
anywhere
Run Spice.ai Open Source locally, at the edge, or on the fully managed Spice.ai Cloud Platform. Lightweight, portable, and designed for scale.
Learn more

AI sandboxing
& security
Provision isolated, least-privilege datasets for apps and agents with zero direct database access. Keep governance intact while enabling RAG, agents, and AI workflows.
Learn more

Distributed
observability
Perform end-to-end tracing across SQL, embeddings, search, and LLM calls. Debug, measure latency, and prove ROI from a single view.
Learn more
Proven in production
From messaging platforms to security systems, companies like Twilio and Barracuda rely on Spice to deliver low-latency apps & AI agents at scale.




“Spice opened the door to take these critical control-plane datasets and move them next to our services in the runtime path.”
Peter Janovsky
Software Architect, Twilio

0x
Faster queries
“It just spins up and works, which is really nice. The responsiveness is amazing, which is a huge gain for the customer.”
Darin Douglass
Principal Software Engineer, Barracuda

“Partnering with Spice AI has transformed how NRC Health delivers AI-driven insights. By unifying siloed data across systems, we accelerated AI feature development, reducing time-to-market from months to weeks - and sometimes days. With predictable costs and faster innovation, Spice isn't just solving some of our data and AI challenges - it's helping us redefine personalized healthcare.”
Tim Ottersburg
VP of Technology, NRC Health

“Spice AI grounds AI in our actual data, using SQL queries across many data sources. This brings accuracy to probabilistic AI systems, which are very prone to hallucinations.”
Rachel Wong
CTO, Basis Set
Get started with Spice
Explore guides and examples that show how to query data, build apps, and integrate AI in minutes.
Spice.ai OSS Documentation
Visit the Spice open-source docs to learn how Spice works under the hood.

Spice.ai OSS Cookbook
Over 80 guides and samples to help you build data-grounded AI apps and agents with Spice.

Product Demos
Hands-on product demos to accelerate your learning with Spice.

See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer