Getting Started with Spice.ai SQL Query Federation & Acceleration
Spice AI

Wyatt Wenzel
DevRel & Ops Leader at Spice AIOctober 14, 2025
TL;DR: Spice provides SQL query federation and local acceleration in a lightweight runtime that lets applications query distributed data sources (databases, warehouses, and lakes) through a single SQL interface with sub-second performance, zero ETL, and no data movement.
Modern applications succeed when they can deliver speed, intelligence, and reliability at scale. Achieving that depends increasingly on how quickly and efficiently they can access the relevant underlying data sources. Most enterprises, however, rely on pipelines, warehouses, and APIs that make real-time or intelligent apps prohibitively expensive or slow. Engineering teams are faced with how to make these fragmented systems faster, more secure, and more productive without rebuilding from scratch. Spice was built to solve this problem, delivering SQL query federation and local acceleration in a lightweight, portable runtime that turns distributed data environments into a high-performance data layer capable of supporting the most demanding workloads.
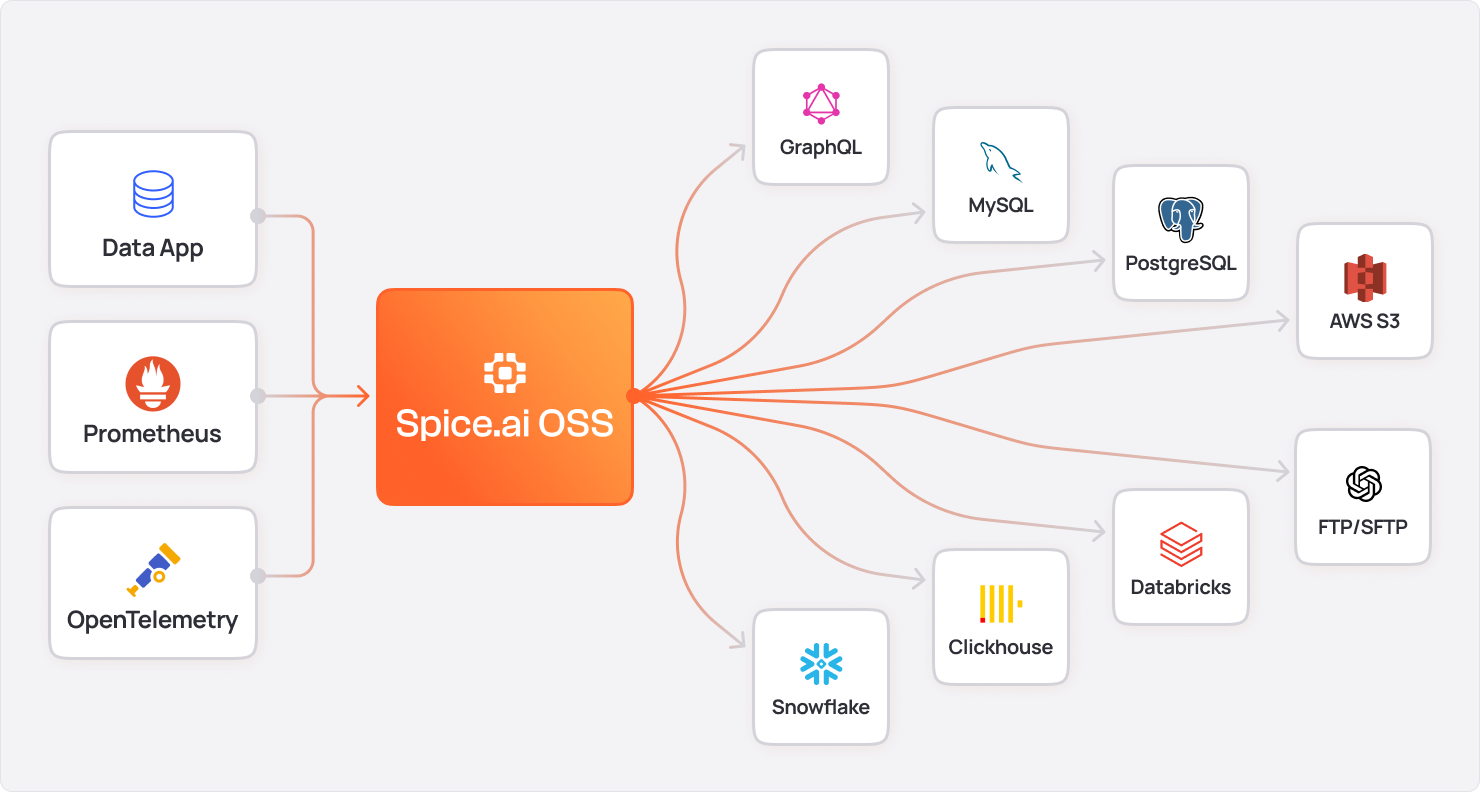
The Current State of Data Access in the Enterprise
The primary mandate for development teams is satisfying the performance, availability, and security benchmarks your use case mandates at a cost profile that makes sense for your business; how you satisfy those requirements in terms of the underlying technology deployed is ultimately an implementation detail.
It's evident that this philosophy is put into practice when you take a peek behind the 'enterprise curtain', where you'll see a patchwork of different systems deployed at different layers of abstraction: operational and analytical apps built on on-premise, cloud, hybrid, or serverless infrastructure depending on the use case.
In order to make these very heterogenous architectures operational, historically (largely by necessity) development teams would have to patch together a variety of pipelines to connect to data spread out across the enterprise: customer records in transactional databases, historical data in warehouses or data lakes, semi-structured content in object stores, etc. All across a variety of deployment tiers.
How can you make your existing infrastructure investment more productive, secure, and performant, while also serving the low-latency data access that intelligent applications and agents demand? Copying everything into a single warehouse no longer satisfies the performance, security, or cost requirements of modern workloads.
How Spice's SQL Federation & Acceleration Solves the Data Access Problem
Spice is an open-source data and AI platform that federates and accelerates your operational and analytical data and deploys it at the application layer. Instead of centralizing all data in one system, it lets teams query data in place across multiple sources in a lightweight runtime that runs anywhere - edge, cloud, or on-prem.
- SQL Query Federation: Run SQL queries across OLTP databases, OLAP warehouses, and object stores without ETL.
SQL Query Acceleration: Cache or index working sets locally in DuckDB or SQLite, cutting query latency from seconds to milliseconds.
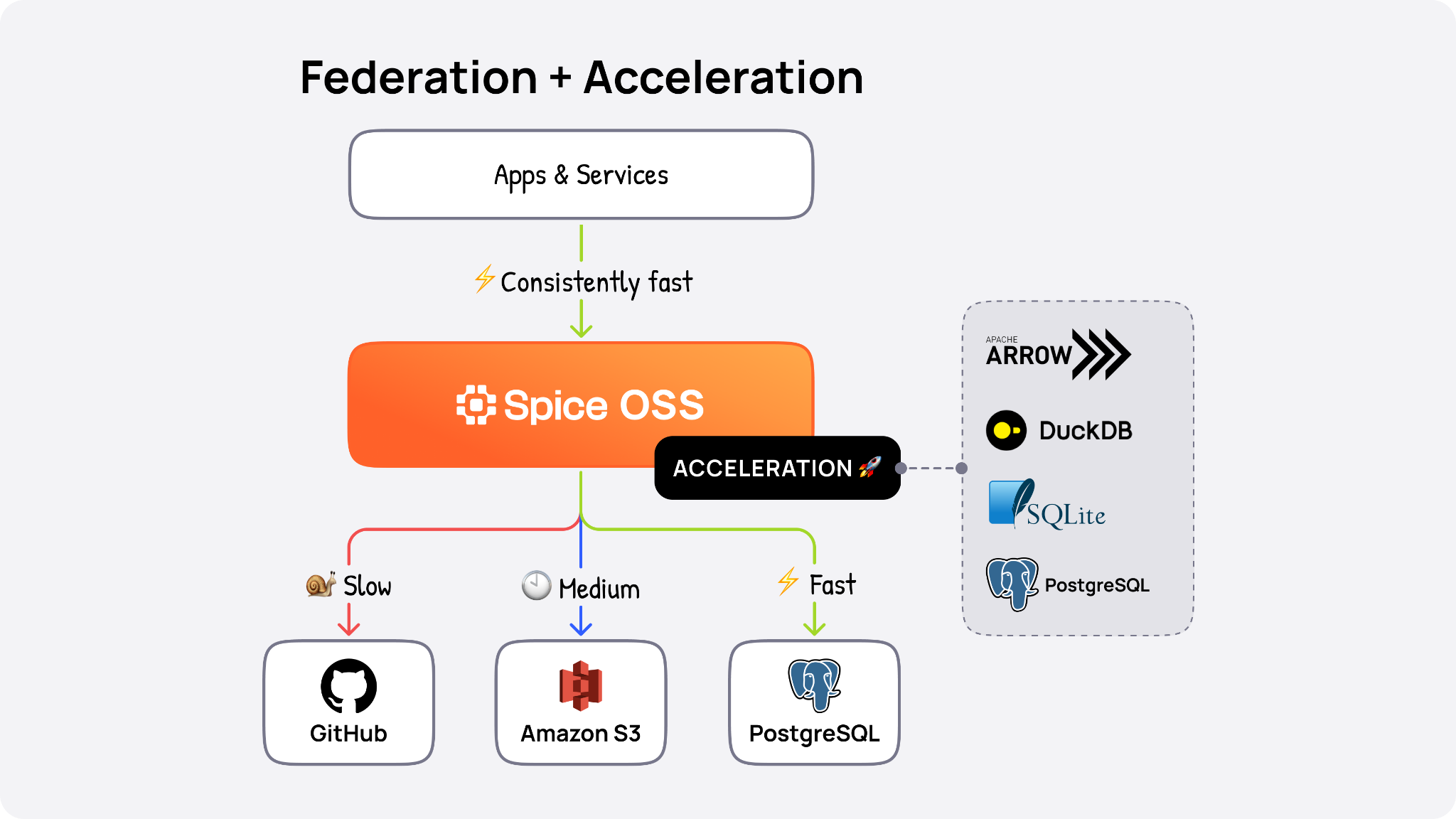
By combining SQL federation and acceleration in a single runtime, Spice reduces infrastructure complexity and delivers the sub-second latency needed for real-time apps and AI agents - whereas traditional approaches rely on heavy ETL pipelines or pre-aggregations to make object storage and open table formats queryable. And for use cases that demand search, Spice packages keyword, vector, and full-text search in one SQL query for truly hybrid retrieval.
This breadth of capabilities brings object storage fully into the operational path; Spice turns object storage into active, queryable data layers that support real-time ingestion, transformation, and retrieval. You can query data where it lives, ingest real-time updates through change-data-capture (CDC), index for vector and full-text search, and write directly back to Iceberg tables using standard SQL.
Use Case Example: Combining S3, PostgreSQL, and Dremio Data in Single Query
Consider a customer portal that needs to show per-customer delivery stats in real time, which for this use case means joining customer orders in S3 with trip data stored in Dremio. With a traditional pipeline, this would require duplicating data into a warehouse, incurring both cost and latency.
Spice, conversely, federates and accelerates that data locally. Here's what it looks like in practice (which you can validate for yourself in the next section):
- Raw S3 query (~2,800 rows): 0.87s
- Accelerated S3 query with Spice: 0.02s (40x faster)
- Raw Dremio query (100,000 rows): 2.67s
- Accelerated Dremio query with Spice: 0.01s (250x faster)
- Federated aggregation across both: 0.009s
This performance delta transforms multi-system queries from a batch job into something fast enough for an interactive app.
Cookbook: How To Run It Yourself
Watch the video and follow along with the cookbook below to see how to fetch combined data from S3 Parquet, PostgreSQL, and Dremio in a single query.
Follow these steps to use Spice to federate SQL queries across data sources
Step 1. Clone the github.com/spiceai/cookbook repo and navigate to the federation directory.
git clone https://github.com/spiceai/cookbook
cd cookbook/federationStep 2. Initialize the Spice app. Use the default name by pressing enter when prompted.
spice init
name: (federation)?Step 3. Log into the demo Dremio instance. Ensure this command is run in the federation directory.
spice login dremio -u demo -p demo1234Step 4. Add the spiceai/fed-demo Spicepod from spicerack.org.
spice add spiceai/fed-demoStep 5. Start the Spice runtime.
spice run
2025/01/27 11:36:41 INFO Checking for latest Spice runtime release...
2025/01/27 11:36:42 INFO Spice.ai runtime starting...
2025-01-27T19:36:43.199530Z INFO runtime::init::dataset: Initializing dataset dremio_source
2025-01-27T19:36:43.199589Z INFO runtime::init::dataset: Initializing dataset s3_source
2025-01-27T19:36:43.199709Z INFO runtime::init::dataset: Initializing dataset dremio_source_accelerated
2025-01-27T19:36:43.199537Z INFO runtime::init::dataset: Initializing dataset s3_source_accelerated
2025-01-27T19:36:43.201310Z INFO runtime::flight: Spice Runtime Flight listening on 127.0.0.1:50051
2025-01-27T19:36:43.201625Z INFO runtime::metrics_server: Spice Runtime Metrics listening on 127.0.0.1:9090
2025-01-27T19:36:43.205435Z INFO runtime::http: Spice Runtime HTTP listening on 127.0.0.1:8090
2025-01-27T19:36:43.209349Z INFO runtime::opentelemetry: Spice Runtime OpenTelemetry listening on 127.0.0.1:50052
2025-01-27T19:36:43.401179Z INFO runtime::init::results_cache: Initialized results cache; max size: 128.00 MiB, item ttl: 1s
2025-01-27T19:36:43.624011Z INFO runtime::init::dataset: Dataset dremio_source_accelerated registered (dremio:datasets.taxi_trips), acceleration (arrow), results cache enabled.
2025-01-27T19:36:43.625619Z INFO runtime::accelerated_table::refresh_task: Loading data for dataset dremio_source_accelerated
2025-01-27T19:36:43.776300Z INFO runtime::init::dataset: Dataset dremio_source registered (dremio:datasets.taxi_trips), results cache enabled.
2025-01-27T19:36:44.182533Z INFO runtime::init::dataset: Dataset s3_source registered (s3://spiceai-demo-datasets/cleaned_sales_data.parquet), results cache enabled.
2025-01-27T19:36:44.203734Z INFO runtime::init::dataset: Dataset s3_source_accelerated registered (s3://spiceai-demo-datasets/cleaned_sales_data.parquet), acceleration (sqlite), results cache enabled.
2025-01-27T19:36:44.205146Z INFO runtime::accelerated_table::refresh_task: Loading data for dataset s3_source_accelerated
2025-01-27T19:36:45.138393Z INFO runtime::accelerated_table::refresh_task: Loaded 2,823 rows (1010.18 kiB) for dataset s3_source_accelerated in 933ms.
2025-01-27T19:36:46.313896Z INFO runtime::accelerated_table::refresh_task: Loaded 100,000 rows (27.91 MiB) for dataset dremio_source_accelerated in 2s 688ms.Step 6. In another terminal window, start the Spice SQL REPL and perform the following SQL queries:
spice sql
-- Query the federated S3 source
select * from s3_source;
+--------------+------------------+------------+-------------------+---------+---------------------+---------+---------+-------+------+--------------+------+--------------+--------------------+------------------+-------------------------------+---------------+-------+-------+-------------+---------+-----------+-------------------+--------------------+-----------+
| order_number | quantity_ordered | price_each | order_line_number | sales | order_date | status | quarter | month | year | product_line | msrp | product_code | customer_name | phone | address_line1 | address_line2 | city | state | postal_code | country | territory | contact_last_name | contact_first_name | deal_size |
+--------------+------------------+------------+-------------------+---------+---------------------+---------+---------+-------+------+--------------+------+--------------+--------------------+------------------+-------------------------------+---------------+-------+-------+-------------+---------+-----------+-------------------+--------------------+-----------+
| 10107 | 30 | 95.7 | 2 | 2871.0 | 2003-02-24T00:00:00 | Shipped | 1 | 2 | 2003 | Motorcycles | 95 | S10_1678 | Land of Toys Inc. | 2125557818 | 897 Long Airport Avenue | | NYC | NY | 10022 | USA | | Yu | Kwai | Small |
| 10121 | 34 | 81.35 | 5 | 2765.9 | 2003-05-07T00:00:00 | Shipped | 2 | 5 | 2003 | Motorcycles | 95 | S10_1678 | Reims Collectables | 26.47.1555 | 59 rue de l'Abbaye | | Reims | | 51100 | France | EMEA | Henriot | Paul | Small |
| 10134 | 41 | 94.74 | 2 | 3884.34 | 2003-07-01T00:00:00 | Shipped | 3 | 7 | 2003 | Motorcycles | 95 | S10_1678 | Lyon Souveniers | +33 1 46 62 7555 | 27 rue du Colonel Pierre Avia | | Paris | | 75508 | France | EMEA | Da Cunha | Daniel | Medium |
...
+--------------+------------------+------------+-------------------+---------+---------------------+---------+---------+-------+------+--------------+------+--------------+--------------------+------------------+-------------------------------+---------------+-------+-------+-------------+---------+-----------+-------------------+--------------------+-----------+
Time: 0.876282458 seconds. 500/2823 rows displayed.-- Query the accelerated S3 source
select * from s3_source_accelerated;Output:
+---------------------+-----------------+------------------+-------------+------------+--------------+
| pickup_datetime | passenger_count | trip_distance_mi | fare_amount | tip_amount | total_amount |
+---------------------+-----------------+------------------+-------------+------------+--------------+
| 2013-08-22T08:24:12 | 1 | 1.1 | 7.5 | 0.0 | 8.0 |
| 2013-08-21T12:40:46 | 1 | 6.1 | 23.0 | 0.0 | 23.5 |
| 2013-08-24T00:40:17 | 2 | 0.6 | 4.5 | 0.0 | 5.5 |
...
+---------------------+-----------------+------------------+-------------+------------+--------------+
Time: 0.015666208 seconds. 500/100000 rows displayed.
-- Perform an aggregation query that combines data from S3 and Dremio
WITH all_sales AS (
SELECT sales FROM s3_source_accelerated
UNION ALL
select fare_amount+tip_amount as sales from dremio_source_accelerated
)
SELECT SUM(sales) as total_sales,
COUNT(*) AS total_transactions,
MAX(sales) AS max_sale,
AVG(sales) AS avg_sale
FROM all_sales;Output:
+--------------------+--------------------+----------+--------------------+
| total_sales | total_transactions | max_sale | avg_sale |
+--------------------+--------------------+----------+--------------------+
| 11501140.079999998 | 102823 | 14082.8 | 111.85376890384445 |
+--------------------+--------------------+----------+--------------------+
Time: 0.009526666 seconds. 1 rows.Closing Thoughts
Federated SQL with Spice gives development teams a faster, simpler way to work with distributed data, and allows enterprises to accommodate modern access patterns on top of their existing infrastructure investment. By eliminating ETL bottlenecks and enabling low-latency queries across multiple systems, Spice delivers consistent, high-performance access to data wherever it lives.
Clone the cookbook repo and give Spice federation a try!
Getting Started with Spice
Spice is open source (Apache 2.0) and can be installed in less than a minute on macOS, Linux, or Windows, and also offers an enterprise-grade Cloud deployment.
- Explore the open source docs and blog
- Visit the getting started guide
- Explore the 75+ cookbooks
- Try Spice.ai Cloud for a fully managed deployment and get started for free.
Frequently Asked Questions
What is SQL query federation?
SQL query federation is the ability to execute a single SQL query across multiple data sources (databases, data warehouses, data lakes, and APIs) without moving the data first. Spice federates queries across 30+ connectors and returns results through a unified SQL interface, eliminating the need for ETL pipelines or data duplication.
How does data acceleration differ from caching?
Data acceleration materializes selected datasets into a local engine (Arrow, DuckDB, SQLite, or Cayenne) with configurable refresh policies, so queries always hit pre-loaded data. Traditional caching stores individual query results with TTL-based expiration. Acceleration provides consistent sub-millisecond performance for any query pattern against the accelerated dataset, not just previously executed queries.
Can Spice query data without moving it from the source?
Yes. Spice's federation layer pushes query predicates down to source systems and returns only the matching rows. For data that is queried frequently, you can optionally enable acceleration to materialize a local copy with automatic refresh. Both modes avoid traditional ETL: the data stays at the source or is managed declaratively by Spice.
What data sources does Spice support for federation?
Spice supports over 30 data connectors including PostgreSQL, MySQL, DynamoDB, Snowflake, Databricks, S3 (Parquet, Iceberg, Delta Lake), ClickHouse, Dremio, SharePoint, GitHub, and more. New connectors are added regularly. See the full list in the Spice documentation.
Federation also scales out: distributed query runs the same SQL across a multi-node cluster.
See Spice in action
Walk through your use case with an engineer and see how Spice handles federation, acceleration, and AI integration for production workloads.
Talk to an engineer